文章目录
- 什么是 Maxwell?
- Maxwell 输出格式
- Maxwell 工作原理
- Maxwell 安装
- Maxwell 历史数据同步
- Maxwell 增量数据同步
什么是 Maxwell?
Maxwell 在大数据领域通常指的是一个用于数据同步和数据捕获的开源工具,由美国 Zendesk 开源,用 Java 编写的 MySQL 等关系型数据库的实时抓取软件。
Maxwell 可以监控数据库中的更改,并将这些更改以可消费的方式传递给其他系统。它通常用于实时数据管道、数据仓库、事件驱动架构等场景中,帮助将数据库中的变更数据传送到其他系统,以便进行分析、报告和其他数据处理操作。
Maxwell 的特点包括:
-
实时数据捕获:Maxwell 可以实时地捕获数据库中的更改,包括插入、更新和删除操作。
-
支持多种数据库:它可以与多种关系型数据库系统(如 MySQL、PostgreSQL)集成。
-
JSON输出:Maxwell 通常以 JSON 格式输出变更数据,这种格式易于处理和解析。
-
可配置性:用户可以根据自己的需求配置 Maxwell,包括选择要捕获的表格、输出目标等。
-
高性能:Maxwell 经过优化,可以处理高吞吐量的数据流。
Maxwell 官网地址
Maxwell 输出格式
下面通过一个官方案例来了解 Maxwell 的输出格式。
mysql> update `test`.`maxwell` set mycol = 55, daemon = 'Stanislaw Lem';
maxwell -> kafka:
{
"database": "test",
"table": "maxwell",
"type": "insert",
"ts": 1449786310,
"data": { "id":1, "daemon": "Stanislaw Lem", "mycol": 55 },
"old": { "mycol":, 23, "daemon": "what once was" }
}
Stage Analysis
-
首先,执行了一条 MySQL 的 UPDATE 语句,用于更新名为
test数据库中的maxwell表中的数据。它将mycol字段的值更改为55,将daemon字段的值更改为'Stanislaw Lem'。 -
maxwell -> kafka:这一行表示 Maxwell 捕获到了 MySQL 数据库中的更新操作,并将其传输到 Kafka 消息队列中。 -
JSON 数据块:以下是 JSON 格式的数据块,其中包含了关于更新操作的详细信息:
-
"database": "test":这是更新操作所在的数据库名称,即test。 -
"table": "maxwell":这是更新操作所在的表格名称,即maxwell。 -
"type": "update":这指示 Maxwell 将此更新操作视为 UPDATE 类型,因为实际上是对表中的数据进行了更新。 -
"ts": 1449786310:这是时间戳,表示更新操作发生的时间。 -
"data":这个部分包含了新的数据,包括id、daemon和mycol字段的新值,表示更新后的值。 -
"old":这个部分包含了旧的数据,包括mycol和daemon字段的旧值,表示更新前的值。在示例中,mycol字段的旧值为23,daemon字段的旧值为'what once was'。
-
这个示例演示了一个 MySQL 数据库中的 UPDATE 操作,Maxwell 捕获了这个操作并将其转化为 JSON 格式的事件,然后将这些事件发送到 Kafka 消息队列,以供其他系统订阅和处理。
Maxwell 工作原理
Maxwell 是一个开源的数据变更捕获工具,它的主要作用是捕获关系型数据库中的数据变更事件,并将这些事件以结构化的方式传送到消息队列(通常是Kafka)或其他目标,以便其他系统可以实时处理这些变更数据。
下面是 Maxwell 的工作原理简要解释:
-
数据库 Binlog 解析:Maxwell 通过订阅数据库的二进制日志(Binlog)来实时监控数据库中的变更。Binlog 是数据库引擎记录数据库操作的详细日志,包括插入、更新和删除等操作。
-
数据解析:一旦 Maxwell 连接到数据库的 Binlog,它开始解析 Binlog 中的数据变更事件。Maxwell 能够解析这些事件并将其转化为易于理解和处理的数据格式。
-
数据重构:Maxwell 将解析后的数据重构为 JSON 格式或其他结构化数据格式,以便后续系统可以轻松处理和消费这些数据。
-
数据发布:捕获的数据变更事件被发送到一个消息队列(通常是 Kafka),以实现异步和实时的数据传输。将数据发送到消息队列允许其他系统根据需要消费数据,而不会对原始数据库产生太多负载。
-
事件处理:一旦数据变更事件被发送到消息队列,其他系统可以订阅这些事件并处理它们。这些系统可以是数据仓库、实时分析系统、缓存系统、搜索引擎或其他需要实时数据的应用程序。
-
可配置性:Maxwell 具有丰富的配置选项,允许用户指定要捕获的数据库、表格、字段,以及如何处理捕获的事件。
Maxwell 的工作原理可以概括为捕获、解析、重构、发布和处理数据库中的数据变更事件。通常用于与流数据处理系统和实时分析工具集成,以支持实时数据分析和应用程序。
Maxwell 安装

安装之前需要注意,从
v1.30.0开始,Maxwell 不再支持JDK1.8,所以安装之前注意 JDK 版本!
官方快速入门文档
官方版本说明与下载
本节使用最后一个支持 JDK1.8 版本的 Maxwell v1.29.2 进行部署。
- 解压文件
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
- 添加环境变量
sudo vim /etc/profile.d/my.sh
# 添加如下内容:
#MAXWELL_HOME
export MAXWELL_HOME=/opt/module/maxwell-1.29.2
export PATH=$PATH:$MAXWELL_HOME/bin
刷新环境变量:source /etc/profile.d/my.sh
- 配置 MySQL
sudo vim /etc/my.cnf
# 添加如下内容:
[mysqld]
#maxwell 需要指定 Binlog 日志以"行级别"的方式进行记录
binlog_format=row
#MySQL服务器的唯一标识号
server_id=1
#启用二进制日志 Binlog,指定 "master" 作为 Binlog 文件的前缀名
log-bin=master
配置完成后,重启 MySQL:
sudo systemctl restart mysqld.service
- 创建 MySQL 用户并给予权限
CREATE USER 'maxwell'@'%' IDENTIFIED BY '000000';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
- 修改配置文件
cd $MAXWELL_HOME
cp config.properties.example config.properties
vim config.properties
############ 添加如下信息 ############
# 指定生产者对象
producer=kafka
# 指定 kafka 目标机器
kafka.bootstrap.servers=hadoop120:9092,hadoop121:9092,hadoop122:9092
# 指定 kafka topic
kafka_topic=maxwell
# 指定 mysql 连接信息
host=hadoop120
user=maxwell
password=000000
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 指定数据按照主键分组进入 kafka 不同分区,避免数据倾斜
producer_partition_by=primary_key

- 启动 Maxwell
启动 Maxwell 之前请先启动 MySQL、Zookeeper、Kafka。
cd $MAXWELL_HOME
maxwell --config config.properties --daemon
--daemon:告诉 Maxwell 以守护进程模式运行,也就是在后台运行而不会阻塞当前终端。

- 验证 Maxwell 是否启动成功
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l
-
ps -ef:列出所有进程信息。 -
grep com.zendesk.maxwell.Maxwell:查找 Maxwell 进程。 -
grep -v grep:排除包含字符串"grep"的行。在查找进程时,通常会包含一个与查找本身相关的"grep"进程,因此我们需要排除它。 -
wc -l:统计行数。
结果为 1 则表示启动成功了,为 0 则表示服务没有启动成功。

通过 jps 命令查看:

- 设置自动启停脚本
sudo vim /bin/mxw
添加下列内容:
#! /bin/bash
if [[ $# -ne 1 ]]; then
echo "参数有误,请重新输入!"
elif [[ "$1" = "start" ]]; then
echo "-----------------$host MAXWELL START-----------------"
maxwell -config $MAXWELL_HOME/config.properties --daemon
elif [[ "$1" = "stop" ]]; then
echo "-----------------$host MAXWELL STOP-----------------"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
elif [[ "$1" = "restart" ]]; then
echo "-----------------$host MAXWELL RESTART-----------------"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
maxwell -config $MAXWELL_HOME/config.properties --daemon
elif [[ "$1" = "status" ]]; then
echo "-----------------$host MAXWELL STATUS-----------------"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l
fi
给予权限:
sudo chmod +755 /bin/mxw
Maxwell 历史数据同步
当前在 MySQL 中创建了 finance_result 库,其中存储了许多表,现在对该库中的表进行全量历史数据同步。

创建 Kakfa 消费者
kafka-console-consumer.sh --bootstrap-server hadoop120:9092 --topic maxwell
注意,这里创建的 topic 要和 Maxwell 配置文件中设置的 topic 主题保持一致。
启动 Maxwell 历史数据同步,指定库名和表名。
cd $MAXWELL_HOME
maxwell-bootstrap --database finance_result --table industry --config $MAXWELL_HOME/config.properties
程序正常启动后 Kafka 消费端将会收到 Maxwell 发送过来的数据
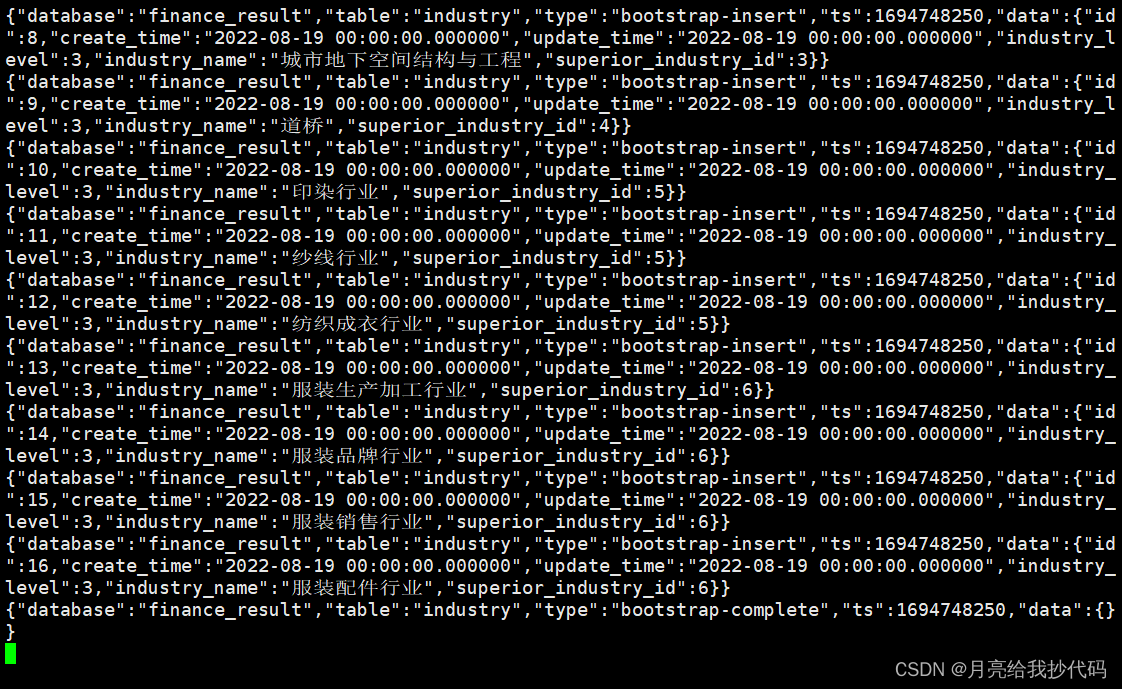
其中发送过来的数据第一行及最后一行数据是标识 Maxwell 历史数据同步的,不携带任何数据。
maxwell -> kafka:
{
"database": "finance_result",
"table": "industry",
"type": "bootstrap-start",
"ts": 1694748250,
"data": {}
}
{
"database": "finance_result",
"table": "industry",
"type": "bootstrap-insert",
"ts": 1694748250,
"data": {
"id": 1,
"create_time": "2022-08-19 00:00:00.000000",
"update_time": "2022-08-19 00:00:00.000000",
"industry_level": 1,
"industry_name": "工程建设",
"superior_industry_id": null
}
} {
"database": "finance_result",
"table": "industry",
"type": "bootstrap-insert",
"ts": 1694748250,
"data": {
"id": 2,
"create_time": "2022-08-19 00:00:00.000000",
"update_time": "2022-08-19 00:00:00.000000",
"industry_level": 1,
"industry_name": "轻工",
"superior_industry_id": null
}
} {
"database": "finance_result",
"table": "industry",
"type": "bootstrap-insert",
"ts": 1694748250,
"data": {
"id": 3,
"create_time": "2022-08-19 00:00:00.000000",
"update_time": "2022-08-19 00:00:00.000000",
"industry_level": 2,
"industry_name": "土木",
"superior_industry_id": 1
}
}
......
{
"database": "finance_result",
"table": "industry",
"type": "bootstrap-complete",
"ts": 1694748250,
"data": {}
}
Maxwell 增量数据同步
增量数据同步就是对 MySQL 中的所有库表进行实时监听,你对库表执行任何的操作都会发送到 Kakfa 消费者中。
先创建 Kakfa 消费者
kafka-console-consumer.sh --bootstrap-server hadoop120:9092 --topic maxwell
注意,这里创建的 topic 要和 Maxwell 配置文件中设置的 topic 主题保持一致。
启动 Maxwell 增量数据同步
cd $MAXWELL_HOME
maxwell --config config.properties --daemon
修改所监听 MySQL 库中任意表的一条数据,进行测试:
update finance_result.industry set industry_name="纱线行业" where id = 11;
将 finance_result.industry 表中 id 为 11 的 industry_name 修改为 "纱线行业"。
maxwell -> kafka:
{
"database": "finance_result",
"table": "industry",
"type": "update",
"ts": 1694751386,
"xid": 21025,
"commit": true,
"data": {
"id": 11,
"create_time": "2022-08-19 00:00:00.000000",
"update_time": "2022-08-19 00:00:00.000000",
"industry_level": 3,
"industry_name": "纱线行业",
"superior_industry_id": 5
},
"old": {
"industry_name": "纱线行业233"
}
}
修改完成后 Kafka 消费端将会收到 Maxwell 发送过来的增量数据信息,其中包括数据的相关更新信息以及历史数据。