pytorch神经网络基础
torch简介
torch和numpy
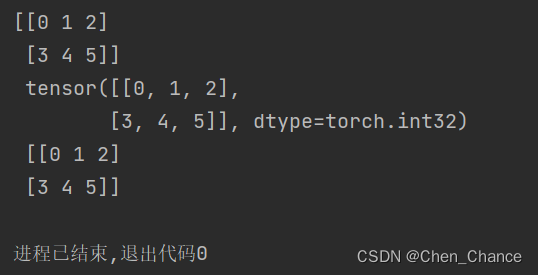
import torch
import numpy as np
np_data=np.arange(6).reshape((2,3))
torch_data=torch.from_numpy(np_data)
tensor2array=torch_data.numpy()
print(np_data,"\n",torch_data,"\n",tensor2array)
torch的数学运算
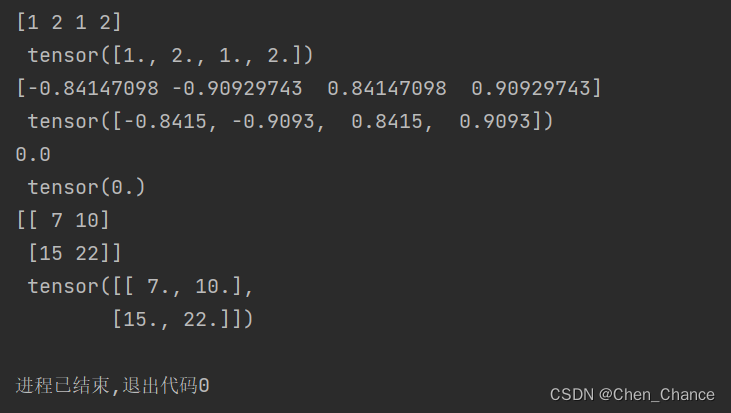
data=[-1,-2,1,2]
tensor=torch.FloatTensor(data)
# 绝对值abs
print(np.abs(data),"\n",torch.abs(tensor))
#三角函数sin
print(np.sin(data),"\n",torch.sin(tensor))
#mean均值
print(np.mean(data),"\n",torch.mean(tensor))
# np.dot (x,y)是用于计算两个数组的点积,即对应元素相乘再相加,
# 而np.matmul (x,y)则是用于计算两个数组的矩阵乘积
data=[[1,2],[3,4]]
tensor=torch.FloatTensor(data)
print(np.matmul(data,data),"\n",torch.mm(tensor,tensor))
变量(variable)
在PyTorch中,Variable在早期版本中用于自动求导(autograd)的功能,但从PyTorch 0.4.0版本开始,Variable已经被弃用,取而代之的是Tensor的功能。因此,如果你使用的是PyTorch 0.4.0或更新版本,你不再需要使用Variable。
以下是Variable和普通的变量(如Tensor)之间的一些区别,以及在新版本中的情况:
-
自动求导(Autograd):
Variable在早期版本中主要用于自动求导。你可以使用Variable包装一个Tensor,并在其上进行操作,PyTorch会跟踪这些操作以计算梯度。但在新版本中,Tensor自身具有自动求导功能,无需Variable。
-
In-Place操作:
- 在早期版本中,
Variable支持in-place操作(如var.data += 1),但这不是推荐的做法。在新版本中,in-place操作被明确禁止,以避免梯度计算中的错误。你应该使用.data属性来访问Tensor的数据,并避免in-place操作。
- 在早期版本中,
-
性能:
Variable的引入会增加一些额外的开销,因为它需要跟踪操作以进行自动求导。在新版本中,Tensor的性能更高,因为它不再需要这些额外的开销。
所以,总的来说,在PyTorch的新版本中,你应该使用Tensor而不是Variable来处理数据,因为Tensor包括了Variable的所有功能,而且性能更好。如果你在早期版本中使用Variable,你可能需要考虑升级你的代码以适应新的PyTorch版本。
什么是激励函数(activation function)
其实就是另外一个非线性函数. 比如说relu, sigmoid, tanh. 使得输出结果 y 也有了非线性的特征.
激励函数(activation)
一句话概括 Activation: 就是让神经网络可以描述非线性问题的步骤, 是神经网络变得更强大.
import torch
import torch.nn.functional as F # 激励函数都在这里
# 做一些假数据来观看图像
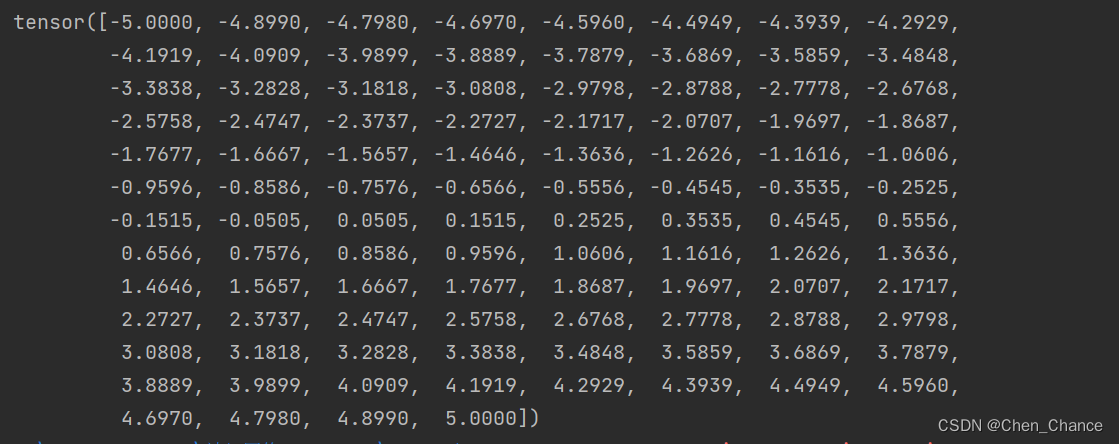
x=torch.linspace(-5,5,100) # x data (tensor), shape=(100, 1)
print(x)
x_np=x.numpy() # 换成 numpy array, 出图时用
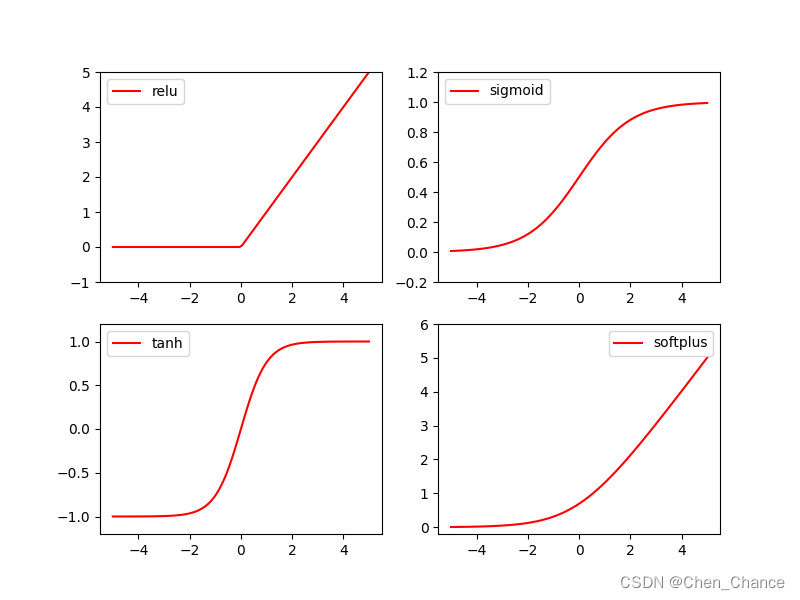
# 几种常用的激励函数
y_relu=F.relu(x).numpy()
y_sigmoid=torch.sigmoid(x).numpy()
y_sigmoid=F.sigmoid(x).numpy()
y_tanh=torch.tanh(x).numpy()
y_softplus=F.softplus(x).numpy()
# 画图部分还没看matplotlib,后续再补充
import matplotlib.pyplot as plt # python 的可视化模块, 我有教程 (https://mofanpy.com/tutorials/data-manipulation/plt/)
plt.figure(1, figsize=(8, 6))
plt.subplot(221)
plt.plot(x_np, y_relu, c='red', label='relu')
plt.ylim((-1, 5))
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np, y_sigmoid, c='red', label='sigmoid')
plt.ylim((-0.2, 1.2))
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np, y_tanh, c='red', label='tanh')
plt.ylim((-1.2, 1.2))
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np, y_softplus, c='red', label='softplus')
plt.ylim((-0.2, 6))
plt.legend(loc='best')
plt.show()
torch.sigmoid(x) 和 F.sigmoid(x) 都是计算输入张量 x 上的 sigmoid 函数,它们的输出结果是一样的。在最新版本的PyTorch中,通常建议使用 torch.sigmoid(x),而不再需要导入torch.nn.functional中的F.sigmoid(x),因为PyTorch的最新版本中已经将这些激活函数作为张量的方法进行了实现。
所以,以下两行代码是等价的:
y_sigmoid = torch.sigmoid(x).numpy()
y_sigmoid = F.sigmoid(x).numpy() # 在最新版本的PyTorch中也是有效的,但不推荐
通常情况下,建议使用 torch.sigmoid(x),因为它更符合PyTorch的现代风格。
建造第一个神经网络
关系拟合(回归)
要点
看神经网络是如何通过简单的形式将一群数据用一条线条来表示。
或者说, 是如何在数据当中找到他们的关系, 然后用神经网络模型来建立一个可以代表他们关系的线条。

建立数据集
import torch
import matplotlib.pyplot as plt
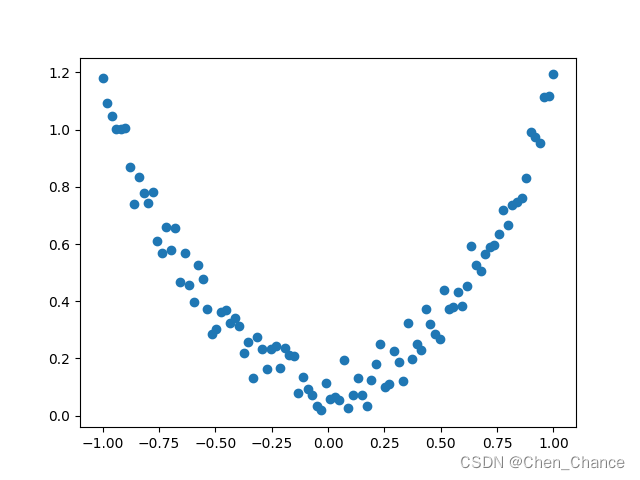
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y=x.pow(2)+0.2*torch.rand_like(x)
plt.scatter(x.numpy(),y.numpy())
plt.show()
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
这行代码使用了PyTorch库来创建一个包含100个元素的张量(tensor),该张量的值是从-1到1均匀分布的。
让我们一步一步来解释这行代码:
-
torch.linspace(-1, 1, 100):这部分代码使用torch.linspace函数创建一个从-1到1的等间距数列,其中包含100个数值。torch.linspace函数的第一个参数是起始值(-1),第二个参数是结束值(1),第三个参数是要生成的数值的数量(100)。这将生成一个张量,其中包含了从-1到1之间的100个均匀分布的数值。 -
torch.unsqueeze(..., dim=1):接下来,torch.unsqueeze函数被用来在张量中添加一个维度(dimension)。dim=1参数指定了要在哪个位置添加维度。在这里,我们将在第1维(即列维度)上添加一个维度。这将把原始的一维张量(形状为(100,))变成一个二维张量(形状为(100, 1)),其中有100行和1列。
最终的结果是一个形状为(100, 1)的二维张量,其中包含了从-1到1均匀分布的100个数值,每个数值都位于独立的行中。这种形式的张量通常在机器学习和深度学习中用于输入数据的处理,特别是当处理单个特征的数据时,常常需要将其转换为二维张量。
y=x.pow(2)+0.2*torch.rand_like(x)
这一行首先计算了 x 的平方,然后加上了一些噪声。让我们逐步解释:
-
x.pow(2):这部分代码计算了x中每个元素的平方。因为x是一个 PyTorch 张量,所以这个操作会对x中的每个元素都进行平方操作,生成一个新的张量,形状与x相同,但每个元素都是原来的元素的平方。 -
0.2*torch.rand_like(x):这部分代码生成了一个与x具有相同形状的张量,但其中的每个元素都是从均匀分布[0, 1)中随机采样的数值,并且每个数值都乘以0.2。这个操作引入了一些噪声,将其与平方项相加,以创建一个新的张量y。
最终,y 包含了与 x 对应的平方项加上一些随机噪声,因此它是一个形状相同的二维张量,其中包含了与 x 相关的数值。这种操作常见于机器学习中的回归任务,其中 x 可能表示输入特征,而 y 表示对应的目标值(或标签),噪声用于模拟现实世界中的不确定性和随机性。这种情况下,模型的任务是拟合从 x 到 y 的映射关系。
建立神经网络
# 建立神经网络
import torch
import torch.nn as nn
class Net(nn.Module):
# 搭建我们的层数时要用到的信息
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__() #可以暂时理解为初始化,这块要弄清楚是有难度的
self.hidden=nn.Linear(n_feature,n_hidden)#隐藏层,关心有多少个输入,有多少个神经元个数
self.predict=nn.Linear(n_hidden,n_output)#输出层,关心有多少个输入(从隐藏层而来的神经元),有多少个输出
# 神经网络前向传递的过程,真正开始搭建神经网络
def forward(self,x):
x=torch.relu(self.hidden(x))#我们的x过了一个hidden层,输出了n_hidden个神经元的个数
x=self.predict(x) #输出层接受x并输出结果
# 为什么我们的预测不用激励函数呢。因为在大多数的情况下回归问题的取值可以从负无穷到正无穷,
#而用了激励函数,会把取值范围截断一部分
return x
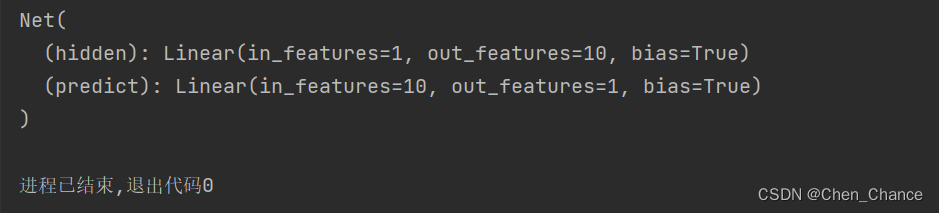
net=Net(n_feature=1,n_hidden=10,n_output=1)
print(net)
在这段代码中,self.hidden 和 self.predict 是神经网络模型 Net 类的成员变量(或属性),它们分别用来表示神经网络的隐藏层和输出层。这些成员变量的值来自于PyTorch中的 nn.Linear 类,它是PyTorch中用于创建线性层的类。
让我更详细地解释这些成员变量的来源:
-
self.hidden = nn.Linear(n_feature, n_hidden):- 这一行代码创建了一个名为
hidden的成员变量,并将其初始化为一个nn.Linear对象。 nn.Linear类表示一个线性层,通常用于神经网络的前向传播。这个线性层将具有n_feature个输入特征和n_hidden个神经元。- 在神经网络的前向传播过程中,输入数据将通过
self.hidden这个线性层,并且在传递时会经过线性变换,然后传递给激活函数(在你的代码中是ReLU),最终产生隐藏层的输出。
- 这一行代码创建了一个名为
-
self.predict = nn.Linear(n_hidden, n_output):- 类似地,这一行代码创建了一个名为
predict的成员变量,并将其初始化为另一个nn.Linear对象。 - 这个
nn.Linear对象表示输出层,它接受来自隐藏层的输出(n_hidden个输入特征)并生成模型的最终输出,通常在回归任务中,输出层只有一个神经元。
- 类似地,这一行代码创建了一个名为
这些 nn.Linear 层是PyTorch中提供的模块,它们封装了神经网络中的线性变换操作,可以自动进行权重初始化以及在模型的反向传播中计算梯度。这简化了神经网络的构建和训练过程,因为你只需要定义网络的结构,而不必手动管理权重和梯度。这些操作都由PyTorch的自动微分系统自动处理。
训练网络
# 训练网路
import torch
import torch.nn as nn
import torch.optim as optim
# 创建优化器和损失函数
optimizer=optim.SGD(net.parameters(),lr=0.2)
loss_func=nn.MSELoss()
for t in range(100):
prediction=net(x) # 喂给net训练数据x,输出预测值
loss=loss_func(prediction,y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播,计算参数更新值
optimizer.step() # 将参数更新值施加到net的parameters上
print(loss)

可视化训练过程
后面学了matplotlib再放
区分类型(分类)
要点
我们来看看神经网络是怎么进行事物的分类

建立数据集
import torch
import matplotlib.pyplot as plt
# 生成随机数据
n_data = torch.ones(100, 2)
print(n_data[:5])
x0 = torch.normal(2 * n_data, 1)
print(x0[:5])
y0 = torch.zeros(100, dtype=torch.long)
print(y0[:5])
x1 = torch.normal(-2 * n_data, 1)
print(x1[:5])
y1 = torch.ones(100, dtype=torch.long)
print(y1[:5])
# 合并数据
x = torch.cat((x0, x1), 0)
print(x[:5])
y = torch.cat((y0, y1))
print(y)
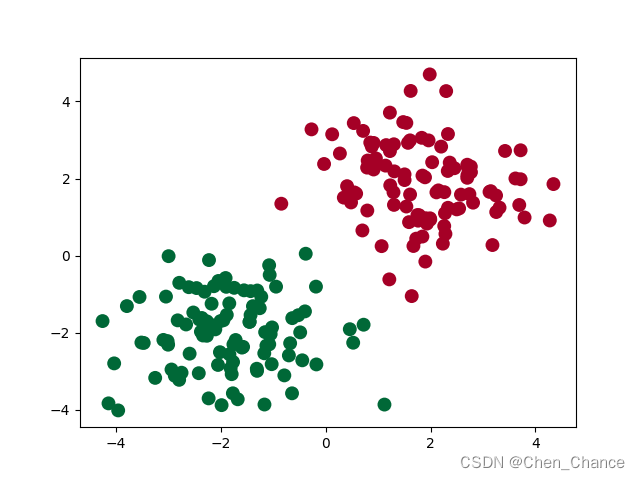
# 绘制散点图
plt.scatter(x[:, 0], x[:, 1], c=y, s=100, lw=0, cmap='RdYlGn')
plt.show()
在PyTorch中,数据类型(dtype)是一个非常重要的概念,它指定了张量中元素的数据类型。在代码中,y0 = torch.zeros(100, dtype=torch.long) 将创建一个包含100个零的张量,并将其数据类型设置为 torch.long。
加入 dtype=torch.long 的原因是,通常在深度学习中,torch.long 数据类型被用来表示整数类型的标签或类别。在分类任务中,标签通常是整数,每个整数代表一个不同的类别。例如,如果你正在处理一个图像分类任务,每个图像的类别标签可以是从0到(类别总数-1)的整数,这些整数用来表示不同的类别。
设置数据类型为 torch.long 有两个主要作用:
-
确保整数类型的存储:
torch.long数据类型确保了张量中的元素都是整数。这是因为默认情况下,PyTorch 创建的张量可能具有torch.float32(32位浮点数)数据类型,但类别标签应该是整数,因此需要显式设置数据类型为torch.long以确保它们被解释为整数。 -
与损失函数兼容:许多损失函数(例如交叉熵损失)要求标签是整数类型,因此将标签的数据类型设置为
torch.long可以确保它们与损失函数兼容,而不会引发数据类型不匹配的错误。
总之,dtype=torch.long 的设置是为了明确指定标签张量的数据类型为整数类型,以确保与深度学习任务中的标签和损失函数兼容。如果标签是整数,通常都应该使用这种设置。
torch.cat() 是PyTorch中的一个张量拼接函数,用于将多个张量沿指定的维度进行拼接(连接)操作。这个函数的目的是将多个张量合并成一个更大的张量。让我们详细解释一下 torch.cat() 函数的用法和参数:
torch.cat(tensors, dim=0, out=None) -> Tensor
参数说明:
tensors:一个包含要拼接的张量(可以是一个张量列表或元组)。dim:指定拼接的维度。默认是0,表示在第一个维度上进行拼接,即按行拼接。out:可选参数,用于指定输出张量,如果不提供将会创建一个新的张量来保存拼接后的结果。
示例:
import torch
# 创建两个张量
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6]])
# 在第一个维度上拼接(按行拼接)
result = torch.cat((x, y), dim=0)
print(result)
在这个示例中,我们创建了两个张量 x 和 y,然后使用 torch.cat() 函数将它们在第一个维度(按行)上进行拼接。结果是一个新的张量 result,其中包含了两个原始张量的内容:
tensor([[1, 2],
[3, 4],
[5, 6]])
torch.cat() 可以用于在任何维度上进行拼接操作,你可以根据需要选择合适的维度。这在深度学习中经常用于连接不同批次的数据、连接不同特征的数据等各种情况。
plt.scatter(x[:, 0], x[:, 1], c=y, s=100, lw=0, cmap='RdYlGn')
这行代码使用了Matplotlib库的 scatter 函数来创建一个散点图,以可视化数据点。让我们逐个参数来解释这行代码:
-
x[:, 0]和x[:, 1]:这部分代码使用索引操作从x中选择特定的列。假设x是一个二维张量,这里x[:, 0]表示选择所有行的第一个特征,而x[:, 1]表示选择所有行的第二个特征。这将分别用作散点图的 x 和 y 坐标。 -
c=y:这是c参数,用于设置散点的颜色。通常,c接受一个数组,表示每个数据点的颜色。在这里,y可能是一个数组,其中包含与x对应的类别或标签。这将根据标签值决定每个数据点的颜色,以区分不同的数据类别。 -
s=100:这是s参数,用于设置散点的大小。在这里,所有的散点都设置为相同的大小,大小为100。 -
lw=0:这是lw参数,用于设置散点的边界线宽度(linewidth)。在这里,将边界线的宽度设置为0,表示没有边界线。 -
cmap='RdYlGn':这是cmap参数,用于设置颜色映射。它指定了用于将不同的标签值映射到不同颜色的颜色映射表。在这里,使用了名为 ‘RdYlGn’ 的颜色映射,它代表了一种从红色到黄色再到绿色的颜色渐变。
综合起来,这行代码创建了一个散点图,其中每个数据点的 x 和 y 坐标由 x 的两个特征决定,颜色由 y 的值决定,散点的大小相同,没有边界线,并且使用 ‘RdYlGn’ 的颜色映射表来表示不同的标签值。这种可视化方式有助于可视化数据的分布和类别信息,特别是在二维空间中。
建立神经网络
# 建立神经网络
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden=nn.Linear(n_feature,n_hidden)
self.out=nn.Linear(n_hidden,n_output)
def forward(self,x):
x=torch.relu(self.hidden(x))
x=self.out(x)
return x
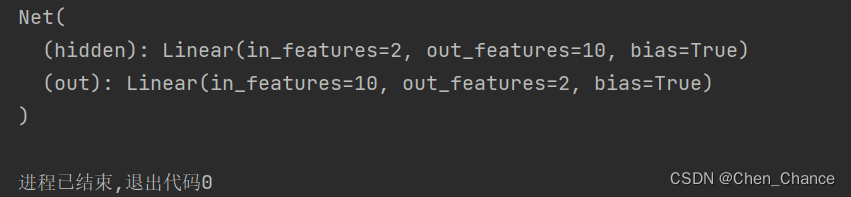
net=Net(n_feature=2,n_hidden=10,n_output=2)
print(net)
训练网络
# 训练网络
import torch.optim as optim
# 创建优化器和损失函数
optimizer=optim.SGD(net.parameters(),lr=0.02)
loss_func=nn.CrossEntropyLoss()
for t in range(100):
out=net(x)#喂给net训练数据x,输出分析值
loss=loss_func(out,y)#计算两者的误差
optimizer.zero_grad()#清空上一步的残余更新参数值
loss.backward()#误差反向传播,计算参数更新值
optimizer.step()#将参数更新值施加到net的parameters上
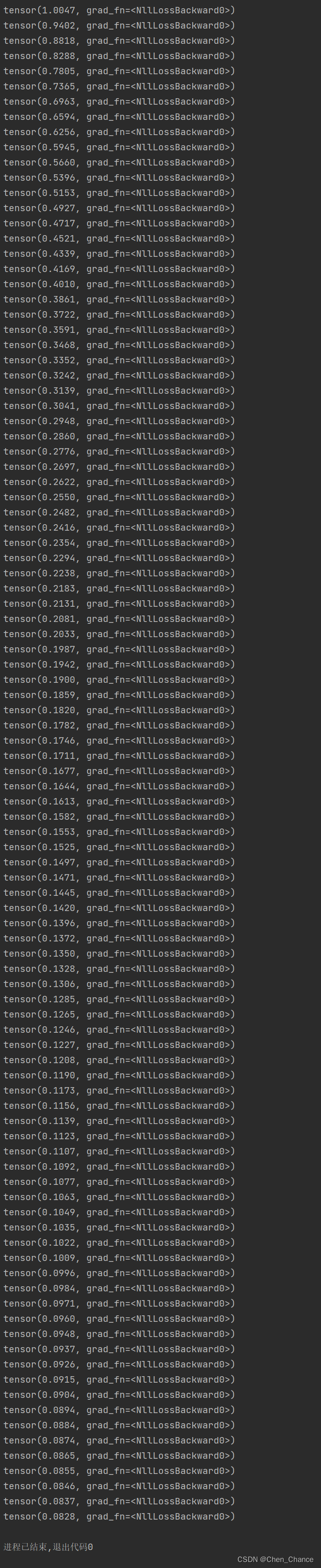
print(loss)
可视化训练过程
后续再补充
快速搭建法
要点
Torch 中提供了很多方便的途径, 同样是神经网络, 能快则快, 我们看看如何用更简单的方式搭建同样的回归神经网络.
快速搭建
我们之前是这样子搭建神经网络
import torch
import torch.nn as nn
class Net(nn.Module):
# 搭建我们的层数时要用到的信息
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__() #可以暂时理解为初始化,这块要弄清楚是有难度的
self.hidden=nn.Linear(n_feature,n_hidden)#隐藏层,关心有多少个输入,有多少个神经元个数
self.predict=nn.Linear(n_hidden,n_output)#输出层,关心有多少个输入(从隐藏层而来的神经元),有多少个输出
# 神经网络前向传递的过程,真正开始搭建神经网络
def forward(self,x):
x=torch.relu(self.hidden(x))#我们的x过了一个hidden层,输出了n_hidden个神经元的个数
x=self.predict(x) #输出层接受x并输出结果
# 为什么我们的预测不用激励函数呢。因为在大多数的情况下回归问题的取值可以从负无穷到正无穷,
#而用了激励函数,会把取值范围截断一部分
return x
net=Net(n_feature=1,n_hidden=10,n_output=1)
print(net)
上面我们用 class 继承了一个 torch 中的神经网络结构, 然后对其进行了修改, 不过还有更快的方法
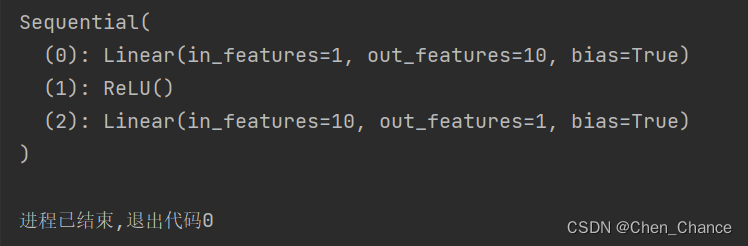
import torch.nn as nn
net=nn.Sequential(
nn.Linear(1,10),
nn.ReLU(),
nn.Linear(10,1)
)
print(net)
两种方法都可以用于构建神经网络,每种方法有其优点和适用场景。让我解释一下它们的优缺点以及何时使用哪种方法:
1. 自定义类方法(第一个示例):
-
优点:
- 更灵活:你可以定义自己的前向传播逻辑,可以实现非常复杂的模型结构。
- 易于理解和调试:因为你可以明确地看到每个层的定义和前向传播的计算过程,更容易理解和调试。
-
缺点:
- 代码量较多:相对来说,需要编写更多的代码来定义每个层和前向传播的逻辑。
- 可读性较差:对于简单的模型,可能会感到冗长,不够紧凑。
2. Sequential 方法(第二个示例):
-
优点:
- 简洁:使用
nn.Sequential可以更紧凑地定义模型结构,特别适合简单的线性模型。 - 减少代码量:避免了手动定义每个层的繁琐过程。
- 简洁:使用
-
缺点:
- 有限灵活性:
nn.Sequential适用于线性堆叠的模型结构,对于复杂的模型结构和非线性连接不够灵活。 - 难以定制:如果需要在不同层之间添加自定义操作或者非线性激活函数,使用
nn.Sequential可能会不方便。
- 有限灵活性:
何时使用哪种方法取决于你的需求:
-
自定义类方法 更适合需要灵活性的情况,例如:
- 当你需要定义复杂的非线性模型结构时。
- 当你想要添加自定义操作或层之间的复杂连接时。
- 当你需要更详细的控制权和可调试性。
-
Sequential 方法 更适合简单的线性模型或者需要紧凑表示的情况,例如:
- 当你构建简单的线性堆叠模型时(例如,多层感知器)。
- 当你只需要一系列简单的层按顺序连接,不需要复杂的结构。
通常,如果你的模型足够简单,可以使用 nn.Sequential 来简化代码。但如果你需要更高级的功能、更复杂的模型结构或者更多的控制权,那么自定义类方法会更有优势。在实践中,你可能会在不同的情况下使用这两种方法,根据任务的复杂性和要求来选择合适的方式。
保存提取
要点
训练好了一个模型, 我们当然想要保存它, 留到下次要用的时候直接提取直接用, 这就是这节的内容啦. 我们用回归的神经网络举例实现保存提取.
保存
我们先快速建造数据,搭建网络
import torch
import torch.nn as nn
import torch.optim as optim
# 设置随机种子以确保可重复性
torch.manual_seed(1)
#生成假数据
x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y=x.pow(2)+0.2*torch.rand(x.size())
def save():
# 建立网络
net1=nn.Sequential(
nn.Linear(1,10),
nn.ReLU(),
nn.Linear(10,1)
)
# 定义优化器和损失函数
optimizer=optim.SGD(net1.parameters(),lr=0.5)
loss_func=nn.MSELoss()
# 训练
for t in range(100):
prediction=net1(x)
loss=loss_func(prediction,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
代码解释:
-
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1):torch.linspace(-1, 1, 100)创建了一个包含100个均匀分布在-1到1之间的数值的张量。这些值将作为输入特征x。torch.unsqueeze()函数将这个一维张量转换为一个二维张量。具体来说,dim=1参数表示在第1维上添加一个维度,从而将原始的一维张量转换为形状为 (100, 1) 的二维张量,这样可以作为神经网络的输入。
-
y = x.pow(2) + 0.2 * torch.rand(x.size()):x.pow(2)对输入特征x中的每个元素进行平方操作,从而得到一个张量,其中包含了100个元素,每个元素都是输入特征的平方。torch.rand(x.size())创建一个与x相同大小的随机张量,其中的值是在0到1之间均匀分布的随机数。这个随机张量表示添加到目标y中的噪声。- 最后,通过将
x.pow(2)和随机噪声相加,得到最终的目标张量y。这个操作在原始函数x^2的基础上引入了一些随机变化,模拟了真实世界中的数据噪声。
总之,这段代码用于生成一个带有噪声的数据集,其中 x 是输入特征,表示在-1到1之间均匀分布的值,y 是与 x 之间的二次函数关系,并添加了一些随机噪声,以模拟实际数据集。这种数据集常用于回归任务的训练和测试。
接下来我们有两种途径来保存(下面的代码是写在save()里的)
# 保存整个网络:
torch.save(net1,'net1.pkl')
# 仅保存网络中的参数(推荐的方式,因为速度更快且占用内存更少):
torch.save(net1.state_dict(),'net1_params.pkl')

提取网络
# 读取模型
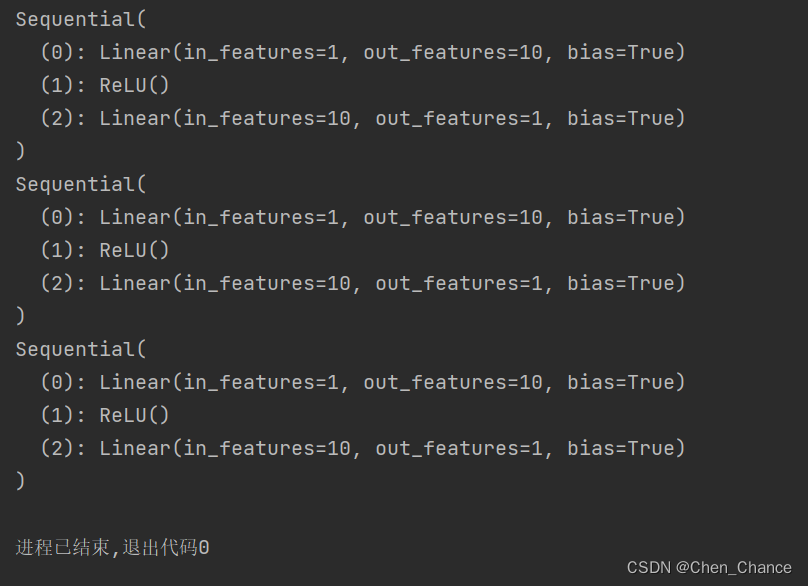
def restore_net():
net2=torch.load('net1.pkl')
print(net2)
只提取网络参数
def restore_params():
# 新建net3,确保与之前的模型架构一致
net3=torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
# 将保存的参数复制到net3
net3.load_state_dict(torch.load('net1_params.pkl'))
print(net3)
显示结果
# 保存 net1 (1. 整个网络, 2. 只有参数)
save()
# 提取整个网络
restore_net()
# 提取网络参数, 复制到新网络
restore_params()
批训练
要点
Torch 中提供了一种帮你整理你的数据结构的东西,,叫做 DataLoader, 我们能用它来包装自己的数据,进行批训练。
DataLoader
DataLoader 是 torch 给你用来包装你的数据的工具. 所以你要讲自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中. 使用 DataLoader 有什么好处呢? 就是他们帮你有效地迭代数据,