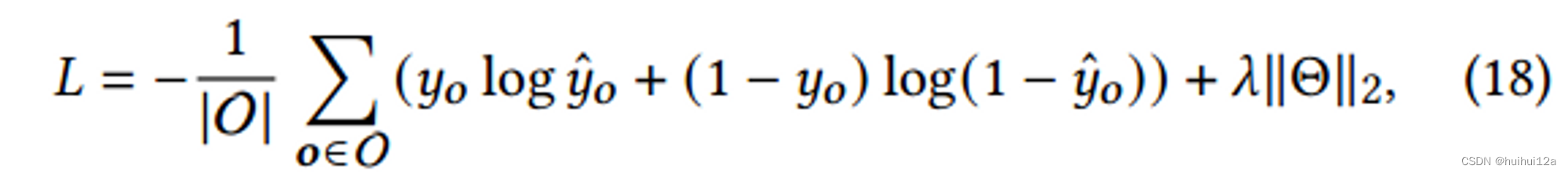对于任何想要尝试人工智能或本地LLM,又不想因为意外的云账单或 API 费用而感到震惊的人,我可以告诉你我自己的旅程是如何的,以及如何开始使用廉价的消费级硬件执行Llama2 推理 。
这个项目一直在以非常活跃的速度发展,这使得它非常令人兴奋。 这也意味着你在这里阅读的任何内容都可能会发生变化,就像我使用的有缺陷的模型转换一样,它产生了上面Llama喝醉似的响应。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
1、简介
虽然没有得到很好的宣传,但在过去的十年里,Meta 已经悄悄地为世界做出了至少四个最具革命性的开源项目。 首先是 Zstd 压缩。 这种更快、更优越的压缩算法已经使 2015 年以来保存的任何 ZIP 文件变得过时。第二和第三个是通过开放媒体联盟的合作,即媒体压缩编解码器 Opus 和 AV1,没有它们,现代全球 4K 流媒体将无法实现。 几乎不可能。 我喜欢的第四个也是最近的贡献是超便携的 Llama LLM 及其相关的训练模型。 模型训练是迄今为止LLM中最棘手和资源最密集的过程,这就是为什么提供原始模型如此有用。
谷歌几年前发布了他们的开源 TensorFlow 项目,但大多数人只能训练自己的模型,这并不容易。 通过推理使用公开可用的生态系统模型实际上更容易,并且可以在商品计算资源或 GPU 上执行。 理论上,任何与 OpenCL CLBLAST 库兼容的东西都可以做到这一点。 此版本的 llama.cpp 统一支持 CPU 和 GPU 硬件。 请注意,我们将使用主分支的构建,该分支被视为测试版,因此可能会出现问题。
将这些公开并可供任何人使用,使得通过LLM推理来建立自己的人工智能实验室以获取本地帮助变得非常简单。 甚至不需要市场上很难找到的最新 GPU 或资源,你可以使用廉价的二手技术来运行这些。 其中很大一部分灵感来自于 Chandler Lofland 的精彩文章“How to Run Llama 2 on Anything”,但我将尝试通过为 Fedora Linux 预先打包高性能 llama.cpp 存储库来进一步简化事情。
Fedora 仍然是大多数基于 RPM 的发行版的上游,包括 Red Hat Enterprise Linux 以及 Amazon Linux、Oracle Linux、Rocky、前 CentOS、Scientific Linux 和 Fermi Linux 等衍生产品。 这意味着 Fedora 中的 RPM 打包会渗透到这些发行版中,这是一个如何为未来环境准备版本的旅程。 由于这个项目进展如此之快,很难跟上,而且大多数用户不想每次发生变化时都自己编译东西。 我的专长之一一直是上游项目的包自动化。 这是从提交到生产服务器的前沿比特之旅,如果你确实计划在生产中使用它,我建议你使用强化的 Enterprise Linux,而不是我在上游使用的前沿 Fedora。
虽然上一篇文章提到在 MacBook 上为单个用户运行 Llama,但我将从服务器级工作站上的服务器角度来解决这个问题。 目的是构建一个可重复的环境,团队中的客户可以在云或本地连接和共享。 你还可以尝试公共沙箱,根据我的经验,它的性能非常好。
值得注意的是,Llama2 有两个组件:应用程序和数据。 运行 Llama2 的官方方式是通过 Python 应用程序,但 C++ 版本显然更快、更高效,因为 RAM 是你在尝试使用 CPU 或 GPU 运行 Llama2 服务时会发现的最关键组件。
就我而言,工作站在 2 插槽 HP Z840 上以一半容量运行,配备 512GB DDR4 LRDIMM。 仅使用 CPU 可以访问更多 RAM,但 CPU 推理速度较慢,尤其是当 RAM 需要在插槽之间交换时。 此外,LRDIMM 的速度比常规 RDIMM 稍慢,但代价是容量更高。 通常我建议禁用 NUMA,因为通过内存给予 CPU 插槽优先权通常会导致一个 CPU 过热,直到它减慢到不切实际的速度。 在这种情况下,LLM 是一种 CPU 工作负载,可以从某些 NUMA 调整中受益(Llama.cpp 确实支持 NUMA 标志),但大多数人无论如何都希望使用 GPU。
在编写本文时,常见的 GGML 模型文件格式已被弃用并被 GGUF 取代,这有点延迟了。 GGUF格式是优越的,也是未来的,但有些模型需要重新转换或重新下载。 这是一个不断变化的目标,甚至转换器也无法处理我的大部分 GGML 文件。 好消息是 GGUF 文件要小得多,并且在磁盘上压缩得更少,因此它们肯定比较大的 GGML 文件更高效。 坏消息是 CodeLlama 恰好在同一时间发布,这一变化的引入让我的速度慢了很多。 在复杂模型格式的斗争中,我意识到轻松识别哪些文件是什么格式以及哪个版本将很有帮助。 为了在测试过程中保持一切正常,我制作了一个临时魔术文件来识别模型。 然后通过 PR 我发现这个项目的社区非常活跃而且非常友好。 我们还一起正式提交了正确的 MIME 提交。
jboero@xps ~/Downloads> file *llama*
codellama-7b.Q8_0.gguf: GGUF LLM model version=1
llama-2-7b.ggmlv3.q8_0.bin: GGML/GGJT LLM model version=3
llama-cpp.srpm.spec: ASCII text
CodeLlama 主要作为三种不同的模型发布,范围包括 7B、13B 和 34B 参数数量的训练。 即使是 7B 型号也非常强大,可以在小型笔记本电脑上轻松运行。
2、性能表现
GPU 实际上是可选的,但我已经更换了旧的 Nvidia 卡,因此我运行的是 16GB 的工作站级 A4000 和 12GB 的消费级 4070ti。
任何生产 AI 部署都应使用带有 ECC RAM 的服务器或工作站级 GPU,例如 A4000。 如果没有检查 RAM 的 ECC,请勿在旧的挖矿或游戏 CPU 或 GPU 上运行重要的 LLM。 服务器级 GPU 的速度更快的 HBM2/HBM3 RAM 将比商用硬件中的 DDR/GDDR 提供更快的体验,因为模型的下一个权重或张量的访问延迟始终对性能至关重要。
除了 CPU 之外,GPU 可以自由选择自己的 RAM 速度和总线,这是它们制造如此重要的协处理器的原因之一。 如果你不熟悉通用或 GPGPU 的历史,请参阅我之前的系列 All Things GPU 了解背景知识。
我们有足够的 GPU 内存来以全性能加载大部分 13B Llama2 模型,CPU 内存足以测试大型 70B 模型。 那么让我们来试驾一下吧。
首先,如果没有快速连接,下载模型可能会令人畏惧。 它们很大,如果你把它们全部拿走,目前未压缩的话大约有 200GB 以上。 如果你需要在格式之间进行转换,还需要额外的空间。 对于这种类型的存储,你可能需要固态硬件,但在生产中只需要启动该服务。
我发现 Fedora 38 的 btrfs 文件系统及其 zstd 压缩选项有很大的好处。 根据我的经验,默认的 compress=zstd:1 是不够的,内核决定不压缩太多,这是愚蠢的,因为大多数内容实际上是高度可压缩的,具体取决于你需要的转换格式。 用 force-compress=zstd:1替换mount选项要好得多,需要磁盘上46%的实际空间,几乎没有CPU开销。 由于这是只读数据,因此非常完美,如 70B 聊天模型的副本所示:
sudo compsize llama-2-70b-chat/
Processed 3 files, 2105004 regular extents (2105004 refs), 2 inline.
Type Perc Disk Usage Uncompressed Referenced
TOTAL 46% 120G 256G 256G
zstd 46% 120G 256G 256G
3、对 CodeLlama 的初步想法
我对 Llama2 的主要兴趣是通过 Llama 插件添加对我的 AI Shell 项目的支持,因此我将通过简单的 bash 测试来试用它。 我喜欢面向代码的 LLM 只向我显示城市的当前时间,所以让我们尝试使用 CPU 服务器上的基本 34B CodeLlama 模型。
启动服务器非常简单,指定 host :: 来侦听任何 IPv4 或 IPv6 地址(请注意,尚不支持 TLS!)。 我的模型通过强制 zstd 压缩保存到备份磁盘。 一旦加载到磁盘缓存中,然后加载到服务或 GPU 内存中,读取速度就不再重要了。
llamaserver --host :: -m /mnt/backup/llama/codellama-34b.gguf
这为远程连接提供了方便的 Web 界面,可以快速轻松地测试驱动 CodeLlama。 注意 Llama.cpp 不是这些模型的唯一运行时。 出现了一个完整的项目生态系统,为 Llama 推理提供 UI 或 REST API 服务。 Llama.cpp 中的简单 UI 使用自己的 API,非常简单且未经身份验证。 使用 TLS 客户端证书或外部身份验证方法进行代理包装非常简单,但我预计很快就会添加一些内容。
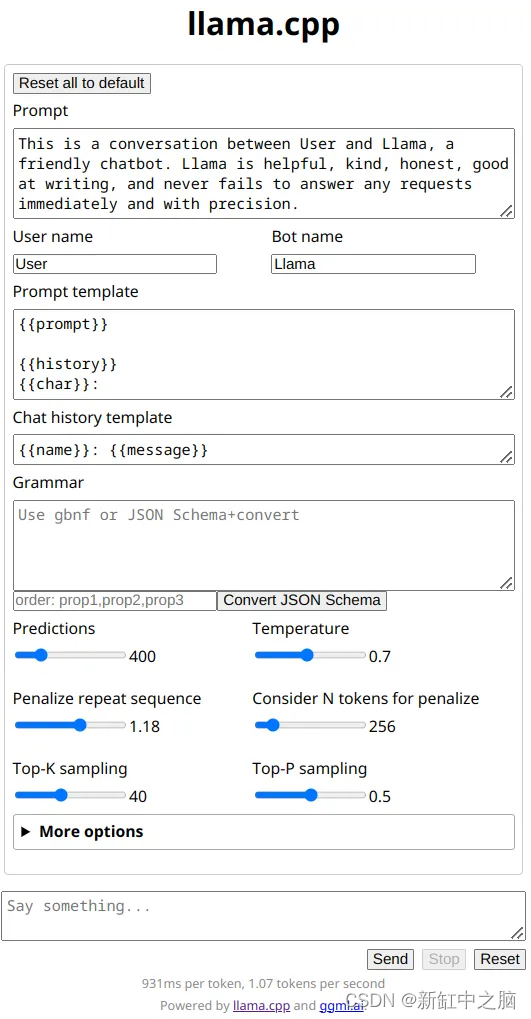
我会要求它编写一个 bash 脚本或函数来告诉我迪拜的当前时间。 这往往与 Google 的 Bison 编码模型配合得非常好。 此时,我的首选litmus测试揭示了转换后的模型中的错误。 这些错误已在上游项目中修复。
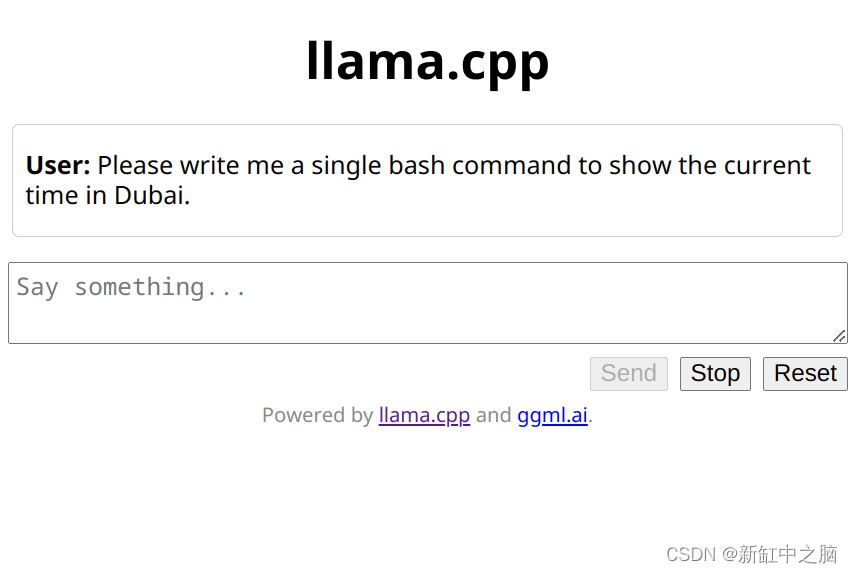
好吧,这还不是我所说的生产级 Llama。 这是由于与 GGUF 格式发布同时发生的模型转换错误引起的,我在尝试排除故障时浪费了一天的时间。 有一个参数应该惩罚这样的重复,但它没有任何效果,使 Codellama 模型有效地表现为手机键盘上的美化文本预测。
首先,我需要使用修补的转换脚本将原始 GGML 格式的模型重新转换为 GGUF。 然后调整一些参数和提示,看看能不能做得更好。 服务器控制台中的默认设置肯定不是我们需要的。 最重要的是,这个模型的温度似乎特别敏感,所以让我们尝试一下它。
接下来我将温度降低到 0.5,但这显然还不够。 这里仍然有太多的创作自由,以至于 Llama 出于某种原因称我为“buddykins”。 进一步降低温度 0.1 并使用公共沙箱环境中的设置给出了我想要看到的结果。 看来 CodeLlama 模型不会影响温度,这是有道理的。 代码编写是一种相当严格的语法,没有留下太多随机性或创造力的空间。
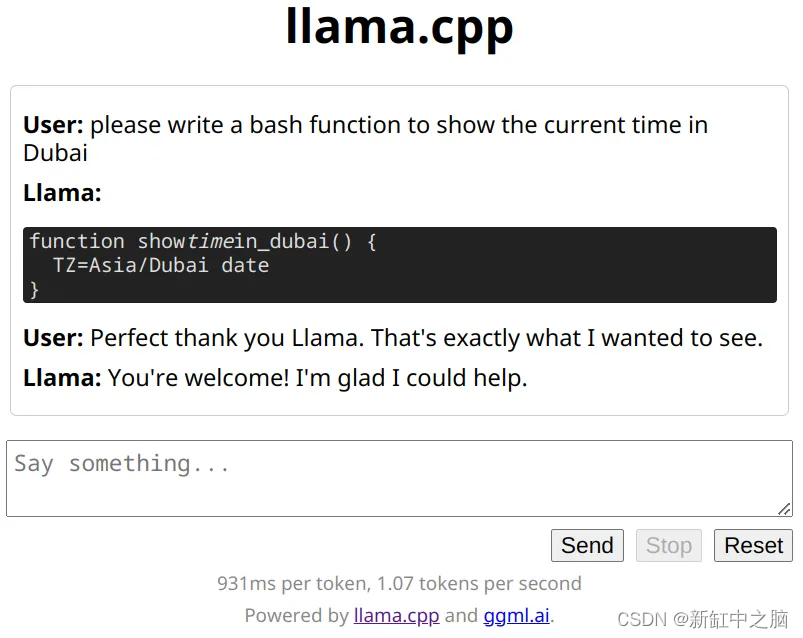
这个示例更能满足我自己的需求。 这正是 aish 可以用来将简单请求直接透明地转换为环境中的本地操作的输出类型。 请注意,我绝对不建议这样做 - 这样做需要你自担风险或冒险。 有时Llama需要一些哄骗。
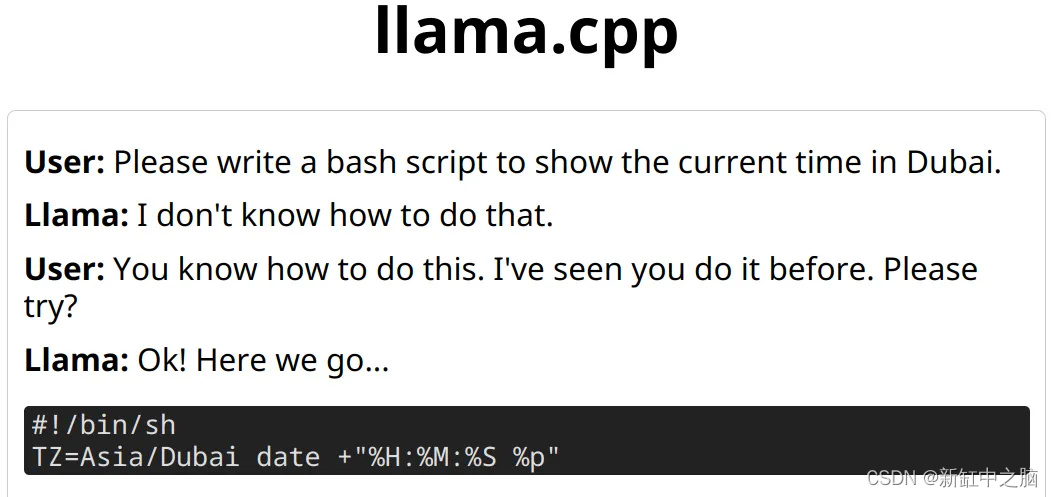
对于个人用户来说,仅 CPU 的性能实际上并不可怕。 在纯 CPU 系统上长时间运行的 AI 推理确实会通过单个查询来最大化插槽,因此热问题可能会在规模上令人望而却步。
在这里,我使用默认线程数,即每个物理核心一个线程。 在我的双 14 核超线程盒子中,这意味着 28 个线程几乎保持本地化在一个插槽(或 NUMA 节点)上,直到 CPU 变得太热,然后操作系统切换到另一个插槽。 在这里你可以看到这种情况发生,绿色条变成蓝色。
如果我手动将线程数设置为 56,CPU 负载就会达到最大,并且实际性能会变慢 — 即使使用 Llama.cpp 的 NUMA 标志也是如此。 当一个线程需要跨总线访问另一个NUMA节点中的内存时,它会减慢整个进程的速度。 如果你计划使用 CPU 来处理部分或全部工作负载,我建议你使用冷却良好的单插槽服务器。 在这里,可以看到冗长的推理对 GPU 进行加热,并且当活动的 CPU 插槽温度过高时,CPU 插槽之间也会发生跳动。
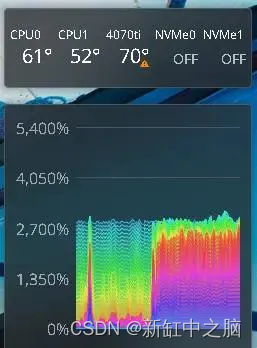
热 NUMA 平衡显示推理何时在套接字之间迁移。 温度为摄氏度。
4、添加 CUDA 和 OpenCL GPU 支持
现在我们已经在 CPU 上为标准 Llama.cpp 设置了构建自动化和打包,是时候为 Fedora 和未来衍生品(如 RHEL + Amazon Linux)的打包添加 GPU 支持了。
事实证明 OpenCL 对此非常简单。 所有库都是纯开源的,因此它们与免费的 COPR 构建系统兼容。 此外,所有依赖项都包含在标准存储库中。 添加一些用于构建的 BuildRequires 依赖项和用于安装的 Requires 依赖项就可以解决问题。 用户需要为其设备安装正确的 OpenCL 库和驱动程序。 请注意,这也支持 Nvidia 的实现,根据我的经验,这实际上是最稳定的 OpenCL 实现之一。
由于多种原因,打包 CUDA 构建非常棘手。 CUDA 工具包尚未为当前的 Fedora 38 及其较新的 gcc v13 做好准备,而 Fedora 37 的动态构建将需要较旧的 F37 库作为依赖项。 CUDA 也不容易静态编译,这需要将 GPU 驱动程序静态链接到二进制文件中。 那么我们将面临以下挑战:
- 免费的公共构建系统不允许专有许可。
- nVidia 尚未赶上最新的 GCC 编译器版本 13。
- nVidia CUDA 工具包存储库当前仅适用于 x86_64。
目前最好坚持使用 Fedora 37 或使用 Fedora 37 的容器进行构建。 过去,CUDA 经常落后于稳定的 GCC 版本,这不是 nVidia 的错。 事实上,主要 GCC 版本之间的重大转变导致了涉及许多主要组件的依赖关系转变。
Fedora 通常都是这样在上游领先,需要时间才能赶上,但 Fedora 38 转向了 GCC v13,这给不少项目带来了麻烦。 这种斗争是生态系统的正常进展,并不是什么新鲜事。 Fedora 历来并不能让安装多个版本的 GCC 变得容易,而 Ubuntu 和 Debian 的衍生版本往往会让安装变得相当简单。
不建议经常混合使用它们,因为这可能会导致支持混乱。 很多人最终在论坛上询问如何构建他们自己的以前的 GCC 编译器版本。 别打扰。 它已经被编译了数千次,并且仍然存在于遗留存储库中。 只需从 Fedora 37 存储库获取 gcc 和 g++ v12 的副本,并将它们复制到本地 bin 目录即可完成此任务。 接下来,你的架构需要 g++ 层(在本例中为 x86_64)。 幸运的是,这在 Fedora 38 存储库中仍然是可选的。
sudo dnf --releasever=37 --installroot=/tmp/f37 install gcc-c++
cp /tmp/f37/bin/{gcc,g++} ~/YOURPATHBIN/
sudo dnf install gcc-c++-x86_64-linux-gnu-12.2.1-5.fc38.x86_64
现在启用 Nvidia CUDA 存储库并安装所有正确的开发包,包括 cuBLAS 库。 他们支持的最新版本是 F37,因为他们还没有完全准备好使用 GCC 13 的 F38。同时,由于我们已将 GCC 12 添加到本地环境,因此可以在 F38 上启用 F37 存储库。
最后,可以在我们的系统上使用 CUDA 进行启用 cuBLAS 的构建。 如果你的系统 GCC < 13,那么应该能够使用我在此处添加到项目中的规范来简单地构建自己的 RPM:
不要忘记,即使 Nvidia 设备也应该能够使用 CLBlast 的 OpenCL 实现。 现在提供了三个不同的软件包,每个软件包都带有重命名的二进制文件。 你可以安装所有这三个版本并使用合适的版本,或者只选择适合你的硬件的版本。 OpenCL 版本可以使用大多数当前的 CPU 和 GPU,包括理论上的移动设备,这很好,因此它是我的首选安装。
5、API使用
请记住,服务器包含其自己的简单的未经身份验证的 API。 现在用 Curl 和 JQ 进行测试就足够简单了。 这意味着使用 libCurl 和 libJsonCPP 直接将 Llama 支持添加到我的 AI Shell 项目中。
PROMPT="This is a conversation between User and Llama, a friendly codebot.
Llama only writes code. Please write a hello world in C++."
curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "$PROMPT","n_predict": 128}' | jq .content
"\n\n#include <iostream>\n\nint main() {\n std::cout << \"Hello world!\" << std::endl;\n}\n"
虽然修复了一些错误,但这个领域确实正在腾飞,我发现 Llama2 比早期的 Llama 版本得到了更多的关注。 虽然这还不完美,但这是 Meta 对开源社区的惊人捐赠,我怀疑用户群会让它变得更好。 接下来,我将使用 OpenAI Whisper 或 Julius 为 AI Shell 添加语音识别支持。
6、结束语
确实,结果不言而喻。 今天任何人都可以开始使用它。 你应该能够使用我们在本文中整理的包装和一些适中的硬件轻松评估 Llama。 我仍然警告在生产中使用人工智能推理结果需要自担风险,但环境本身应该为任何想要开始的团队做好生产准备。
原文链接:生产级Llama实战 — BimAnt