在本教程中,我们将抓取一个网站并使用自然语言处理来分析文本数据。
最终结果将是对网站内容的情感分析。以下是我们将遵循的步骤:
- 项目范围
- 所需的库
- 了解网页抓取
- 抓取网站
- 文本清理和预处理
- 使用机器学习进行情感分析
- 最后结果
一、项目范围
该项目的目标是抓取网站,执行文本预处理,然后应用机器学习算法对网站内容进行情感分析。
换句话说,我们想要确定网站上的文本内容是否具有积极、消极或中性的情绪。
为了实现这一目标,我们将使用 Python 和一些库来执行网络抓取和机器学习。
2. 所需的库
该项目需要以下库:
- requests:向网站发出 HTTP 请求
- BeautifulSoup:解析 HTML 和 XML 文档
- pandas:使用数据框
- nltk:执行自然语言处理
- scikit-learn:训练机器学习模型
您可以使用 pip 安装这些库:
pip install requests beautifulsoup4 pandas nltk scikit-learn
3. 了解网页抓取
网络抓取是从网站提取数据的过程。这可以手动完成,但对于大量数据来说并不实用。
因此,我们使用软件来自动化该过程。在 Python 中,我们使用requests 和 BeautifulSoup 等库来抓取网站。
网页抓取有两种类型:
- 静态抓取:我们抓取具有固定内容的网站
- 动态抓取:我们抓取内容经常更改或动态生成的网站
对于这个项目,我们将执行静态抓取。
4. 抓取网站
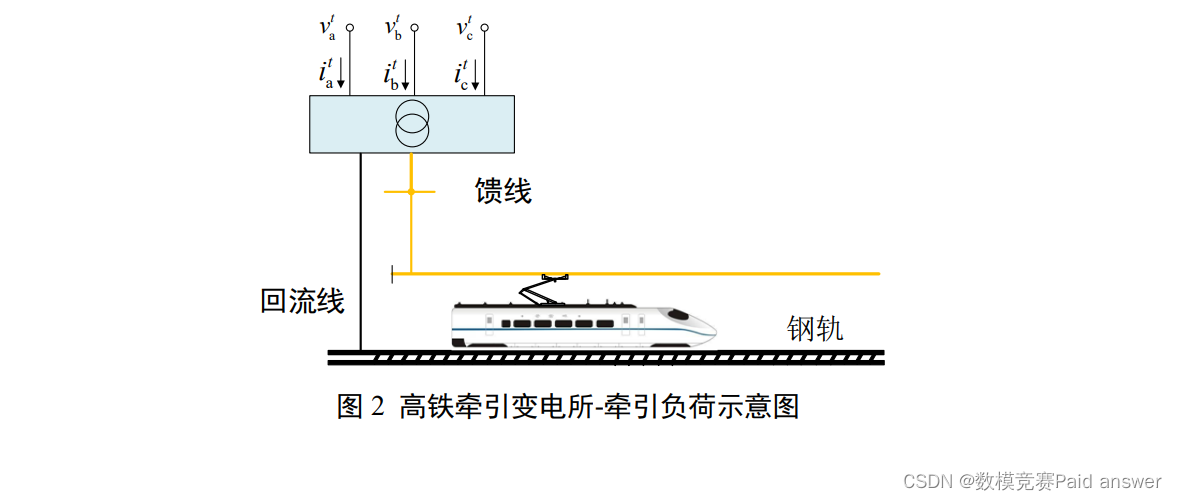
首先,我们需要找到一个要抓取的网站。在本教程中,我们将从BBC 新闻中抓取新闻文章。我们将删除网站的“技术”部分。
这是抓取网站的代码:
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news/technology"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
articles = soup.find_all("article")
for article in articles:
headline = article.find("h3").text.strip()
summary = article.find("p").text.strip()
print(headline)
print(summary)
print()让我们分解一下这段代码:
- 我们首先导入 requests 和 BeautifulSoup 库
- 我们定义要抓取的网站的 URL
- 我们使用requests.get()向网站发出HTTP请求并获取HTML内容
- 我们从 HTML 内容创建一个 BeautifulSoup 对象
- 我们使用find_all()来获取页面上的所有文章
- 我们循环浏览每篇文章并提取标题和摘要
- 我们打印每篇文章的标题和摘要
当我们运行这段代码时,我们应该看到控制台中打印的文章的标题和摘要。
5. 文本清理和预处理
在进行情感分析之前,我们需要清理和预处理文本数据。这涉及以下步骤:
- 删除 HTML 标签
- 将所有文本转换为小写
- 删除标点符号
- 删除停用词(常见词,如“the”、“a”、“an”等)
- 对文本进行词干化或词形还原(将单词还原为其词根形式)
这是执行文本清理和预处理的代码:
import re
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from nltk.tokenize import word_tokenize
stemmer = SnowballStemmer("english")
stop_words = set(stopwords.words("english"))
def clean_text(text):
# Remove HTML tags
text = re.sub(r"<.*?>", "", text)
# Convert to lowercase
text = text.lower()
# Remove punctuation
text = re.sub(r"[^\w\s]", "", text)
# Remove stopwords and stem words
tokens = word_tokenize(text)
tokens = [stemmer.stem(word) for word in tokens if word not in stop_words]
# Join tokens back into a string
text = " ".join(tokens)
return text让我们分解一下这段代码:
- 我们首先导入正则表达式库 (re)、NLTK 库中的停用词语料库和 SnowballStemmer,以及 nltk.tokenize 模块中的 word_tokenize 函数。
- 我们定义一个 SnowballStemmer 对象,并将语言设置为“english”,该对象将用于词干
- 我们定义一组要从文本数据中删除的停用词
- 我们定义一个名为 clean_text() 的函数,它接受文本字符串
- 在函数内部,我们使用正则表达式来删除任何 HTML 标签
- 我们使用 lower() 方法将文本转换为小写
- 我们使用正则表达式删除标点符号
- 我们使用 nltk.tokenize 模块中的 word_tokenize() 方法将文本标记为单个单词。
- 我们使用 SnowballStemmer 对象对每个单词进行词干分析并删除停用词。
- 最后,我们使用 join() 方法将词干词重新连接回字符串。
6. 使用机器学习进行情感分析
现在我们已经清理并预处理了文本数据,我们可以使用机器学习进行情感分析。
我们将使用scikit-learn 库来执行情感分析。
首先,我们需要将数据分为训练集和测试集。我们将使用80% 的数据进行训练,20% 的数据进行测试。
这是分割数据的代码:
from sklearn.model_selection import train_test_split
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df["text"], df["sentiment"], test_size=0.2, random_state=42)让我们分解一下这段代码:
- 我们从 scikit-learn 导入 train_test_split() 函数
- 我们使用 train_test_split() 函数将文本数据(存储在数据框的“text”列中)和情感数据(存储在数据框的“sentiment”列中)分成训练集和测试集。
- 我们使用 test_size 为 0.2,这意味着 20% 的数据将用于测试,并使用 random_state 为 42 以实现可重复性。
接下来,我们需要将文本数据转换为可用作机器学习算法的输入的数值向量。
我们将使用TF-IDF 矢量器来执行此操作。
这是转换文本数据的代码:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(ngram_range=(1,2))
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)让我们分解一下这段代码:
- 我们从 scikit-learn 导入 TfidfVectorizer 类
- 我们创建一个 TfidfVectorizer 对象并将 ngram_range 设置为 (1,2),这意味着我们要考虑文本数据中的一元组(单个单词)和二元组(相邻单词对)。
- 我们使用 fit_transform() 方法在训练数据上拟合向量化器,该方法计算语料库中每个单词的 TF-IDF 分数,并将文本数据转换为数值特征的稀疏矩阵。
- 我们使用transform()方法转换测试数据,该方法使用从训练数据中学习的词汇对测试数据应用相同的转换。
现在我们已经将文本数据转换为数字特征,我们可以训练机器学习模型来预测文本的情感。
我们将使用逻辑回归算法,这是文本分类任务的流行算法。
这是训练模型的代码:
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train_vec, y_train)让我们分解一下这段代码:
- 我们从 scikit-learn 导入 LogisticRegression 类
- 我们创建一个 LogisticRegression 对象并将 max_iter 设置为 1000,这意味着我们允许算法运行最多 1000 次迭代来收敛。
- 我们使用 fit() 方法在训练数据上训练模型,该方法学习可用于预测新文本数据的情绪的模型参数。
最后,我们可以通过计算准确率得分、精确率、召回率和 F1 得分来评估模型在测试数据上的性能。
这是评估模型的代码:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
y_pred = clf.predict(X_test_vec)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average="macro")
recall = recall_score(y_test, y_pred, average="macro")
f1 = f1_score(y_test, y_pred, average="macro")
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 score:", f1)让我们分解一下这段代码:
- 我们从 scikit-learn 导入 precision_score、 precision_score、recall_score 和 f1_score 函数
- 我们使用LogisticRegression对象的predict()方法来预测测试数据的情绪
- 我们使用 scikit-learn 中的相应函数计算模型的准确率、精确率、召回率和 F1 分数
- 我们打印性能指标。
就是这样!我们已经使用 Python 中的机器学习成功地执行了网页抓取、文本清理、预处理和情感分析。


![[C++基础]-stack和queue](https://img-blog.csdnimg.cn/a13d2877a7ac450aa7e7082816304b9f.png)