背景:
redis集群不支持客户端的mget操作,但是业务上对这个redis集群的批量操作的需求一直都在,所以有各种客户端实现了各式各样的pineline实现,本文就记录下我们公司的实现方式
pineline实现思路
1.pineline要快
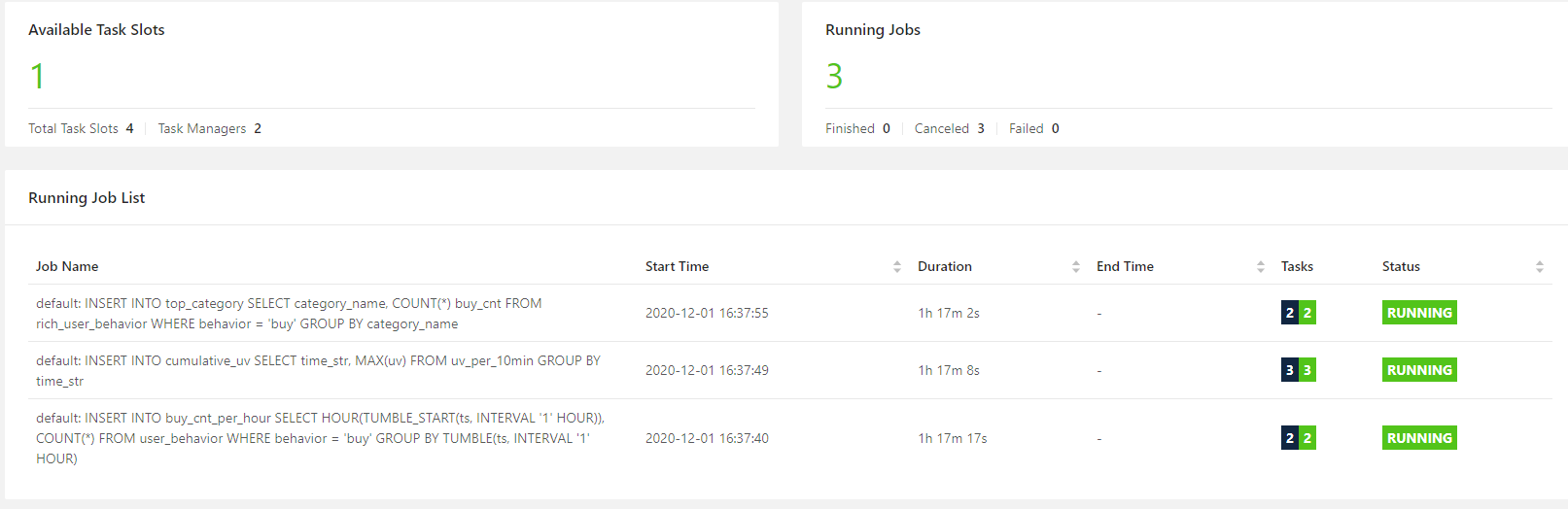
pineline之所以快是因为可以使用并行,而之前只能是串行的方式,如下图所示:

对应pineline伪代码实现:
for(key : keys){
1. jedis = 获取key所在的slot对应的redis实例的连接
2.jedis.send(命令),只发送,不接收结果,返回Feture<key>
}
for(Feture<key>: futures){
1.feture.get获取结果
}
最终的就能达到并行的目的,大大节省了操作耗时
2.pineline遇到redis集群扩容时要有兜底
pineline虽然使用并行的方式会比较快,但是这样有一个问题,如果某个key在获取的过程中发生重定向异常怎么办?我们应该有兜底的策略,最简单的兜底策略就是回退到单个key一个个串行获取的方式,虽然性能收到影响,但是至少数据能正确获取到,示意图参见

对应pineline兜底伪代码实现:
try{
}catch(重定向异常){
for(key : keys){
1. jedis = 获取key所在的slot对应的redis实例的连接
2.jedis.send(命令),wait等待获取结果jedis.getResult()
}}
直接通过串行的单个请求响应的方式获取这一批key的返回值即可
总结:
实现redis集群客户端的pineline操作需要考虑到要快并且能在redis集群扩容的情况下进行兜底