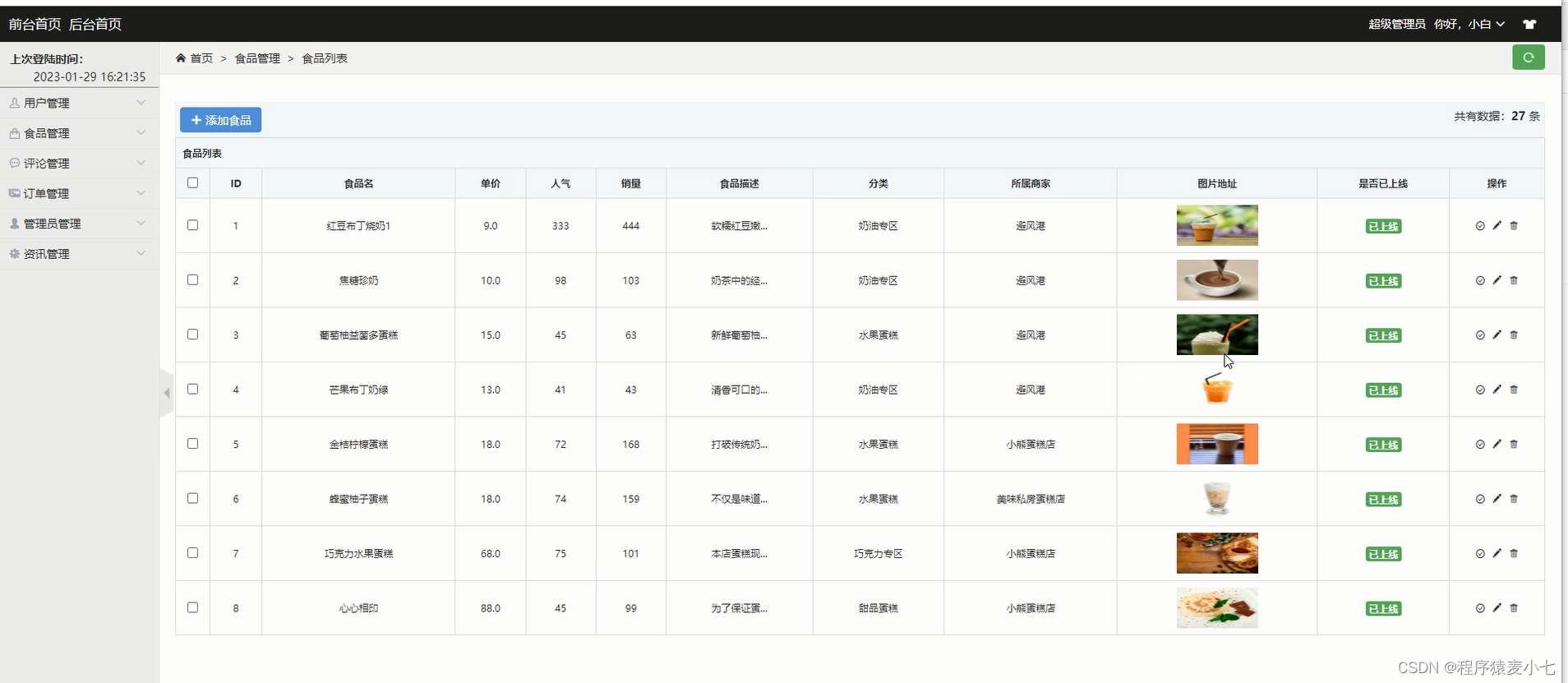
步态识别常见模块解读及代码实现:基于OpenGait框架
最近在看步态识别相关论文,但是因为记忆力下降的原因,老是忘记一些内容。因此记录下来方便以后查阅,仅供自己学习参考,没有背景知识和论文介绍。
目录
- 步态识别常见模块解读及代码实现:基于OpenGait框架
- 一、GaitSet: Set-Based Recognition
- 1, set_block:提取空间特征信息
- 2, gl_block:提取各种层次的set信息
- 3, set_pooling:提取时序信息
- 4, Horizontal Pooling Matching (HPM)
- 5, SeparateFCs
- 6,forward
- 二、GaitPart: Part-based **(Local)** Recognition
- 1, backbone
- 2,HPP
- 3, Temporal Feature Aggregator (TFA)
- 4, forward
- 三、GLN: feature pyramid
- 1,backbone (encoder)
- 2, lateral (decoder)
- 3, Compact Block
- 四、GaitGL: Global and Local
- 1,GLConv:提取时空特征
- 2,LTA: Local Temporal Aggregation
- 3, Gait Recognition Head
- motivation: HPP对所有数据集采用相同的处理方式(指按固定比例混合全局池化和平均池化),不能自适应处理。
- method: 公式如下,通过参数p来自适应调整比例。当p=1,等价于平均池化;当p趋于无穷,等价于最大池化。 Y T F M Y_{TFM} YTFM表示TP后的特征。
- 4, forward
- 五、SMPLGait:
- 1,SLN:Silhouette Learning Network
- 2, 3D-STN: 3D Spatial Transformation Network
- 3, 3D Spatial Transformation Module: 融合多模态特征
- 六、GaitEdge
- 1,pre-process:提取边缘信息和内部信息
- 2, Gait Synthesis: 依据边缘信息和内部信息对分割出的人体信息进行增强
- 3, Gait Align
- 七、GaitBase
- 1, backbone: ResNet-9
- 2, TP和HPP
- 3,BNNeck
一、GaitSet: Set-Based Recognition
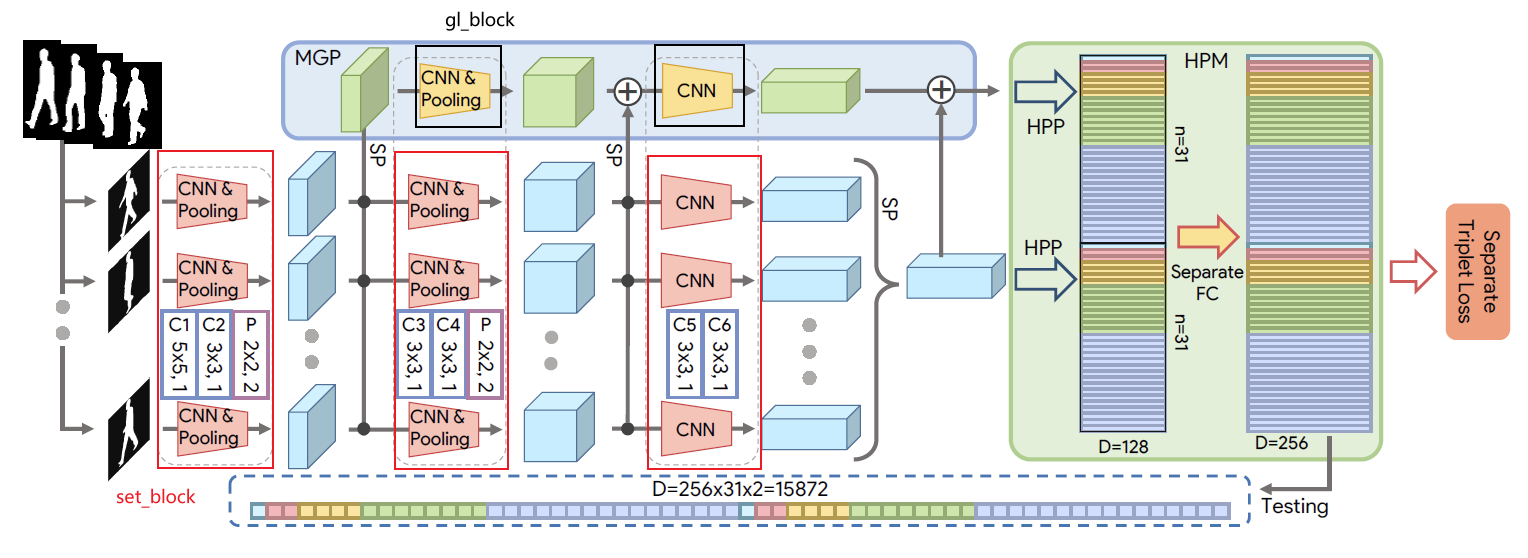
1, set_block:提取空间特征信息
Gaitset中共有3个set_block,前两个set_block带有MaxPooling层,代码如下:
self.set_block1 = nn.Sequential(BasicConv2d(in_c[0], in_c[1], 5, 1, 2),
nn.LeakyReLU(inplace=True),
BasicConv2d(in_c[1], in_c[1], 3, 1, 1),
nn.LeakyReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2))
self.set_block2 = nn.Sequential(BasicConv2d(in_c[1], in_c[2], 3, 1, 1),
nn.LeakyReLU(inplace=True),
BasicConv2d(in_c[2], in_c[2], 3, 1, 1),
nn.LeakyReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2))
self.set_block3 = nn.Sequential(BasicConv2d(in_c[2], in_c[3], 3, 1, 1),
nn.LeakyReLU(inplace=True),
BasicConv2d(in_c[3], in_c[3], 3, 1, 1),
nn.LeakyReLU(inplace=True))
所有的set_block会用SetBlockWrapper进行封装,代码如下:
self.set_block1 = SetBlockWrapper(self.set_block1)
self.set_block2 = SetBlockWrapper(self.set_block2)
self.set_block3 = SetBlockWrapper(self.set_block3)
SetBlockWrapper用于reshape数据,保证conv是在[c, h, w]维度上进行,代码如下:
class SetBlockWrapper(nn.Module):
def __init__(self, forward_block):
super(SetBlockWrapper, self).__init__()
self.forward_block = forward_block
def forward(self, x, *args, **kwargs):
"""
n是bacth_size,也就是当前batch中序列的总数; s是序列中的帧数
In x: [n, c_in, s, h_in, w_in]
Out x: [n, c_out, s, h_out, w_out]
"""
n, c, s, h, w = x.size()
# conv2d会将输入数据的最后三个维度视为[c, h, w],所以此处需要先reshape
x = self.forward_block(x.transpose(
1, 2).reshape(-1, c, h, w), *args, **kwargs)
output_size = x.size()
return x.reshape(n, s, *output_size[1:]).transpose(1, 2).contiguous()
2, gl_block:提取各种层次的set信息
GaitSet中有2个gl_block,其结构与SetBlockWrapper前的set_block相同:
self.gl_block2 = copy.deepcopy(self.set_block2)
self.gl_block3 = copy.deepcopy(self.set_block3)
进入gl_block前,特征会进行以此set_pooling, shape从[n, c, s, h, w]变为[n, c, h, w],所以gl_block无需SetBlockWrapper。
3, set_pooling:提取时序信息
set_pooling采用的是max_pooling,会在frame-level进行,代码如下:
self.set_pooling = PackSequenceWrapper(torch.max)
PackSequenceWrapper定义如下:
class PackSequenceWrapper(nn.Module):
def __init__(self, pooling_func):
super(PackSequenceWrapper, self).__init__()
self.pooling_func = pooling_func
def forward(self, seqs, seqL, dim=2, options={}):
"""
In seqs: [n, c, s, ...]
Out rets: [n, ...]
"""
if seqL is None:
# 对s维度进行pooling,[n, c, s, h, w]->[n, c, h, w]
return self.pooling_func(seqs, **options)
seqL = seqL[0].data.cpu().numpy().tolist()
start = [0] + np.cumsum(seqL).tolist()[:-1]
rets = []
for curr_start, curr_seqL in zip(start, seqL):
narrowed_seq = seqs.narrow(dim, curr_start, curr_seqL)
rets.append(self.pooling_func(narrowed_seq, **options))
if len(rets) > 0 and is_list_or_tuple(rets[0]):
return [torch.cat([ret[j] for ret in rets])
for j in range(len(rets[0]))]
return torch.cat(rets)
4, Horizontal Pooling Matching (HPM)
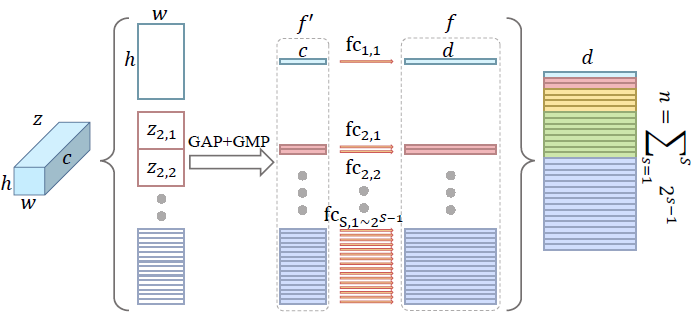
HPM会把特征在h维度上进行不同尺度的均分,然后再进行pooling,代码如下:
self.HPP = HorizontalPoolingPyramid(bin_num=model_cfg['bin_num'])
class HorizontalPoolingPyramid():
"""
Horizontal Pyramid Matching for Person Re-identification
Arxiv: https://arxiv.org/abs/1804.05275
Github: https://github.com/SHI-Labs/Horizontal-Pyramid-Matching
"""
def __init__(self, bin_num=None):
if bin_num is None:
# GaitSet论文中HPP分别按16, 8, 4, 2, 1等分,所以n=31
bin_num = [16, 8, 4, 2, 1]
self.bin_num = bin_num
def __call__(self, x):
"""
x : [n, c, h, w]
ret: [n, c, p]
"""
n, c = x.size()[:2]
features = []
for b in self.bin_num:
z = x.view(n, c, b, -1)
z = z.mean(-1) + z.max(-1)[0]
features.append(z)
return torch.cat(features, -1)
5, SeparateFCs
SeparateFCs对HPP的结果,按部分(part)分别进行fc映射,代码如下:
self.Head = SeparateFCs(**model_cfg['SeparateFCs'])
class SeparateFCs(nn.Module):
def __init__(self, parts_num, in_channels, out_channels, norm=False):
super(SeparateFCs, self).__init__()
self.p = parts_num
self.fc_bin = nn.Parameter(
nn.init.xavier_uniform_(
torch.zeros(parts_num, in_channels, out_channels)))
self.norm = norm
def forward(self, x):
"""
x: [n, c_in, p]
out: [n, c_out, p]
"""
x = x.permute(2, 0, 1).contiguous()
if self.norm:
out = x.matmul(F.normalize(self.fc_bin, dim=1))
else:
out = x.matmul(self.fc_bin)
return out.permute(1, 2, 0).contiguous()
最后计算loss的时候也是按照不同的part去计算triplet loss,然后取平均。
6,forward
def forward(self, inputs):
ipts, labs, _, _, seqL = inputs
sils = ipts[0] # [n, s, h, w]
if len(sils.size()) == 4:
sils = sils.unsqueeze(1) # [n, c, s, h, w]
del ipts
outs = self.set_block1(sils) # [n, c, s, h, w]
gl = self.set_pooling(outs, seqL, options={"dim": 2})[0] # [n, c, h, w]
gl = self.gl_block2(gl)
outs = self.set_block2(outs)
gl = gl + self.set_pooling(outs, seqL, options={"dim": 2})[0]
gl = self.gl_block3(gl)
outs = self.set_block3(outs)
outs = self.set_pooling(outs, seqL, options={"dim": 2})[0]
gl = gl + outs
# Horizontal Pooling Matching, HPM
feature1 = self.HPP(outs) # [n, c, p]
feature2 = self.HPP(gl) # [n, c, p]
feature = torch.cat([feature1, feature2], -1) # [n, c, p]
embs = self.Head(feature)
n, _, s, h, w = sils.size()
retval = {
'training_feat': {
'triplet': {'embeddings': embs, 'labels': labs}
},
'visual_summary': {
'image/sils': sils.view(n*s, 1, h, w)
},
'inference_feat': {
'embeddings': embs
}
}
return retval
二、GaitPart: Part-based (Local) Recognition

1, backbone
GaitPart中backbone主要由三个部分组成:Basic Conv2d (BC), MaxPool2d (M), Focal Conv2d (FC)。BC和M的结构很好理解,不多介绍。Focal Conv2d的代码如下:
class FocalConv2d(nn.Module):
"""
GaitPart: Temporal Part-based Model for Gait Recognition
CVPR2020: https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_GaitPart_Temporal_Part-Based_Model_for_Gait_Recognition_CVPR_2020_paper.pdf
Github: https://github.com/ChaoFan96/GaitPart
"""
def __init__(self, in_channels, out_channels, kernel_size, halving, **kwargs):
super(FocalConv2d, self).__init__()
self.halving = halving
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size, bias=False, **kwargs)
def forward(self, x):
# x.shape [B, C, H, W]
if self.halving == 0:
z = self.conv(x) # 等同于普通的Conv2d
else:
h = x.size(2)
# halving表示进行几次二等分
split_size = int(h // 2**self.halving)
z = x.split(split_size, 2) # 在h维度均分
z = torch.cat([self.conv(_) for _ in z], 2) # 拼接
return z
整个backbone用SetBlockWrapper进行封装。
2,HPP
由于GaitPart的backbone提取特征后,没有进行set_pooling,所以HPP也需要用SetBlockWrapper进行封装。HPP会在在h维度将特征均分为16份
self.HPP = SetBlockWrapper(
HorizontalPoolingPyramid(bin_num=model_cfg['bin_num']))
3, Temporal Feature Aggregator (TFA)
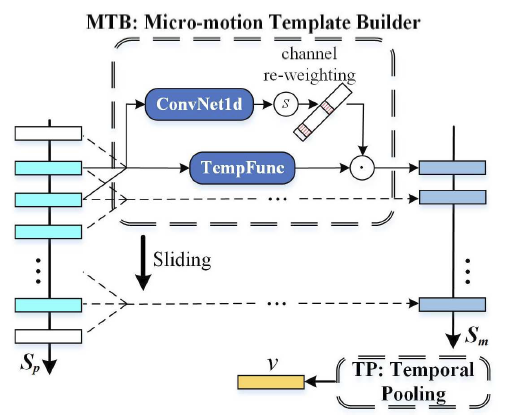
TFA模块针对每一个part来进行时间聚合,由两个MCM模块(Conv1d提取相邻帧特征)和时间池化模块(s维度的最大池化)组成。共有16个part,所以每个MCM模块都要深度拷贝16次(参数不共享)。代码如下:
class TemporalFeatureAggregator(nn.Module):
def __init__(self, in_channels, squeeze=4, parts_num=16):
super(TemporalFeatureAggregator, self).__init__()
hidden_dim = int(in_channels // squeeze)
self.parts_num = parts_num
# MTB1, 主要是conv1d来聚合相邻帧之间的信息
conv3x1 = nn.Sequential(
BasicConv1d(in_channels, hidden_dim, 3, padding=1),
nn.LeakyReLU(inplace=True),
BasicConv1d(hidden_dim, in_channels, 1))
self.conv1d3x1 = clones(conv3x1, parts_num)
# template function: avg_pool, max_pool
self.avg_pool3x1 = nn.AvgPool1d(3, stride=1, padding=1)
self.max_pool3x1 = nn.MaxPool1d(3, stride=1, padding=1)
# MTB2
conv3x3 = nn.Sequential(
BasicConv1d(in_channels, hidden_dim, 3, padding=1),
nn.LeakyReLU(inplace=True),
BasicConv1d(hidden_dim, in_channels, 3, padding=1))
self.conv1d3x3 = clones(conv3x3, parts_num)
self.avg_pool3x3 = nn.AvgPool1d(5, stride=1, padding=2)
self.max_pool3x3 = nn.MaxPool1d(5, stride=1, padding=2)
# Temporal Pooling, TP
self.TP = torch.max
def forward(self, x):
"""
Input: x, [n, c, s, p]
Output: ret, [n, c, p]
"""
n, c, s, p = x.size()
x = x.permute(3, 0, 1, 2).contiguous() # [p, n, c, s]
feature = x.split(1, 0) # [[1, n, c, s], ...]
x = x.view(-1, c, s)
# MTB1: ConvNet1d & Sigmoid
logits3x1 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)
for conv, _ in zip(self.conv1d3x1, feature)], 0)
scores3x1 = torch.sigmoid(logits3x1) # [p, n, c, s]
# MTB1: Template Function
feature3x1 = self.avg_pool3x1(x) + self.max_pool3x1(x) #[n*p, c, s]
feature3x1 = feature3x1.view(p, n, c, s)
feature3x1 = feature3x1 * scores3x1 # [p, n, c, s]
# MTB2: ConvNet1d & Sigmoid
logits3x3 = torch.cat([conv(_.squeeze(0)).unsqueeze(0)
for conv, _ in zip(self.conv1d3x3, feature)], 0)
scores3x3 = torch.sigmoid(logits3x3)
# MTB2: Template Function
feature3x3 = self.avg_pool3x3(x) + self.max_pool3x3(x)
feature3x3 = feature3x3.view(p, n, c, s)
feature3x3 = feature3x3 * scores3x3
# Temporal Pooling
ret = self.TP(feature3x1 + feature3x3, dim=-1)[0] # [p, n, c]
ret = ret.permute(1, 2, 0).contiguous() # [n, p, c]
return ret
4, forward
def forward(self, inputs):
ipts, labs, _, _, seqL = inputs
sils = ipts[0]
if len(sils.size()) == 4:
sils = sils.unsqueeze(1)
del ipts
out = self.Backbone(sils) # [n, c, s, h, w]
out = self.HPP(out) # [n, c, s, p]
out = self.TFA(out, seqL) # [n, c, p]
embs = self.Head(out) # [n, c, p]
n, _, s, h, w = sils.size()
retval = {
'training_feat': {
'triplet': {'embeddings': embs, 'labels': labs}
},
'visual_summary': {
'image/sils': sils.view(n*s, 1, h, w)
},
'inference_feat': {
'embeddings': embs
}
}
return retval
三、GLN: feature pyramid
GLN可以看作是一个U-shape结构的编码器-解码器网络,先看看编码器部分。
1,backbone (encoder)
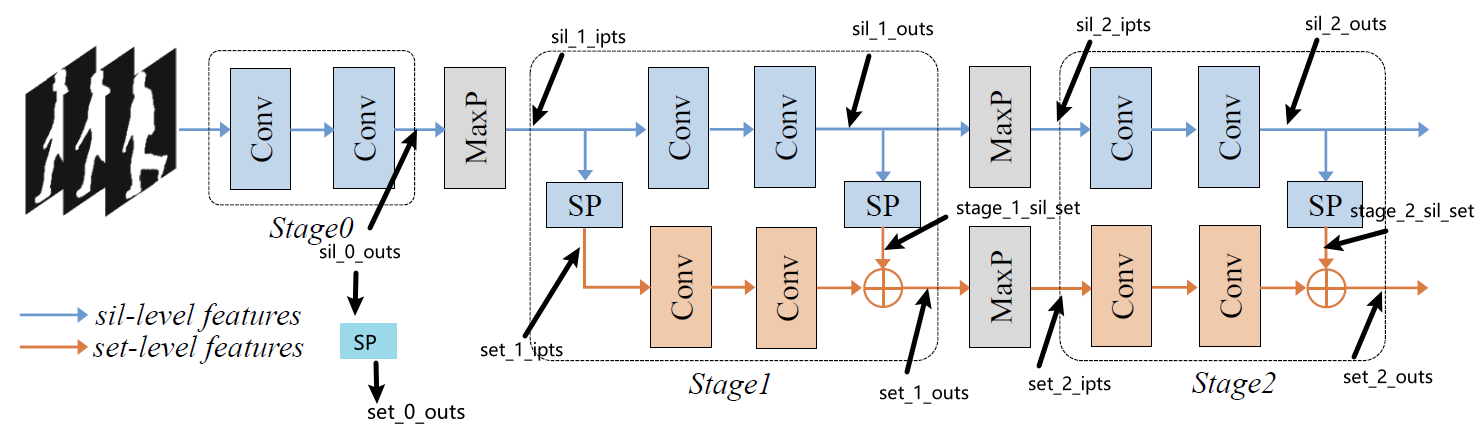
backbone包含三个stage,每个stage的sil_outs和set_outs会拼接作为当前stage的特征输出。在图中stage0没有进行set_pooling来获取set_outs,但是代码中有进行相关操作。该模块forward过程如下:
### stage 0 sil ###
sil_0_outs = self.sil_stage_0(sils)
stage_0_sil_set = self.set_pooling(sil_0_outs, seqL, options={"dim": 2})[0]
### stage 1 sil ###
sil_1_ipts = self.MaxP_sil(sil_0_outs)
sil_1_outs = self.sil_stage_1(sil_1_ipts)
### stage 2 sil ###
sil_2_ipts = self.MaxP_sil(sil_1_outs)
sil_2_outs = self.sil_stage_2(sil_2_ipts)
### stage 1 set ###
set_1_ipts = self.set_pooling(sil_1_ipts, seqL, options={"dim": 2})[0]
stage_1_sil_set = self.set_pooling(sil_1_outs, seqL, options={"dim": 2})[0]
set_1_outs = self.set_stage_1(set_1_ipts) + stage_1_sil_set
### stage 2 set ###
set_2_ipts = self.MaxP_set(set_1_outs)
stage_2_sil_set = self.set_pooling(sil_2_outs, seqL, options={"dim": 2})[0]
set_2_outs = self.set_stage_2(set_2_ipts) + stage_2_sil_set
set1 = torch.cat((stage_0_sil_set, stage_0_sil_set), dim=1)
set2 = torch.cat((stage_1_sil_set, set_1_outs), dim=1)
set3 = torch.cat((stage_2_sil_set, set_2_outs), dim=1)
编码器中,sil_stage需要用SetBlockWrapper封装,而set_stage由于输入会进行set_pooling,所以无需SetBlockWrapper封装。
2, lateral (decoder)
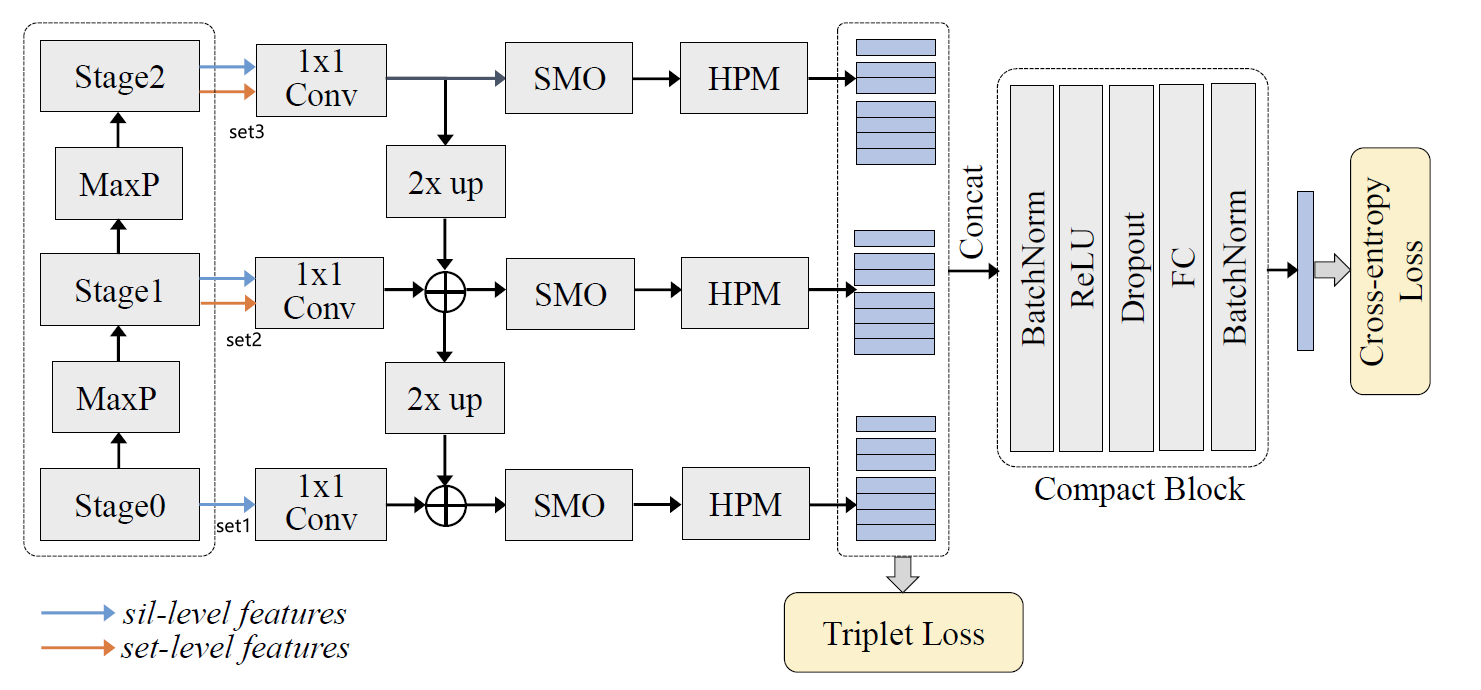
解码器部分,从上到下逐层up_add,然后进行平滑,最后HPP。最终,三个stage的代码会拼接并经过SeparateFCs,forward代码如下:
set3 = self.lateral_layer3(set3) # Conv2d
set2 = self.upsample_add(set3, self.lateral_layer2(set2))
set1 = self.upsample_add(set2, self.lateral_layer1(set1))
set3 = self.smooth_layer3(set3) # Conv2d
set2 = self.smooth_layer2(set2)
set1 = self.smooth_layer1(set1)
set1 = self.HPP(set1)
set2 = self.HPP(set2)
set3 = self.HPP(set3)
feature = torch.cat([set1, set2, set3], -1)
feature = self.Head(feature) # SeparateFCs
可以看到示意图中对于stage0只用了sil_features, 但是代码中实际做法为:对sil_features进行set_pooling获得set_features。
3, Compact Block
作者认为在GaitSet的HPM中,将特征沿h维度划分为不同的区域时,会存在特征冗余。例如,(s, t) = (4, 1) 和(s, t) = {(8, 1), (8, 2)}就表示相同的区域,其中s是划分的尺度,t是区域的index。(换言之,”四等分的第一块“等价于”八等分的第一块和第二块“)。由于HPM最终一共会产生 1 + 2 + 4 + 8 + 16 = 31 1+2+4+8+16=31 1+2+4+8+16=31个part,每个part的dimension都是256,所以最终的特征维度为 31 × 256 = 7936 31\times256=7936 31×256=7936。为此,GLN提出了Compact Block来对特征维度进行压缩。定义如下:
self.encoder_bn = nn.BatchNorm1d(sum(self.bin_num)*3*self.hidden_dim)
self.encoder_bn.bias.requires_grad_(False)
self.reduce_dp = nn.Dropout(p=model_cfg['dropout'])
self.reduce_ac = nn.ReLU(inplace=True)
self.reduce_fc = nn.Linear(sum(self.bin_num)*3*self.hidden_dim, reduce_dim, bias=False)
self.reduce_bn = nn.BatchNorm1d(reduce_dim)
self.reduce_bn.bias.requires_grad_(False)
self.reduce_cls = nn.Linear(reduce_dim, model_cfg['class_num'], bias=False)
forward过程如下:
bn_feature = self.encoder_bn(feature.view(n, -1))
bn_feature = bn_feature.view(*feature.shape).contiguous()
reduce_feature = self.reduce_dp(bn_feature)
reduce_feature = self.reduce_ac(reduce_feature)
reduce_feature = self.reduce_fc(reduce_feature.view(n, -1))
bn_reduce_feature = self.reduce_bn(reduce_feature)
logits = self.reduce_cls(bn_reduce_feature).unsqueeze(1) # n c
reduce_feature = reduce_feature.unsqueeze(1).contiguous()
bn_reduce_feature = bn_reduce_feature.unsqueeze(1).contiguous()
Compact Block可以把三个stage的特征维度从 3 × 7936 = 23808 3\times7936=23808 3×7936=23808降到hidden_dim = 256。
四、GaitGL: Global and Local
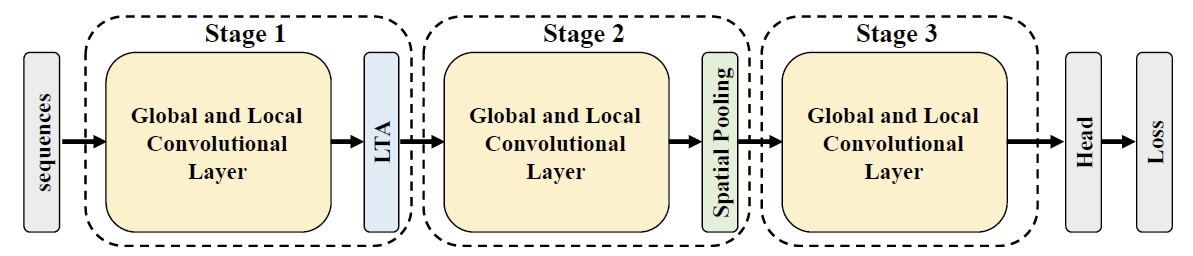
GaitGL有两套配置,分别用于数据集"OUMVLP and GREW",以及其他数据集。这两套配置主要结构都差多,只不过前者卷积层的数量会多一些。由于GaitGL使用3d卷积和池化来提取[s, h, w]三个维度的信息,所以backbone部分不需要SetBlockWrapper封装。
1,GLConv:提取时空特征

GLConv包含两个部分:global_conv3d和local_conv3d。global_conv3d直接用BasicConv3d(即nn.Conv3d)来提取全局特征,local_conv3d采用了和GaitPart中FocalConv类似的方式来提取局部特征(即在h维度进行划分,然后分块提取特征)。用相加或者拼接这两种方式来融合全局和局部特征。
class GLConv(nn.Module):
def __init__(self, in_channels, out_channels, halving, fm_sign=False, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False, **kwargs):
super(GLConv, self).__init__()
self.halving = halving
self.fm_sign = fm_sign
self.global_conv3d = BasicConv3d(
in_channels, out_channels, kernel_size, stride, padding, bias, **kwargs)
self.local_conv3d = BasicConv3d(
in_channels, out_channels, kernel_size, stride, padding, bias, **kwargs)
def forward(self, x):
'''
x: [n, c, s, h, w]
'''
gob_feat = self.global_conv3d(x)
if self.halving == 0:
lcl_feat = self.local_conv3d(x)
else:
h = x.size(3)
split_size = int(h // 2**self.halving)
lcl_feat = x.split(split_size, 3)
lcl_feat = torch.cat([self.local_conv3d(_) for _ in lcl_feat], 3)
if not self.fm_sign:
feat = F.leaky_relu(gob_feat) + F.leaky_relu(lcl_feat)
else:
feat = F.leaky_relu(torch.cat([gob_feat, lcl_feat], dim=3))
return feat
2,LTA: Local Temporal Aggregation
该模块就是一个Conv3d用于聚合相邻帧之间的特征,定义如下:
self.LTA = nn.Sequential(
BasicConv3d(in_c[0], in_c[0], kernel_size=(
3, 1, 1), stride=(3, 1, 1), padding=(0, 0, 0)),
nn.LeakyReLU(inplace=True)
)
3, Gait Recognition Head
head部分由时序特征池化TP、空间特征池化GeMHPP、以及SeparateFCs组成。TP和SeparateFCs结构与GaitSet一样,重点在于将HPP改为了GeMHPP。
motivation: HPP对所有数据集采用相同的处理方式(指按固定比例混合全局池化和平均池化),不能自适应处理。
method: 公式如下,通过参数p来自适应调整比例。当p=1,等价于平均池化;当p趋于无穷,等价于最大池化。 Y T F M Y_{TFM} YTFM表示TP后的特征。
Y S F M G e M = F G e M ( Y T F M ) F G e M ( Y T F M ) = ( F Avg 1 × 1 × 1 × W f m ( ( Y T F M ) p ) ) 1 p \begin{gathered} Y_{S F M}^{G e M}=F_{G e M}\left(Y_{T F M}\right) \\ F_{G e M}\left(Y_{T F M}\right)=\left(F_{\text {Avg }}^{1 \times 1 \times 1 \times W_{f m}}\left(\left(Y_{T F M}\right)^p\right)\right)^{\frac{1}{p}} \end{gathered} YSFMGeM=FGeM(YTFM)FGeM(YTFM)=(FAvg 1×1×1×Wfm((YTFM)p))p1
代码如下:做法和HPP差不多,先分成不同的part,然后再在每个part内进行池化。
class GeMHPP(nn.Module):
def __init__(self, bin_num=[64], p=6.5, eps=1.0e-6):
super(GeMHPP, self).__init__()
self.bin_num = bin_num
self.p = nn.Parameter(
torch.ones(1)*p)
self.eps = eps
def gem(self, ipts):
return F.avg_pool2d(ipts.clamp(min=self.eps).pow(self.p), (1, ipts.size(-1))).pow(1. / self.p)
def forward(self, x):
"""
x : [n, c, h, w]
ret: [n, c, p]
"""
n, c = x.size()[:2]
features = []
for b in self.bin_num:
z = x.view(n, c, b, -1)
z = self.gem(z).squeeze(-1)
features.append(z)
return torch.cat(features, -1)
从代码中可以看出,对于每个part,p的值是共享的。是否对于每个part用不同的p值会更好?不过按论文的说法,p是针对dataset的,所以同一个数据集内用同一个p就可以了。
4, forward
def forward(self, inputs):
ipts, labs, _, _, seqL = inputs
seqL = None if not self.training else seqL
if not self.training and len(labs) != 1:
raise ValueError(
'The input size of each GPU must be 1 in testing mode, but got {}!'.format(len(labs)))
sils = ipts[0].unsqueeze(1)
del ipts
n, _, s, h, w = sils.size()
if s < 3:
repeat = 3 if s == 1 else 2
sils = sils.repeat(1, 1, repeat, 1, 1)
outs = self.conv3d(sils)
outs = self.LTA(outs)
outs = self.GLConvA0(outs)
outs = self.MaxPool0(outs)
outs = self.GLConvA1(outs)
outs = self.GLConvB2(outs) # [n, c, s, h, w]
outs = self.TP(outs, seqL=seqL, options={"dim": 2})[0] # [n, c, h, w]
outs = self.HPP(outs) # [n, c, p]
gait = self.Head0(outs) # [n, c, p]
if self.Bn_head: # Original GaitGL Head
bnft = self.Bn(gait) # [n, c, p]
logi = self.Head1(bnft) # [n, c, p]
embed = bnft
else: # BNNechk as Head
bnft, logi = self.BNNecks(gait) # [n, c, p]
embed = gait
n, _, s, h, w = sils.size()
retval = {
'training_feat': {
'triplet': {'embeddings': embed, 'labels': labs},
'softmax': {'logits': logi, 'labels': labs}
},
'visual_summary': {
'image/sils': sils.view(n*s, 1, h, w)
},
'inference_feat': {
'embeddings': embed
}
}
return retval
五、SMPLGait:
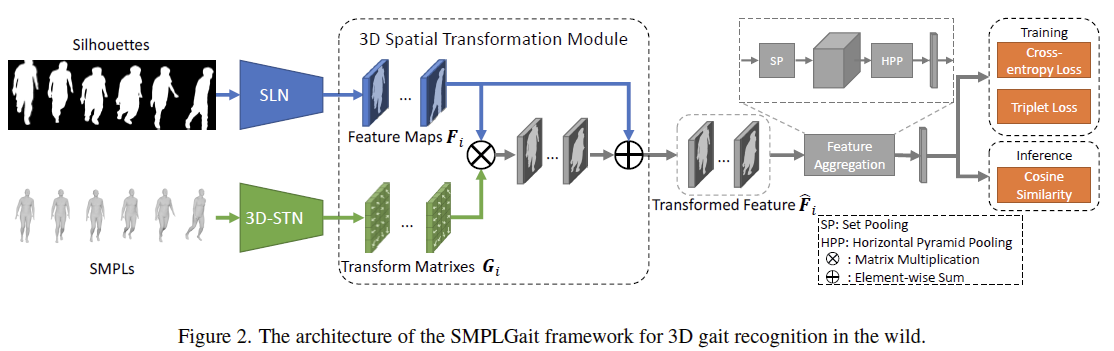
SMPLGait是一个多模态步态识别框架,利用silhouettes和SMPLs两种模态的信息来提取特征,分别对应于SLN和3D-STN模块。
1,SLN:Silhouette Learning Network
SLN网络和GaitSet类似,都是用Conv2d+Pooling来提取特征,因此需要用SetBlockWrapper封装。
self.Backbone = self.get_backbone(model_cfg['backbone_cfg'])
self.Backbone = SetBlockWrapper(self.Backbone)
2, 3D-STN: 3D Spatial Transformation Network
3D-STN由三个全连接层组成,用于把SMPL的输入从一维向量转为二位的特征图(input dimension->128->256->h*w)。
# for SMPL
self.fc1 = nn.Linear(85, 128)
self.fc2 = nn.Linear(128, 256)
self.fc3 = nn.Linear(256, 256)
self.bn1 = nn.BatchNorm1d(128)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(256)
self.dropout2 = nn.Dropout(p=0.2)
self.dropout3 = nn.Dropout(p=0.2)
3, 3D Spatial Transformation Module: 融合多模态特征
# extract SMPL features
smpls = ipts[1] # [n, s, d]
n, s, d = smpls.size()
sps = smpls.view(-1, d)
sps = F.relu(self.bn1(self.fc1(sps)))
sps = F.relu(self.bn2(self.dropout2(self.fc2(sps)))) # (B, 256)
sps = F.relu(self.bn3(self.dropout3(self.fc3(sps)))) # (B, 256)
sps = sps.reshape(n, 1, s, 16, 16)
iden = Variable(torch.eye(16)).unsqueeze(
0).repeat(n, 1, s, 1, 1) # [n, 1, s, 16, 16]
if sps.is_cuda:
iden = iden.cuda()
sps_trans = sps + iden # [n, 1, s, 16, 16]. I+G in paper
# extract SMPL features
sils = ipts[0] # [n, s, h, w]
outs = self.Backbone(sils) # [n, c, s, h, w]
outs_n, outs_c, outs_s, outs_h, outs_w = outs.size()
zero_tensor = Variable(torch.zeros(
(outs_n, outs_c, outs_s, outs_h, outs_h-outs_w)))
if outs.is_cuda:
zero_tensor = zero_tensor.cuda()
# [n, s, c, h, h] [n, s, c, 16, 16]
outs = torch.cat([outs, zero_tensor], -1) # zero padding on the short edge (i.e., w)
outs = outs.reshape(outs_n*outs_c*outs_s, outs_h,
outs_h) # [n*c*s, 16, 16]
sps = sps_trans.repeat(1, outs_c, 1, 1, 1).reshape(
outs_n * outs_c * outs_s, 16, 16) # repeat on the dimension c, i.e., 1->c
outs_trans = torch.bmm(outs, sps) # batch matrix multiplication
outs_trans = outs_trans.reshape(outs_n, outs_c, outs_s, outs_h, outs_h) # fused features
剩下的就是TP,HPP和SeparateFCs了。
六、GaitEdge
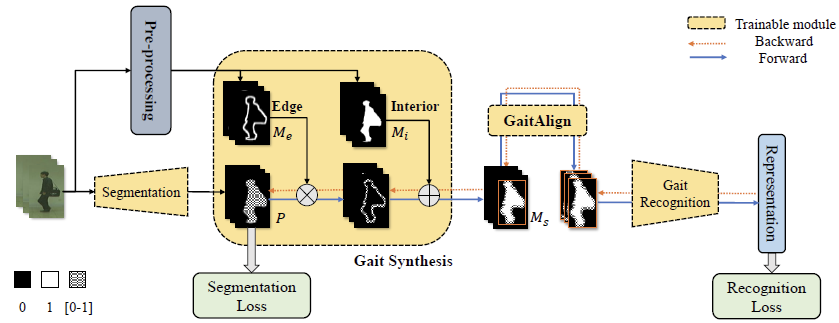
GaitEdge的网络由三个部分组成:Silhouette Segmentation网络, Gait Synthesis模块和Gait Recognition网络,训练也是分两阶段进行。Segmentation网络的主干为U-net,用于分割人体信息,训练损失为bce loss; Gait Synthesis模块用于对分割出的人体信息进行增强,Recognition网络的主干为GaitGL。
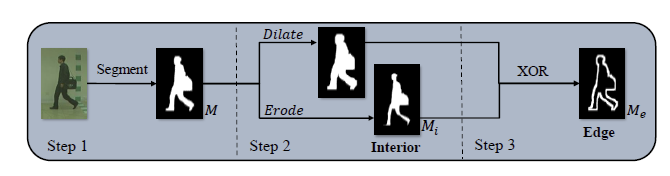
1,pre-process:提取边缘信息和内部信息
预处理过程旨在通过膨胀腐蚀等形态学操作来从轮廓图像中提取边缘信息和内部信息,如下图所示。公式中, M M M表示轮廓图, M e M_e Me表示边缘信息, M i M_i Mi是内部信息。
M
i
=
erode
(
M
)
M
e
=
M
i
∨
‾
dilate
(
M
)
\begin{aligned} & M_i=\operatorname{erode}(M) \\ & M_e=M_i \underline{\vee} \operatorname{dilate}(M) \end{aligned}
Mi=erode(M)Me=Mi∨dilate(M)
def preprocess(self, sils):
dilated_mask = (morph.dilation(sils, self.kernel.to(sils.device)).detach()
) > 0.5 # Dilation
eroded_mask = (morph.erosion(sils, self.kernel.to(sils.device)).detach()
) > 0.5 # Erosion
edge_mask = dilated_mask ^ eroded_mask
return edge_mask, eroded_mas
2, Gait Synthesis: 依据边缘信息和内部信息对分割出的人体信息进行增强
P
P
P是U-net分割结果,
M
s
M_s
Ms是Gait Synthesis的输出。
M
s
=
M
e
×
P
+
M
i
M_s=M_e \times P+M_i
Ms=Me×P+Mi
ratios = ipts[0]
rgbs = ipts[1]
sils = ipts[2]
n, s, c, h, w = rgbs.size()
rgbs = rgbs.view(n*s, c, h, w)
sils = sils.view(n*s, 1, h, w)
logis = self.Backbone(rgbs) # [n, s, c, h, w]
logits = torch.sigmoid(logis)
mask = torch.round(logits).float() # U-net segmentation result
if self.is_edge:
edge_mask, eroded_mask = self.preprocess(sils)
# Gait Synthesis
new_logits = edge_mask*logits+eroded_mask*sils
3, Gait Align
Gait Align模块用于将增强后的人体信息与轮廓图进行对齐,代码如下:
self.gait_align = GaitAlign()
# forward
ratios = ipts[0]
cropped_logits = self.gait_align(new_logits, sils, ratios)
GaitAlign的定义如下:

class GaitAlign(nn.Module):
"""
GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality
ECCV2022: https://arxiv.org/pdf/2203.03972v2.pdf
Github: https://github.com/ShiqiYu/OpenGait/tree/master/configs/gaitedge
"""
def __init__(self, H=64, W=44, eps=1, **kwargs):
super(GaitAlign, self).__init__()
self.H, self.W, self.eps = H, W, eps
self.Pad = nn.ZeroPad2d((int(self.W / 2), int(self.W / 2), 0, 0))
self.RoiPool = RoIAlign((self.H, self.W), 1, sampling_ratio=-1)
def forward(self, feature_map, binary_mask, w_h_ratio):
"""
In sils: [n, c, h, w]
w_h_ratio: [n, 1]
Out aligned_sils: [n, c, H, W]
"""
n, c, h, w = feature_map.size()
# w_h_ratio = w_h_ratio.repeat(1, 1) # [n, 1]
w_h_ratio = w_h_ratio.view(-1, 1) # [n, 1]
h_sum = binary_mask.sum(-1) # [n, c, h]
_ = (h_sum >= self.eps).float().cumsum(axis=-1) # [n, c, h]
h_top = (_ == 0).float().sum(-1) # [n, c]
h_bot = (_ != torch.max(_, dim=-1, keepdim=True)
[0]).float().sum(-1) + 1. # [n, c]
w_sum = binary_mask.sum(-2) # [n, c, w]
w_cumsum = w_sum.cumsum(axis=-1) # [n, c, w]
w_h_sum = w_sum.sum(-1).unsqueeze(-1) # [n, c, 1]
w_center = (w_cumsum < w_h_sum / 2.).float().sum(-1) # [n, c]
p1 = self.W - self.H * w_h_ratio
p1 = p1 / 2.
p1 = torch.clamp(p1, min=0) # [n, c]
t_w = w_h_ratio * self.H / w
p2 = p1 / t_w # [n, c]
height = h_bot - h_top # [n, c]
width = height * w / h # [n, c]
width_p = int(self.W / 2)
feature_map = self.Pad(feature_map)
w_center = w_center + width_p # [n, c]
w_left = w_center - width / 2 - p2 # [n, c]
w_right = w_center + width / 2 + p2 # [n, c]
w_left = torch.clamp(w_left, min=0., max=w+2*width_p)
w_right = torch.clamp(w_right, min=0., max=w+2*width_p)
boxes = torch.cat([w_left, h_top, w_right, h_bot], dim=-1)
# index of bbox in batch
box_index = torch.arange(n, device=feature_map.device)
rois = torch.cat([box_index.view(-1, 1), boxes], -1)
crops = self.RoiPool(feature_map, rois) # [n, c, H, W]
return crops
最终将cropped_logits送入GaitGL进行步态识别。
七、GaitBase
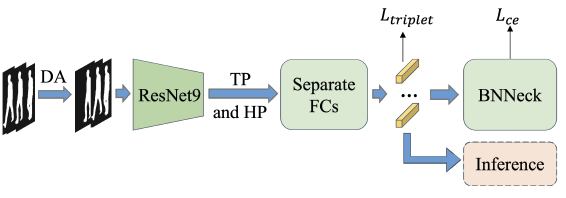
GaitBase是OpenGait中的Baseline,其用很简单的模型,在多个数据集上取得了很好的效果。
1, backbone: ResNet-9
GaitBase的backbone采用ResNet-9并用SetBlockWrapper封装。
2, TP和HPP
TP、HPP模块与GaitSet相同。
3,BNNeck
BNNeck是在特征层之后、分类层FC层之前添加一个BN(batch normalization)层,BN层之前的特征表示为 embed1 , embed1 经过BN层归一化之后得到特征 embed2 ,分别用 embed1和 embed2去计算triplet loss和CE loss。代码如下:
class SeparateBNNecks(nn.Module):
"""
Bag of Tricks and a Strong Baseline for Deep Person Re-Identification
CVPR Workshop: https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdf
Github: https://github.com/michuanhaohao/reid-strong-baseline
"""
def __init__(self, parts_num, in_channels, class_num, norm=True, parallel_BN1d=True):
super(SeparateBNNecks, self).__init__()
self.p = parts_num
self.class_num = class_num
self.norm = norm
self.fc_bin = nn.Parameter(
nn.init.xavier_uniform_(
torch.zeros(parts_num, in_channels, class_num)))
if parallel_BN1d: # 为True,则BN在不同part之间共享
self.bn1d = nn.BatchNorm1d(in_channels * parts_num)
else:
self.bn1d = clones(nn.BatchNorm1d(in_channels), parts_num)
self.parallel_BN1d = parallel_BN1d
def forward(self, x):
"""
x: [n, c, p]
"""
if self.parallel_BN1d:
n, c, p = x.size()
x = x.view(n, -1) # [n, c*p]
x = self.bn1d(x)
x = x.view(n, c, p)
else:
x = torch.cat([bn(_x) for _x, bn in zip(
x.split(1, 2), self.bn1d)], 2) # [p, n, c]
feature = x.permute(2, 0, 1).contiguous()
if self.norm:
feature = F.normalize(feature, dim=-1) # [p, n, c]
logits = feature.matmul(F.normalize(
self.fc_bin, dim=1)) # [p, n, c]
else:
logits = feature.matmul(self.fc_bin)
return feature.permute(1, 2, 0).contiguous(), logits.permute(1, 2, 0).contiguous()


![[Qt]事件](https://img-blog.csdnimg.cn/4022d6871f494e16acb2cc5486b09930.png)




![深度学习-卷积神经网络-卷积图像去噪边缘提取-图像去噪 [北邮鲁鹏]](https://img-blog.csdnimg.cn/364f66a79e0546ddafbdcdc104d4fea0.png)