import numpy as np
def dense(A,W):
Z=np.matmul(A,W)#矩阵乘法
return 1/(1+np.exp(-Z))
if __name__ == '__main__':
leanring_rate=100
A=np.array([[200.0,17.0]])
# W=np.array([[1,-3,5],
# [-2,4,-6]])
# b=np.array([[-1,1,2]])
W1 = np.array([[0., -10, 4],
[-1,3,2]])
W2=np.array([[1.0],
[2],
[3]])
b1=np.array([[-1,0,2.0]])
b2 = np.array([[1.0]])
hid=dense(A,W1)
o=dense(hid,W2)
for i in range(200):
# 计算梯度
o_error=1-o
o_delta=(1-o)*o*(1-o)
hid_error=o_delta.dot(W2.T)#这里W2转置之后才能对应上
hid_delta=hid_error*(1-hid)*hid # 注意区分*和dot,*是向量点乘,dot是矩阵乘法,得到一个1乘3的delta数组
print(o_error)
# 更新模型参数
W1+=A.T.dot(hid_delta)*leanring_rate
W2+=hid.T.dot(o_delta)*leanring_rate
#前向传播
hid = dense(A, W1)
o = dense(hid, W2)
print(W1,"\n")
print(hid,W2,"\n")
print(o)
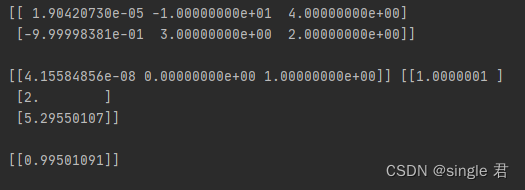
找了好多资料,勉强搭建起自己的简易神经网络,后面估计是基于这个的优化。
这里相当于简化了没使用偏置
参考文章:
https://blog.csdn.net/jining11/article/details/88678065?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169478897716800182747019%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169478897716800182747019&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-88678065-null-null.142v94chatsearchT3_1&utm_term=%E7%94%A8numpy%E5%AE%9E%E7%8E%B0%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&spm=1018.2226.3001.4187
https://www.cnblogs.com/jsfantasy/p/12177275.html