作者 观测云 产品服务部 技术经理 赵刚
一 前言
日志是系统中的重要数据来源之一,包含了丰富的信息,可以帮助我们更好地了解系统的运行状况和问题。本指南参照观测云文档(https://docs.guance.com/,以下简称官网文档)整理编写,旨在对初次使用观测云产品或计划系统性了解数据接入观测云的使用者更快、更好的理解官网文档中各类数据的接入。
二 适用范围
本指南适用于初次使用观测云产品的使用者,同时也适用于计划对观测云产品日志数据接入进行系统性了解的使用者。
三 定义和术语
本文提到的术语如下定义:
DataKit:观测云的数据采集组件。
DataWay:观测云的数据网关。
Kubernetes:本文简称K8S。
采集器:本文更多的是指Datakit。
采集模块:本文是指Datakit采集器中的各类数据源的采集配置。
观测云Studio:观测云UI界面控制台。
四 日志数据概述
4.1 Datakit内部架构

图1 DataKit内部架构
4.2 日志采集方式
如图1所示,Datakit对日志数据接入方式分如下几类:
日志文件采集:应用软件或业务程序的日志在程序开发时,将访问行为记录到文件存储。多见于传统应用或非云原生环境使用此方式记录日志。
Stdout采集:Stdout 是开发工程师写代码时,选择日志控制台的输出方式,多在K8S集群中使用此方式收集日志,如:
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
日志流采集:对采集日志IO要求高的场景应用多使用此方式进行日志收集,如Java 的 Springboot 应用中通过 Socket 采集日志,通过Logback 的 Socket 把日志传到 DataKit。
4.3 官网文档日志相关推荐
本文主要从4.2章节介绍的三大类日志采集进行接入介绍,为丰富其他日志使用场景玩法,以下汇总了一些可参考的文章。
DataKit 日志采集综述
https://docs.guance.com/datakit/datakit-logging/
Kubernetes 集群中日志采集的几种玩法
https://docs.guance.com/best-practices/cloud-native/k8s-logs/
Logback Socket 日志采集最佳实践
https://docs.guance.com/best-practices/cloud-native/logback-socket/
Kubernetes 下 StdOut 日志白名单最佳实践
https://docs.guance.com/best-practices/cloud-native/stdout-log/
五 日志接入步骤
整个日志的接入分三个阶段,首先是Datakit采集器的安装,其次是Datakit采集器中内置大量的数据源采集模块的配置调整,最后通过观测云Studio的日志查看器进行日志数据分析。以下选取典型的采集模块展开日志应用的接入,涵盖文件日志、Stdout日志和日志流等日志数据接入。
5.1 文件日志
- 采集器Datakit的安装
1、登陆官网(https://www.guance.com/)注册并登陆
2、根据下图选择适用于你的环境,进行安装采集器Datakit

- 采集模块配置
找到日志采集模块,如下路径
/usr/local/datakit/conf.d/log
cp logging.conf.sample logging.conf
vi logging.conf
配置说明:按软件输出的文件路径,填写到logging.conf的logfiles中,source和service建议填写,source一般按业务系统名、service为业务系统具有的服务分类。
需要注意的是:socket 和文件两种采集方式,目前只能选择其中之一,不能既通过文件采集,又通过 socket 采集。
[[inputs.logging]]
# 日志文件列表,可以指定绝对路径,支持使用 glob 规则进行批量指定
# 推荐使用绝对路径
logfiles = [
"/var/log/*", # 文件路径下所有文件
"/var/log/sys*", # 文件路径下所有以 sys 前缀的文件
"/var/log/syslog", # Unix 格式文件路径
"C:/path/space 空格中文路径/some.txt", # Windows 风格文件路径
"/var/log/*", # 文件路径下所有文件
"/var/log/sys*", # 文件路径下所有以 sys 前缀的文件
]
## socket 目前支持两种协议:tcp/udp。建议开启内网端口防止安全隐患
## socket 和 log 目前只能选择其中之一,不能既通过文件采集,又通过 socket 采集
#socket = [
# "tcp://0.0.0.0:9540"
# "udp://0.0.0.0:9541"
#]
# 文件路径过滤,使用 glob 规则,符合任意一条过滤条件将不会对该文件进行采集
ignore = [""]
# 数据来源,如果为空,则默认使用 'default'
source = ""
# 新增标记 tag,如果为空,则默认使用 $source
service = ""
# pipeline 脚本路径,如果为空将使用 $source.p,如果 $source.p 不存在将不使用 pipeline
pipeline = ""
# 过滤对应 status
# emerg,alert,critical,error,warning,info,debug,OK
ignore_status = []
# 选择编码,如果编码有误会导致数据无法查看。默认为空即可
# utf-8, utf-16le, utf-16le, gbk, gb18030 or ""
character_encoding = ""
## 设置正则表达式,例如 ^\d{4}-\d{2}-\d{2} 行首匹配 YYYY-MM-DD 时间格式
## 符合此正则匹配的数据,将被认定为有效数据,否则会累积追加到上一条有效数据的末尾
## 使用 3 个单引号 '''this-regexp''' 避免转义
## 正则表达式链接:https://golang.org/pkg/regexp/syntax/#hdr-Syntax
# multiline_match = '''^\S'''
## 是否开启自动多行模式,开启后会在 patterns 列表中匹配适用的多行规则
auto_multiline_detection = true
## 配置自动多行的 patterns 列表,内容是多行规则的数组,即多个 multiline_match,如果为空则使用默认规则详见文档
auto_multiline_extra_patterns = []
## 是否删除 ANSI 转义码,例如标准输出的文本颜色等
remove_ansi_escape_codes = false
## 忽略不活跃的文件,例如文件最后一次修改是 20 分钟之前,距今超出 10m,则会忽略此文件
## 时间单位支持 "ms", "s", "m", "h"
ignore_dead_log = "1h"
## 是否开启阻塞模式,阻塞模式会在数据发送失败后持续重试,而不是丢弃该数据
blocking_mode = true
## 是否开启磁盘缓存,可以有效避免采集延迟,有一定的性能开销,建议只在日志量超过 3000 条/秒再开启
enable_diskcache = false
## 是否从文件首部开始读取
from_beginning = false
# 自定义 tags
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
# ...
重启Datakit
datakit service -R
- 日志查看器分析日志
关于日志分析,可参考查看器检索(https://docs.guance.com/others/explorer-search/),对日志字段的搜索进行全面的介绍。
5.1.1 Sidecar日志
对于日志文件在Pod容器里的场景,观测云自开发的Sidecar容器通过使用 volumes 和 volumeMounts 将应用容器的日志目录挂载和共享,以便在 观测云Sidecar容器(logfwd 容器)能够正常访问到。
整个接入分两个过程:
第一步:开启Sidecar采集器logfwdserver
具体Datakit在K8S中的安装,参考5.1采集器Datakit的安装中的Kubernetes进行安装。以下是通过环境变量即可开启logfwdserver采集模块。
- name: ENV_DEFAULT_ENABLED_INPUTS
value: cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container,logfwdserver
注意:每次修改或增加采集模块,需要重启Datakit。
第二步:在业务Pod编排中应用Sidecar
完整例子如下:
apiVersion: v1
kind: Pod
metadata:
name: logfwd
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: logfwd
env:
- name: LOGFWD_DATAKIT_HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- name: LOGFWD_DATAKIT_PORT
value: "9533"
- name: LOGFWD_ANNOTATION_DATAKIT_LOGS
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.annotations['datakit/logs']
- name: LOGFWD_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: LOGFWD_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: pubrepo.jiagouyun.com/datakit/logfwd:1.9.2
imagePullPolicy: Always
resources:
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "2Gi"
volumeMounts:
- name: varlog
mountPath: /var/log
- mountPath: /opt/logfwd/config
name: logfwd-config-volume
subPath: config
workingDir: /opt/logfwd
volumes:
- name: varlog
emptyDir: {}
- configMap:
name: logfwd-config
name: logfwd-config-volume
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logfwd-config
data:
config: |
[
{
"loggings": [
{
"logfiles": ["/var/log/1.log"],
"source": "log_source",
"tags": {
"flag": "tag1"
}
},
{
"logfiles": ["/var/log/2.log"],
"source": "log_source2"
}
]
}
]
5.2 Stdout日志
该类日志采集主要应用在K8S中,以下安装为K8S中的Datakit安装方式。
采集器Datakit的安装
1、登陆官网(https://www.guance.com/)注册并登陆
2、根据下图选择适用于你的环境,进行安装采集器Datakit
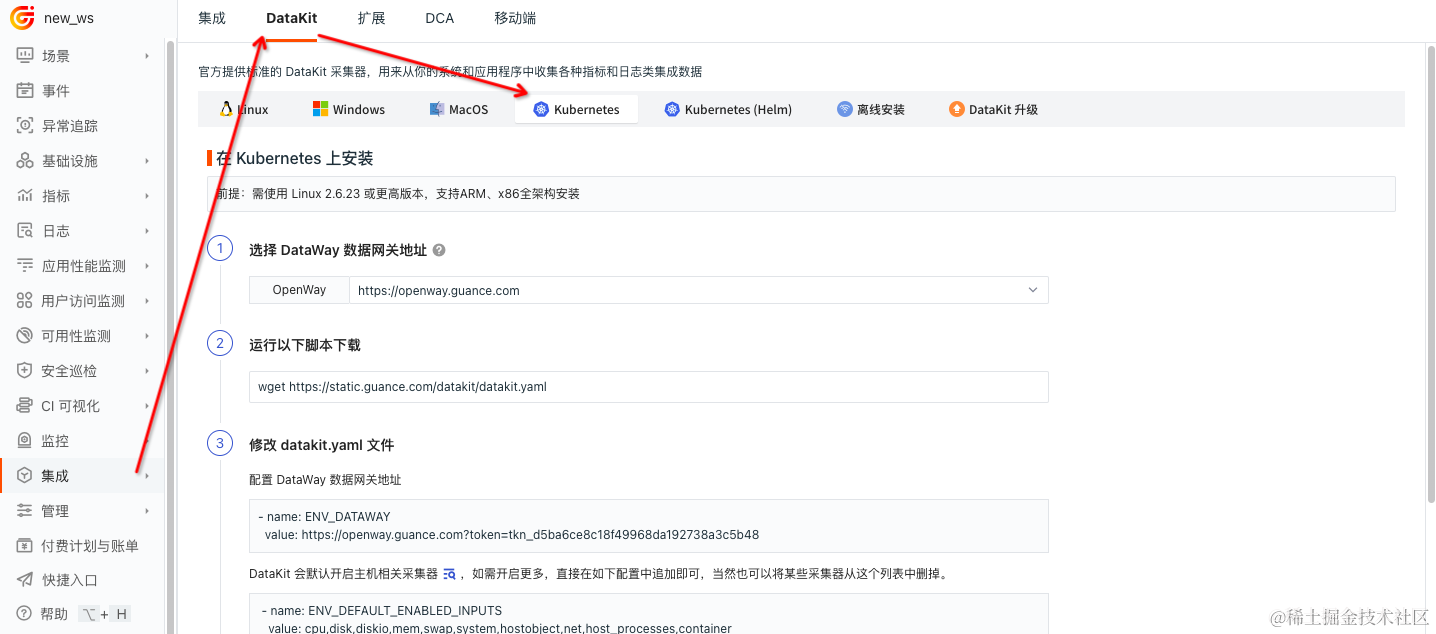
采集模块配置
K8S下安装Datakit后,默认开启所有业务Pod的Stdout日志收集,在ENV_DEFAULT_ENABLED_INPUTS环境变量中的container为Stdout日志的采集模块。
5.3 日志流采集
日志流采集从观测云接入的各类场景,总结下来,又细分出从第三方日志系统接收。以下以logback TCP为例展开配置说明。
- 采集器Datakit的安装
参考本文中的5.1章节中的采集器安装。
- 采集模块配置
cp logging.conf.sample logging.conf
vi logging.conf
需要注意的是:socket 和文件两种采集方式,目前只能选择其中之一,不能既通过文件采集,又通过 socket 采集。
[[inputs.logging]]
## Required
## File names or a pattern to tail.
#logfiles = [
# "/var/log/syslog",
# "/var/log/message",
#]
# Only two protocols are supported:TCP and UDP.
sockets = [
"tcp://0.0.0.0:9530",
# "udp://0.0.0.0:9531",
]
## glob filteer
ignore = [""]
## Your logging source, if it's empty, use 'default'.
source = ""
## Add service tag, if it's empty, use $source.
service = ""
## Grok pipeline script name.
pipeline = ""
## optional status:
## "emerg","alert","critical","error","warning","info","debug","OK"
ignore_status = []
## optional encodings:
## "utf-8", "utf-16le", "utf-16le", "gbk", "gb18030" or ""
character_encoding = ""
## The pattern should be a regexp. Note the use of '''this regexp'''.
## regexp link: https://golang.org/pkg/regexp/syntax/#hdr-Syntax
# multiline_match = '''^\S'''
auto_multiline_detection = true
auto_multiline_extra_patterns = []
## Removes ANSI escape codes from text strings.
remove_ansi_escape_codes = false
## If the data sent failure, will retry forevery.
blocking_mode = true
## If file is inactive, it is ignored.
## time units are "ms", "s", "m", "h"
ignore_dead_log = "1h"
## Read file from beginning.
from_beginning = false
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
重启Datakit
datakit service -R
- 软件侧修改日志Appender
1 添加依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.9</version>
</dependency>
2 日志配置添加 Appender
本步骤中我们把 DataKit 的地址、Socket 端口、Service 、Source 定义成外部可传入的参数。在项目的logback-spring.xml 文件中添加 Appender ,定义 datakitHostIP 、datakitSocketPort 、datakitSource 、datakitService ,值分别通过 guangce.datakit.host_ip 、guangce.datakit.socket_port 、guangce.datakit.source 、guangce.datakit.service 从外部传入
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<springProperty scope="context" name="datakitHostIP" source="guangce.datakit.host_ip" />
<springProperty scope="context" name="datakitSocketPort" source="guangce.datakit.socket_port" />
<springProperty scope="context" name="datakitSource" source="guangce.datakit.source" />
<springProperty scope="context" name="datakitService" source="guangce.datakit.service" />
<contextName>logback</contextName>
<!-- 日志根目录 -->
<property name="log.path" value="./logs/order"/>
<!-- 日志输出格式 -->
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{20} - [%method,%line] - - %msg%n" />
<!-- 打印日志到控制台 -->
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${log.pattern}</pattern>
</encoder>
</appender>
...
<appender name="socket" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>${datakitHostIP:-}:${datakitSocketPort:-}</destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC+8</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"source": "${datakitSource}",
"service": "${datakitService}",
"method": "%method",
"line": "%line",
"thread": "%thread",
"class": "%logger{40}",
"msg": "%message\n%exception"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="Console"/>
...
<appender-ref ref="socket" />
</root>
</configuration>
3 配置默认值
guangce:
datakit:
host_ip: 127.0.0.1 # datakit地址
socket_port: 9542 # datakit socket端口
#source: mySource # 如果不放开,将会使用socket采集器定义的source
#service: myService # 如果不放开,将会使用socket采集器定义的service
六 接入问题反馈
使用者在以上数据接入过程中,遇到难以解决的问题,可以通过观测云Studio的工单管理进行咨询。观测云为用户提供 5*8 小时的工单服务时间,客服人员收到工单问题后,会尽快为您处理。
工单管理入口
观测云Studio > 左下角帮助 > 工单管理