TreeMap是Java集合,它以有序的键及其相应的值的形式组织数据。它自JDK 1.2以来就已经存在。在内部,TreeMap使用红黑树来组织数据,这是一种自平衡二叉树。TreeMap中的键是唯一的标识符,默认情况下,TreeMap会根据键的自然顺序来排列数据。
对于整数键,它们是按键的升序存储的;对于String键,数据将按字母顺序存储。我们总是可以覆盖数据的默认排序,并在创建TreeMap时使用比较器来按照比较器中提供的逻辑以任何定义的方式进行自定义排序。在这篇文章中,我们将详细讨论一些自定义混合排序方法,并提供一些代码示例。
最流行的搜索和排序数据结构之一是二叉搜索树(BST)。当涉及到搜索操作性能时,二叉搜索树具有最坏情况下的复杂度为O(n),这几乎与线性搜索相同。
红黑树对于每次插入和删除操作都有一个恒定的时间复杂度O(log n),因为它在每次操作后自我平衡,确保树始终是平衡的。这意味着树会自动以最优方式进行调整,这确保了搜索和查找操作非常高效,并且对于任何数据集以及任何类型的搜索操作,时间复杂度都不会超过O(log n)。
它使用一个简单但强大的机制,通过为树中的每个节点着色为红色或黑色来维持一个平衡的结构。它可以被称为自平衡二叉搜索树。它具有良好、高效的最坏情况下的运行时间复杂度。
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等
为什么使用TreeMap?
大多数BST操作(如搜索、删除、查找和更新)需要O(log n)的时间,其中n是二叉搜索树中的节点数。对于所有键都沿着一个特定路径的偏斜的二叉树,这些操作的成本可能会变为O(n),即它要么是一个左偏斜的二叉树,所有元素只沿左路径,要么是一个右偏斜的二叉搜索树,所有元素都沿二叉搜索树的右路径。这些类型的数据情况会使二叉搜索树变得非常高效,所有类型的操作都会非常耗时。
除了搜索操作外,插入或删除操作在最坏的情况下也将需要O(n)的时间复杂度。这种情况会导致一个完全不平衡的二叉搜索树,树的高度几乎等于树中的节点数。
如果我们确保每次插入和删除后树的高度保持在O(log n),那么我们可以确保所有这些操作的上界为O(log n),即使在数据高度偏斜的最坏情况下。这是通过引入红黑树来实现的,无论数据是偏斜还是非偏斜,树总是平衡的。红黑树的高度始终是O(log n),其中n是树中的节点数。
默认情况下,红黑树具有以下属性,这些属性在TreeMap数据集中是固有的:
-
每个节点在TreeMap中都有指向父节点、右子节点和左子节点的引用。如果某个节点不存在,则在TreeMap中可能有这三个引用或减少的引用。
-
左子元素键的值总是小于父元素键的值。
-
右子元素键的值总是大于或等于TreeMap中父元素键的值。
-
每个树节点要么是红色,要么是黑色。
-
树的根节点总是黑色的。
-
从根到任何叶节点的每条路径必须有相同数量的黑色节点。
-
不能有两个红色节点相邻;即红色节点不能是另一个红色节点的父节点或子节点。
如果您查看下面的表格,红黑树在任何数据情况下的时间复杂度始终是相同的,它不受数据偏斜的影响,始终表现稳定。这使得TreeMap成为处理高容量数据集的非常高效和广泛使用的数据结构,在这些数据集中,我们不确定底层数据的偏斜度,并且我们可以在TreeMap上执行一些在其他映射数据结构(如HashMap)中不可能的独特操作。
时间复杂度
| 操作 | 平均情况 | 最坏情况 |
| 搜索 | O(log n) | O(log n) |
| 插入 | O(log n) | O(log n) |
| 删除 | O(log n) | O(log n) |
在极端偏斜数据的情况下进行搜索操作,这是在二叉搜索树中组织数据的最坏情况,红黑树对于最坏的情况表现更好。红黑树可以用于高效地索引数据库中的数据,支持需要快速搜索和检索数据的技术。
在这篇文章中,我不打算详细解释红黑算法,但我们将重点介绍TreeMap提供的一些小众功能,TreeMap是红黑树的一个突出实现。
为何使用TreeMap
Java中的TreeMap类提供了丰富的API,支持多种搜索操作。它不仅支持相等搜索操作(被搜索的元素存在于映射中),还支持其他的特殊搜索操作,如查找映射中比给定元素稍大或稍小的元素。
此外,还有给定范围内的映射的子映射。只有当键按照某种顺序排列时,这种复杂的搜索操作才是可能的,而TreeMap是非常适合处理此类处理需求的数据结构。搜索操作通常需要O(log n)时间来返回结果。与HashMap不同,虽然HashMap只需要常数时间,但执行搜索操作需要对数时间。这让人不禁想知道为什么它首先会被引入。
答案是,即使对于不属于HashMap的最坏情况类别的场景,HashMap以常数时间复杂度提供最优搜索,数据也会以连续的方式保存在内存中。而对于TreeMap,没有这样的限制,它只使用存储项目所需的内存量,与使用连续内存区域的HashMap不同。如上所述的另一个关键原因是,TreeMap提供了执行特殊搜索操作的功能,这不仅仅是在映射中找到给定的键,还可以找到其他键,这些键可能只是稍大、稍小或最小的键,或者是给定键范围的数据集的一部分。
与只提供等值搜索操作的HashMap不同,即要搜索的值等于Map中的任何键,TreeMap提供了以TreeMap的形式结构化的各种搜索操作的能力。搜索的能力使TreeMap成为解决复杂搜索用例的非常关键的数据结构,在我的经验中,我广泛地使用它来解决许多复杂的业务需求。以下是TreeMap提供的一些最主要的搜索功能。我们首先将熟悉TreeMap提供的基本功能,之后将讨论一些特殊的搜索需求,在这些需求中,我们将结合上述TreeMap功能来达到不同种类的搜索功能的特殊需求:
-
floorKey(K key): 此函数在TreeMap中搜索小于或等于给定键的最大键。如果函数找不到这样的键,它将返回null。
-
ceilingKey(K key): 此函数在TreeMap中搜索大于或等于给定键的最小键。如果函数找不到这样的键,它将返回null。
-
higherKey(K key): 此函数在TreeMap中搜索严格大于给定键的最小键。如果函数找不到这样的键,它将返回null。
-
lowerKey(K key): 此函数在TreeMap中搜索严格小于给定键的最大键。如果函数找不到这样的键,它将返回null。
-
subMap(K from Key, K toKey): 此函数搜索此映射的部分视图,其键的范围从fromKey(包括)到toKey(不包括)。
-
tailMap(K fromKey): 此函数搜索此映射的部分视图,其键大于或等于fromKey。
-
headMap(K toKey): 此函数搜索与小于给定键的最小键关联的键值映射,或者如果没有这样的键则返回null。
现在我们已经了解了TreeMap提供的关键功能和不同类型的搜索功能,我们将通过代码示例更好地理解它,稍后我们将尝试定义一些新的特殊搜索和数据结构功能,使用上面列出的TreeMap功能的不同组合:
使用案例
我们将使用下面捕获的员工实体。此类具有几个关键的员工特性,用于说明用例。
在以下员工类中,除了员工标识符属性外,我们还捕获了一些将在用例中使用的额外的不同属性。这些属性如下:
-
lastYearRating: 此属性保存了员工去年的评估评级。
-
tenure: 此属性保存了员工与组织共度的年数的四舍五入值。
-
currentSalary: 此属性存储了员工的当前年薪。
class Employee {
String empName;
String designation;
Integer empId;
String lastYearRating;
Integer tenure;
Integer currentSalary;
public Employee(String empName, String designation, Integer empId, String lastYearRating, Integer tenure, Integer currentSalary) {
this.empName = empName;
this.designation = designation;
this.empId = empId;
this.lastYearRating = lastYearRating;
this.tenure = tenure;
this.currentSalary = currentSalary;
}
@Override
public String toString() {
return "Employee{" +
"empName='" + empName + '\'' +
", designation='" + designation + '\'' +
", empId=" + empId +
", lastYearRating='" + lastYearRating + '\'' +
", tenure=" + tenure +
", currentSalary=" + currentSalary +
'}';
}
public Integer getCurrentSalary() {
return currentSalary;
}
public void setCurrentSalary(Integer currentSalary) {
this.currentSalary = currentSalary;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public String getDesignation() {
return designation;
}
public void setDesignation(String designation) {
this.designation = designation;
}
public Integer getEmpId() {
return empId;
}
public void setEmpId(Integer empId) {
this.empId = empId;
}
public String getLastYearRating() {
return lastYearRating;
}
public void setLastYearRating(String lastYearRating) {
this.lastYearRating = lastYearRating;
}
public Integer getTenure() {
return tenure;
}
public void setTenure(Integer tenure) {
this.tenure = tenure;
}
}在下面的代码示例中,我们将使用TreeMap的功能来解决一些特殊场景:
我们将按照组织的工龄分桶来对所有员工进行分桶:我们将有六个工龄桶,并将每个员工记录放在他们所属的正确桶中。这将使用TreeMap提供的一些特殊功能,并将以非常简化的方式展示。接下来,我们将为每个员工关联正确的工龄桶。
import java.util.ArrayList;
import java.util.TreeMap;
public class TreeMapCeilingFloorExample {
public static void main(String[] args) {
TreeMap<Integer, Object> tenureTreeMap = new TreeMap<>();
/* employee List, for illustration purpose just creating few dummy entries but in actual it can be read from source
* and can run into very high numbers including all employees for the organization */
ArrayList<Employee> empList = new ArrayList<Employee>();
empList.add(new Employee("John", "Engineer", 24, "A1", 6,150000));
empList.add(new Employee("David", "Manager", 35, "A2", 3,145000));
empList.add(new Employee("Fred", "Architect", 41, "B1", 2, 155000));
empList.add(new Employee("Brad", "Engineer", 21, "A3", 8,120000));
empList.add(new Employee("Jason", "Engineer", 32, "A1", 4,170000));
empList.add(new Employee("Adam", "Senior Engineer", 12, "A1", 14,85000));
empList.add(new Employee("Christie", "Director", 10, "A1", 15,178000));
empList.add(new Employee("Martha", "Accountant", 26, "A1", 6,85000));
empList.add(new Employee("Diana", "Engineer", 28, "A1", 6,108000));
empList.add(new Employee("Lisa", "Developer", 14, "A1", 12,82000));
/* Adding the default buckets for the employee tenures with 0-5, 6- 10, 11-15, 16-20, 21-25, 26-30
* Adding only higher bound as key so can efficiently use ceiling function to categorize all employees into right bucket */
tenureTreeMap.put(5, new ArrayList<Employee>());
tenureTreeMap.put(10, new ArrayList<Employee>());
tenureTreeMap.put(15, new ArrayList<Employee>());
tenureTreeMap.put(20, new ArrayList<Employee>());
tenureTreeMap.put(25, new ArrayList<Employee>());
tenureTreeMap.put(30, new ArrayList<Employee>());
/* Using ceilingKey function to check for every employee record and adding the employee to the right bucket.
* This is a simple illustration leveraging ceilingKey function to easily bucket employees into the right bucket */
empList.forEach(employeeObj -> {
Integer key = tenureTreeMap.ceilingKey(employeeObj.getTenure());
ArrayList matchingList = (ArrayList) tenureTreeMap.get(key);
matchingList.add(employeeObj);
tenureTreeMap.put(key, matchingList);
});
// Printing all Employees in the bucket starting with lowest to highest
tenureTreeMap.forEach((key, value) -> {
System.out.println("Key : " + key + " Value : ");
((ArrayList) value).forEach(empObj -> System.out.println());
});
}
}结果
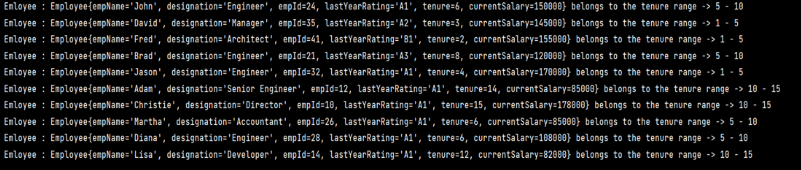
以下是工龄TreeMap的描述,其中每个员工都被归入正确的工龄类别。关键是工龄桶的上界,下界是先前记录的上界+1。这是根据给定范围结构化数据的有效方式。这里我们有六个工龄桶,如下:
-
0年到5年:对于这个范围,关键是5,这是这个桶的上界。三个员工记录落入这个桶。
-
6年到10年:对于这个范围,关键是10,这是这个桶的上界。四个员工记录落入这个桶。
-
11年到15年:对于这个范围,关键是15,这是这个桶的上界。三个员工记录落入这个桶。
-
16年到20年:对于这个范围,关键是20,这是这个桶的上界。没有员工记录落入这个桶。
-
21年到25年:对于这个范围,关键是25,这是这个桶的上界。没有员工记录落入这个桶。
-
26年到30年:对于这个范围,关键是30,这是这个桶的上界。没有员工记录落入这个桶。

记住,TreeMap使用键的自然顺序(或者提供的自定义比较器)来确定元素的顺序。确保导入TreeMap类,并处理方法返回null的情况,如果没有适合的键按照你的用例。
以下代码函数为每个员工记录关联工龄范围。结果也打印在代码下面,显示每个员工记录的工龄范围。TreeMap是用工龄范围的上界作为键创建的,所有给定工龄范围的员工都在形式为数组列表的给定键对应的值中。
下面列出的代码使用天花板和地板函数在TreeMap中为任何键查找下界和上界。在下面的情况下,我们试图找出每个员工记录的工龄范围,通过使用lowerKey函数获得下界。接下来使用ceilingEntry方法确定上界,形成范围字符串,并与每个员工记录相关联。这是一个简单的插图,展示了TreeMap功能的力量,通过利用内置功能轻松完成复杂的需求。
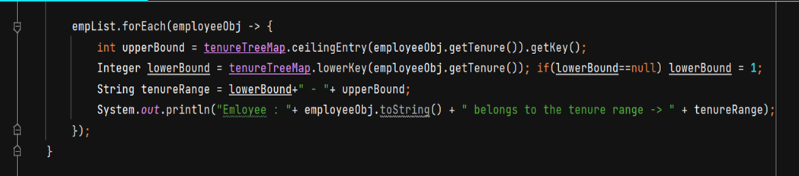
结果:在下面的输出中,每个员工都有一个与该记录相关联的任期存储桶。
希望这篇文章帮助你熟悉了TreeMap数据结构,并帮助你使用内置的TreeMap函数来解决复杂的数据分类和搜索需求。
作者:Alejandro Duarte
更多技术干货请关注公众号 “云原生数据库”