目录
- 1. 情感分析概述
- 1.1 什么是情感分析?
- - 情感分析的定义
- - 情感分析的应用领域
- 1.2 为什么情感分析如此重要?
- - 企业和研究的应用
- - 社交媒体和公共意见的影响
- 2. 篇章级情感分析
- 2.1 技术概览
- - 文本分类的基本概念
- - 机器学习与深度学习方法
- - 词嵌入的力量
- - 序列建模的优势
- - 分层特征的提取
- 2.2 实战代码
- 3. 句子级情感分析
- 3.1 技术概览
- - 句子与情感
- - 上下文的重要性
- - 传统方法与深度学习
- - 词嵌入为基础
- - 序列模型捕捉上下文
- - Attention机制的关注点
- 3.2 实战代码
- 4. 属性级情感分析
- 4.1 定义与概念
- - 属性(Aspect)
- - 情感倾向(Sentiment Polarity)
- - 细粒度的文本表示
- - 上下文感知
- - 多任务学习
- - Attention机制
- 4.2 PyTorch实现代码
情感分析是自然语言处理的核心领域,专注于挖掘文本的主观情感。本文深入探讨了从篇章到属性级的情感分析技术,强调了上下文的重要性,并展示了Python和PyTorch的实践应用。通过深入了解这些技术背后的原理,我们揭示了深度学习在情感分析中的强大潜力和实际价值。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. 情感分析概述

情感分析,也被称为情绪分析或意见挖掘,是自然语言处理(NLP)的一个分支,旨在识别和提取文本中的主观信息,如情感、情绪或意见。
1.1 什么是情感分析?
- 情感分析的定义
情感分析主要关注对文本的情感倾向性进行分类,这些文本可能是正面的、负面的或中性的。此外,情感分析还可以进一步细分为确定文本的情感强度或确定特定的情绪,如高兴、伤心或愤怒。
例子:考虑如下评论:“这款手机的相机真的很出色,但电池寿命太短。”这里,“相机真的很出色”是正面评价,而“电池寿命太短”是负面评价。
- 情感分析的应用领域
情感分析被广泛应用于许多领域,如电子商务、社交媒体和公关管理。企业可以通过情感分析来了解消费者对其产品或服务的态度,而政府或公共机构则可以了解公众对某些政策或事件的反应。
例子:一家电子产品公司可能会监控社交媒体上关于其新发布产品的评论,以便了解公众的反应,从而调整其市场策略或产品设计。
1.2 为什么情感分析如此重要?
- 企业和研究的应用
情感分析为企业提供了洞察消费者心态的宝贵途径。了解消费者的情感和意见可以帮助企业更好地满足其需求,提高客户满意度,从而提高销售和品牌忠诚度。
例子:餐厅可能会利用情感分析来查看关于其食物和服务的在线评论,从而改进其菜单和员工培训。
- 社交媒体和公共意见的影响
在社交媒体上,每天都会发布大量的内容,涉及各种话题和观点。情感分析可以帮助机构或个人捕捉这些信息的情感倾向,从而做出更有根据的决策。
例子:在一次政治选举中,候选人团队可能会使用情感分析来追踪公众对其政策或演讲的反应,以更好地调整其竞选策略。
通过上述内容,我们可以清晰地理解情感分析的基本概念和其在实际应用中的重要性。
2. 篇章级情感分析
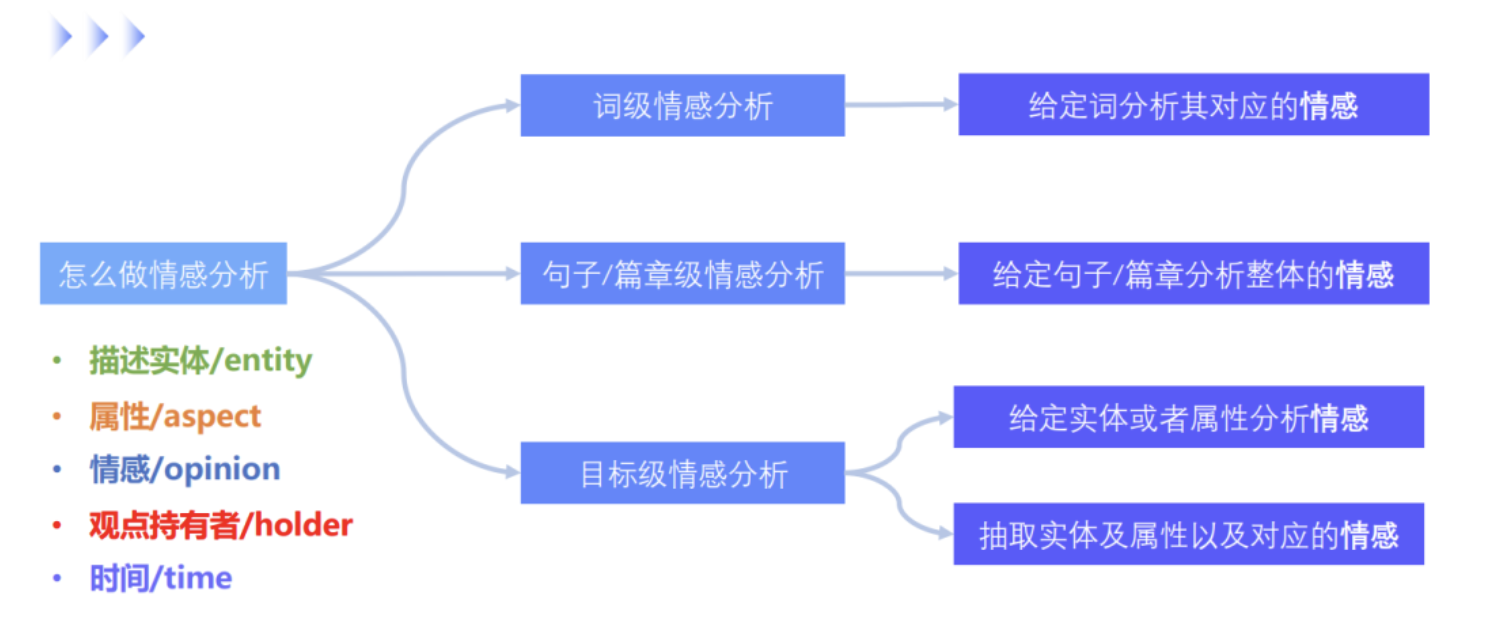
篇章级情感分析旨在评估整个文档或篇章的情感倾向性。与句子级或属性级情感分析不同,篇章级分析不仅仅关注单个句子或特定属性,而是关注文档的整体意见。
2.1 技术概览
- 文本分类的基本概念
在篇章级情感分析中,任务通常被视为一个文本分类问题。这意味着模型的目标是将整个文档分类为一个特定的类别,如“正面”、“负面”或“中性”。
例子:考虑一篇关于某个电影的评论:“这部电影的情节很有深度,演员的表现也很出色。”这篇评论可能会被分类为“正面”。
- 机器学习与深度学习方法
篇章级情感分析早期主要使用基于规则或词典的方法。但随着技术的发展,机器学习和深度学习方法开始占据主导地位,尤其是卷积神经网络(CNN)和循环神经网络(RNN)。
例子:在一个深度学习模型中,可能会使用词嵌入来表示文本,并使用RNN来捕捉文本的序列信息。最终,模型可能会预测文本的情感倾向为“正面”或“负面”。
- 词嵌入的力量
机器学习模型,尤其是深度学习模型,通常使用词嵌入(如Word2Vec或GloVe)来表示文本。词嵌入能够捕捉词与词之间的关系,并为每个词赋予一个稠密的向量,这使得模型能够捕捉到文本中的语义信息。
例子:amazing 和 incredible 都有正面的情感含义,它们在向量空间中的位置会非常接近。
- 序列建模的优势
RNN和其变体(如LSTM和GRU)具有记忆性质,这意味着它们能够捕捉文本中的序列信息。对于篇章级情感分析来说,考虑前文信息对于理解当前的情感非常重要。
例子:在句子 “The movie was not only boring but also too long.” 中,boring 和 too long 都有负面的含义,但如果只看long这个词,可能无法准确判断情感。而RNN可以考虑到整个句子的上下文,从而做出正确的分类。
- 分层特征的提取
深度学习模型如CNN和RNN可以提取文本的分层特征。在模型的较低层,它可能会捕捉到词汇和短语的基本模式;而在更高的层,它会识别更复杂的句子和篇章结构。
例子:一个深度模型可能首先识别到“outstanding”和“brilliant”这样的正面词汇,然后在更高的层次上识别到整篇评论的总体正面情感。
通过这些方法,机器学习和深度学习模型能够有效地理解并分类篇章级的文本。这也是为什么现代的情感分析方法倾向于使用这些技术,因为它们提供了更高的准确性和灵活性。
2.2 实战代码
我们将使用PyTorch实现一个简单的RNN模型进行篇章级情感分析:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy import data, datasets
# 定义数据字段
TEXT = data.Field(tokenize='spacy', include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
# 加载数据集
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
# 构建词汇表
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d")
LABEL.build_vocab(train_data)
# 定义RNN模型
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text, text_lengths):
embedded = self.embedding(text)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths)
packed_output, hidden = self.rnn(packed_embedded)
return self.fc(hidden.squeeze(0))
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = RNN(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, PAD_IDX)
# 定义损失函数和优化器
optimizer = optim.SGD(model.parameters(), lr=1e-3)
criterion = nn.BCEWithLogitsLoss()
# 训练模型
# ... 训练过程代码 ...
# 输入样本
sample_text = "This movie had an excellent plot and fantastic performances."
# 预测输出
predicted_sentiment = model(sample_text)
# 输出结果
print("Predicted sentiment:", torch.sigmoid(predicted_sentiment).item())
此代码中,我们首先定义了数据的处理方式和模型结构,然后加载了IMDB数据集。我们的模型是一个简单的RNN,它首先使用词嵌入将文本转化为向量,然后使用RNN捕捉文本的序列信息,并最后使用一个全连接层进行分类。
在上述代码中,模型的输入是一段文本,输出是一个介于0和1之间的值,表示文本的情感倾向(接近1表示正面,接近0表示负面)。
3. 句子级情感分析
句子级情感分析关注的是在单个句子的层面上评估情感。与篇章级分析不同,句子级分析针对更精细的文本单位进行情感判断,因此它对文本的序列性质和上下文信息的处理能力有更高的要求。
3.1 技术概览
- 句子与情感
在句子级情感分析中,我们主要关注的是单一句子的情感。这通常比篇章级分析更具挑战性,因为句子中的信息量较少,可能更难以确定。
例子:考虑句子 “这家餐厅的环境很好”,它可能表示正面情感;而句子 “这家餐厅太吵了” 则可能表示负面情感。
- 上下文的重要性
对于某些句子,如果脱离了上下文,可能很难确定其准确的情感。因此,句子级情感分析通常也需要考虑句子的上下文信息。
例子:考虑句子 “但是”,这个句子本身并没有明确的情感,但它可能表示上下文中的情感转折,如 “食物很好吃,但是服务员态度不好”。
- 传统方法与深度学习
与篇章级分析类似,早期的句子级情感分析方法主要基于规则或词典。但随着技术的进步,深度学习方法,特别是RNN和Attention机制,开始在此领域占据主导地位,因为它们能够更好地捕捉句子的序列信息和上下文。
- 词嵌入为基础
词嵌入,如Word2Vec或GloVe,提供了一种将词汇映射到连续的向量空间中的方法。这种表示形式可以捕捉单词之间的语义关系,为模型提供丰富的语境信息。
例子:考虑句子 “这部电影令人眼花缭乱。” 中的 “眼花缭乱” 这个词汇,通过词嵌入,我们可以得知它通常具有正面情感。
- 序列模型捕捉上下文
序列模型,特别是RNN和其变种(如LSTM和GRU),可以捕捉文本中的长期依赖关系。这对于理解一个句子的整体情感尤为关键,因为句子中的单个词汇可能会受到上下文的强烈影响。
例子:考虑句子 “我不是很喜欢这家餐厅。” 虽然 “喜欢” 这个词通常具有正面情感,但在此上下文中,由于前面有 “不是很” 的修饰,整体情感是中性偏负。
- Attention机制的关注点
Attention机制允许模型在处理句子时为每个词分配不同的权重。这意味着模型可以关注句子中最相关或最具有代表性的部分,从而提高情感分类的准确性。
例子:在句子 “食物很好,但是服务真的很差。” 中,尽管有正面的 “食物很好”,但Attention机制可能会更多地关注 “服务真的很差” 这部分,从而正确地分类整个句子的情感。
综上所述,通过结合词嵌入、序列建模和Attention机制等技术,机器学习和深度学习方法能够高效准确地进行句子级情感分析。这些技术共同作用,确保模型能够充分理解句子的细节和整体语境,从而做出准确的情感判断。
3.2 实战代码
我们将使用PyTorch实现一个带Attention机制的RNN模型进行句子级情感分析:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy import data, datasets
# 定义数据字段
TEXT = data.Field(tokenize='spacy', include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
# 加载数据集
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
# 构建词汇表
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d")
LABEL.build_vocab(train_data)
class AttentionModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True)
self.fc1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, text, text_lengths):
embedded = self.dropout(self.embedding(text))
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths)
packed_output, (hidden, cell) = self.rnn(packed_embedded)
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
hidden = torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)
hidden = torch.tanh(self.fc1(hidden))
return self.fc2(hidden)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = AttentionModel(INPUT_DIM, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, PAD_IDX)
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
# 训练模型
# ... 训练过程代码 ...
sample_sentence = "这部电影真的很糟糕。"
predicted_sentiment = model(sample_sentence)
# 输出结果
print("Predicted sentiment:", torch.sigmoid(predicted_sentiment).item())
此代码中,我们使用了双向LSTM来捕捉句子的上下文信息,并通过Attention机制加权句子中的每个词,使模型更加关注那些对情感判断更重要的词汇。模型的输入是一个句子,输出是一个介于0和1之间的值,表示句子的情感倾向(接近1表示正面,接近0表示负面)。
4. 属性级情感分析
属性级情感分析(Aspect-Level Sentiment Analysis)专注于特定的“属性”或“方面”,并尝试确定文本对这些属性的情感。与仅仅确定整体情感不同,它深入挖掘了文本中不同部分的情感倾向。
4.1 定义与概念
- 属性(Aspect)
属性或方面是文本中具体的主题或对象的部分。例如,在产品评论中,属性可能包括“电池寿命”、“相机质量”或“屏幕大小”。
例子:“手机的相机质量出奇地好,但电池寿命短。”中,“相机质量”和“电池寿命”是两个属性。
- 情感倾向(Sentiment Polarity)
对于每个属性,文本可能包含正面、负面或中性的情感。
例子:在上述示例中,对“相机质量”的情感是正面的,而对“电池寿命”的情感是负面的。
- 细粒度的文本表示
与传统的词袋模型不同,深度学习模型,特别是词嵌入,为文本提供了细粒度的表示。这些表示能够捕获词汇之间的微妙关系和语义信息。
例子:考虑词汇“电池”和“寿命”。词嵌入可以理解它们之间的关系,使模型能够识别它们经常一起出现,并与某种情感相关联。
- 上下文感知
深度学习模型,尤其是RNN和LSTM,非常擅长捕捉文本中的上下文信息。这意味着模型不仅仅看到单个词,而是理解词语在句子中的位置和它与其他词汇的关系。
例子:“虽然屏幕大,但分辨率低。”在这个句子中,“屏幕”和“分辨率”都是属性,但它们的情感是相反的。LSTM可以理解这种上下文,正确分类这两个属性的情感。
- 多任务学习
在属性级情感分析中,通常有多个属性需要分类。深度学习模型可以被设计为多任务学习框架,在单个模型中处理多个属性的情感分类,这可以提高效率并可能捕获属性之间的关系。
例子:在评价一家餐厅时,评论可能会提到“食物的口感”和“服务速度”。虽然这两个属性是独立的,但它们可能在某种程度上相关。多任务学习模型可以利用这些关系进行更准确的分类。
- Attention机制
Attention机制允许模型在处理句子时为每个词分配权重。这尤其在属性级情感分析中很有用,因为它允许模型集中注意力在与特定属性最相关的词汇上。
例子:在句子“手机的相机真的很棒,但电池用得很快。”中,当模型尝试确定与“相机”相关的情感时,Attention机制可以使其更多地关注“很棒”这个词。
4.2 PyTorch实现代码
以下是一个简化的PyTorch代码,用于属性级情感分析:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class AspectSentimentModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_aspects, num_labels):
super(AspectSentimentModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.aspect_layers = nn.ModuleList([nn.Linear(hidden_dim, num_labels) for _ in range(num_aspects)])
def forward(self, x):
x = self.embedding(x)
lstm_out, _ = self.lstm(x)
output = [layer(lstm_out[:, -1, :]) for layer in self.aspect_layers]
return output
# 例子
vocab_size = 5000
embed_dim = 128
hidden_dim = 256
num_aspects = 3 # 假设有3个属性
num_labels = 3 # 正面、负面、中性
model = AspectSentimentModel(vocab_size, embed_dim, hidden_dim, num_aspects, num_labels)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设输入数据:batch_size x seq_len
inputs = torch.randint(0, vocab_size, (32, 50))
# 假设标签:batch_size x num_aspects
labels = torch.randint(0, num_labels, (32, num_aspects))
# 前向传播
outputs = model(inputs)
losses = [criterion(output, labels[:, i]) for i, output in enumerate(outputs)]
loss = sum(losses)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Total Loss:", loss.item())
上述代码首先定义了一个属性级情感分析模型,该模型对每个属性使用单独的全连接层进行分类。在给定的示例中,我们假设有3个属性,每个属性的情感可能是正面、负面或中性。这只是一个基本的模型,实际应用中可能需要更复杂的网络结构和其他技术来提高性能。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。