0 提纲
- 概述
- SQL注入方法
- SQL注入的检测方法
- SQL语句的特征提取
- 天池AI上的实践
1 概述
SQLIA:SQL injection attack SQL 注入攻击是一个简单且被广泛理解的技术,它把 SQL 查询片段插入到 GET 或 POST 参数里提交到网络应用。
由于SQL数据库在Web应用中的普遍性,使得SQL攻击在很多网站上都可以进行。并且这种攻击技术的难度不高,但攻击变换手段众多,危害性大,使得它成为网络安全中比较棘手的安全问题。
1.1 当前发展水平与现状
SQLIA 被大量关注并有丰富的文献
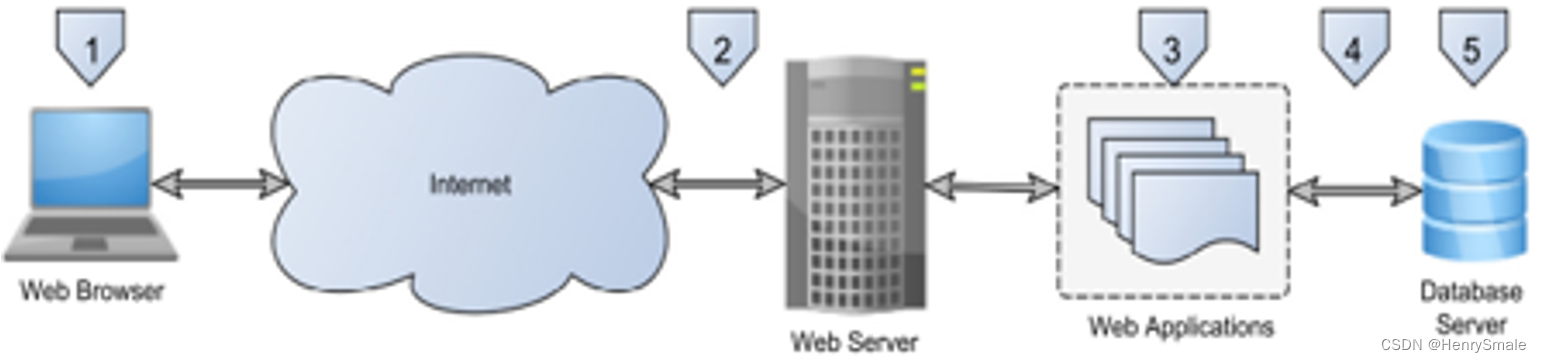
基于端到端的网站应用架构的 5 个关键层简要回顾现有途径,并给出解决方案提议:
- 客户端
- 网络应用防火墙(WAF)
- 网络应用
- 数据库防火墙
- 数据库服务器
2 SQL注入方法
发生于Web+数据库的应用架构中
Web页面存在注入点,如一个登录页面:
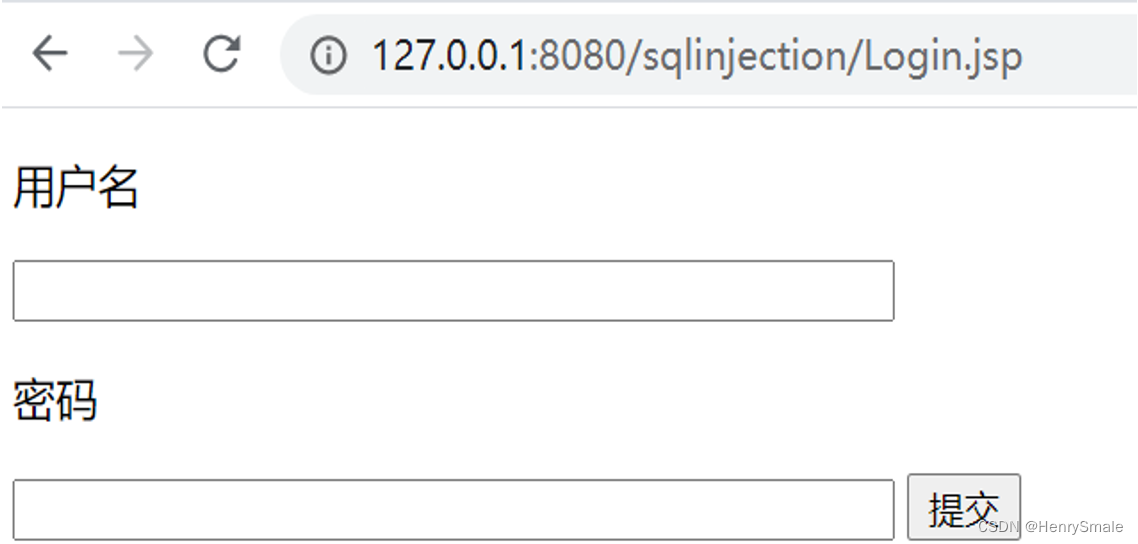
假如对登录用户身份进行合法性验证的SQL语句为:
select * from user where name = ‘{$name}’ and password ={$password}
攻击者即使没有该网站的用户账号和密码,但是他也可能绕过账号验证而获得相应登录权限。只需在登录提交表单中,密码框输入1 or 2=2从而生成如下的注入SQL。此时登录验证的SQL语句被攻击者构造为:
select * from users where username='asndfas' and passwd=1 or 2=2
在密码框中输入2345; drop table tmp,从而形成了如下的注入SQL,其中注入的分号是将SQL指令分成多条指令执行。
select * from users where username='bbb' and passwd=2345; drop table tmp
由此会产生严重的数据库安全问题。
3 SQL注入的检测方法
SQL注入的检测通常要对输入的内容进行校验,其中较为有效的是对请求数据格式或者内容进行规则处理。目前主要的检测方法有:
- 针对特定类型的检查;
- 对特定格式的检查;
- SQL预编译的防御方法;
- 机器学习方法。
4 SQL语句的特征提取
SQL的表示:
- 对SQL语句采用N-Grams表示
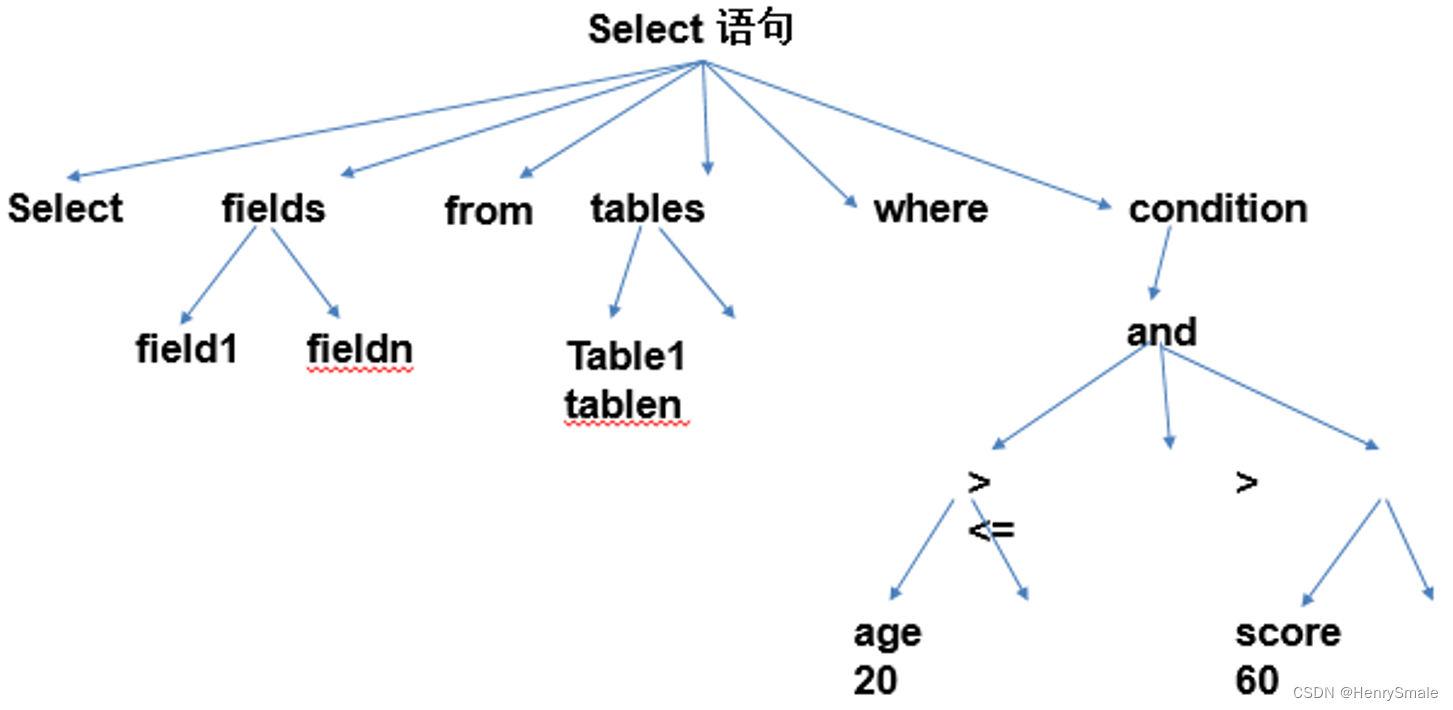
- 语法树的表示形式
4.1 标记图的方式及思路
定义SQL语句中的标记(Token),把SQL中的关键字、标识符、操作符、分隔符、变量以及其他符号都称为标记。
一条SQL查询,无论是真正的查询还是注入的查询,都是一个标记序列。
检测的基本思路就是,对真正查询和注入查询的序列进行特征提取,然后在特征空间中构建识别注入查询的分类器模型。
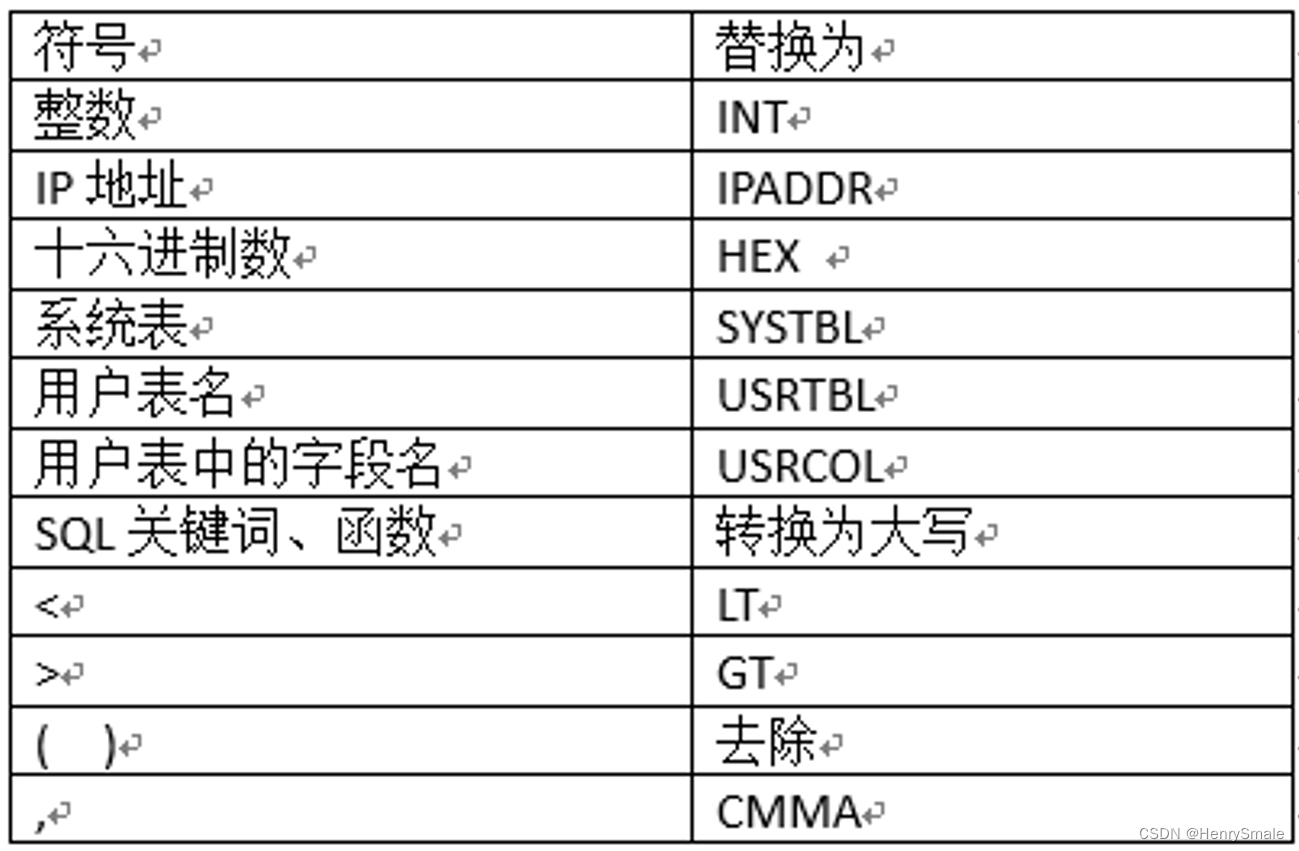
定义映射表
两个例子:
(1)
select * from books where price>20.5 and discount<0.8
规范化为:
SELECT STAR FROM USRTBL WHERE USRCOL GT DEC AND USRCOL LT DEC
(2)
select count(*), sum(amount) from orders order by sum(amount)
规范化为:
SELECT COUNT STAR CMMA SUM USRCOL FROM USRTBL ORDER BY SUM USRCOL
对规范化后的序列,构造标记图:
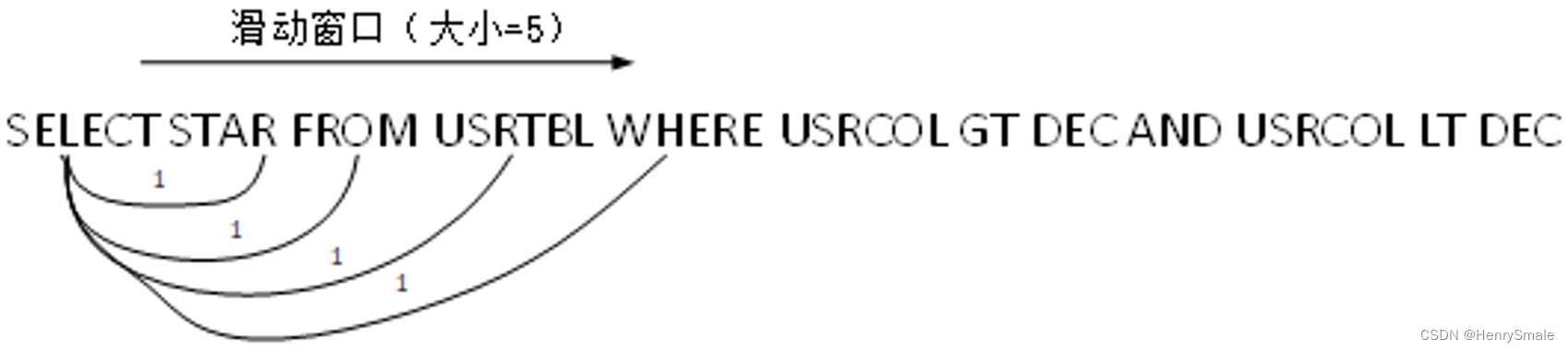
可以构造的图种类包括:有向图/无向图, 含权图/无权图。
上面例子每个边的权重置为1, 生成的是无权图。
最终,对一个SQL查询可以转换成为标记图:
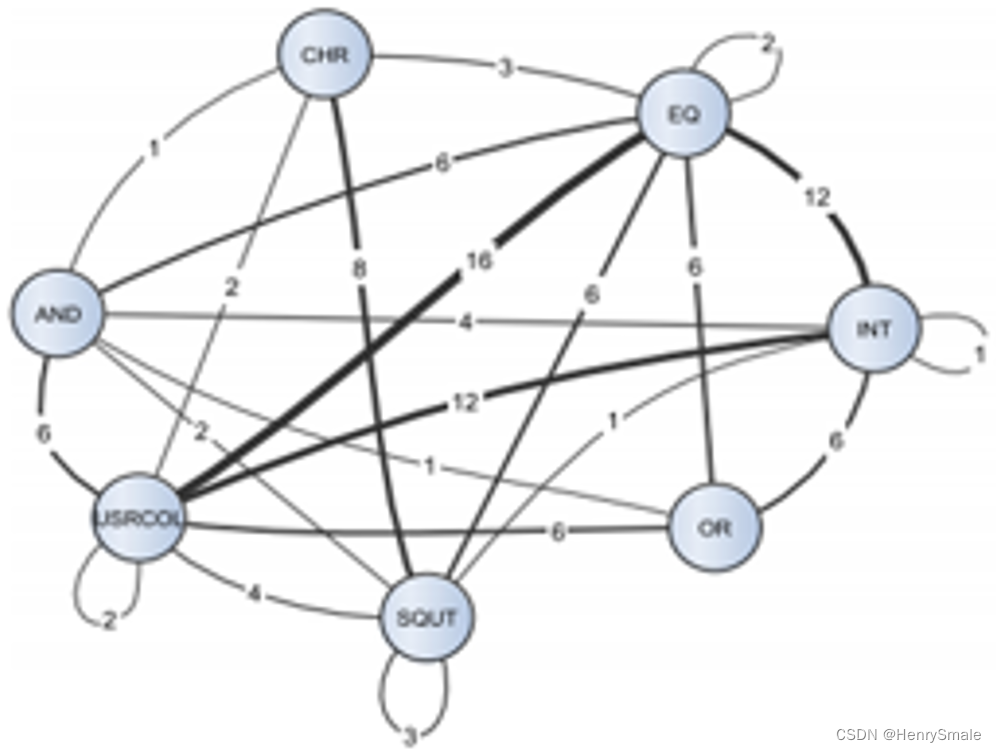
进一步对该图提取特征,可以是节点的度/入度/出度/紧密度等,从而将一个查询转换成为SQL标记的特征向量。而后可以使用各类分类器进行训练。
4.2 文本分析的思路
由于注入内容是一种文本信息,其语法基本遵循SQL语言,而非扎乱无章的内容。从这点看,它与自然语言类似。因此,可以尝试按照自然语言文本分类的方式来进行SQL注入的检测。
把SQL语句注入的请求信息进行分割,按照逻辑顺序进行切分,在逻辑上存在间隔的地方加上空格。 例如:
--post-data "Login='and'1'='1~~~&Password='and'1'='1~~~&ret_page='and'1'='1~~~&qu erystring='and'1'='1~~~&FormAction=login&FormName=Login"
转化为:
“-post-data "Login=' and '1'='1~~~&Password=' and '1'='1~~~&ret_page=' and '1'='1~~~&querystring=' and '1'='1~~~&FormAction=login&FormName=Login”
接下来,采用普通的文本分类技术,使用信息增益、方差阈值等特征选择方法选择有利于分类的Top K个特征,从而完成文本向量空间的构建。
从文本的角度,当然也可以把文本分类中的经典神经网络用来进行SQL注入的检测。例如Text CNN等。
5 天池AI上的实践
数据集是来自一个网站收集的链接请求,只有normal/attack两类,分别对应于标签0/1。该数据集共480条记录,有注入记录339条,正常记录141条。以下两条记录分别是注入和非注入样本。
基本思路是,把整个训练文本集进行切分,转换称为tf-idf向量,然后使用各类分类器进行训练和测试。
(1)数据处理部分
‘’’
train_data = pd.read_csv(“train.txt”, header = None, sep = “,”)
test_data = pd.read_csv(“test.txt”, header = None, sep = “,”)
train_data.dropna(inplace = True) #删除有缺失值的行
test_data.dropna(inplace = True)
(2)文本-向量转换处理,使用sklearn提供的TfidfVectorizer完成向量表示。
(3)构建分类器,测试性能
- 可以实现神经网络模型等更多分类器进行测试
在线实验入口:
https://tianchi.aliyun.com/course/990