肖杨
OceanBase生态产品研发工程师
OceanBase 生态产品研发工程师,山地骑行爱好者,ODC 团队核心成员,负责数据安全合规和系统集成,对 Java EE、 AI 大模型、MCU 芯片 等技术有着浓厚兴趣。
在数据库协同开发领域,敏感数据管控对于企业和用户都至关重要。近年来,随着数据安全法、个人信息保护法等法律法规的颁布实施,国家和社会对于隐私数据安全的重视程度不断提升;操作审计和隐私数据保护变得愈加重要,已成为数据库协同开发工具选型的关键考量指标。
隐私数据通常包括用户的身份证号、手机号、家庭住址等敏感信息,这是不可或缺的保障业务正常运行的基础数据。为了确保用户数据不会泄漏,必须严格限制对业务库的访问。然而,完全限制访问也可能导致协作效率下降,这是一个令人担忧的问题。因此,在面对企业级的数据库开发场景时,我们需要认真思考:如何以安全合规的方式积极预防内部数据泄漏风险,以确保用户的隐私数据得到最严格的保护?本文将针对隐私数据保护及安全合规,分享 ODC 的设计思考和解决方案。

企业在进行运维、开发和数据分析等工作时,通常需要执行数据库查询操作。这些数据库中可能存在业务需要且无法剥离的敏感数据,而直接查询这些数据可能引发隐私泄露风险。同时,过于严格限制访问又可能导致工作效率低下的问题。在这种情况下,数据脱敏技术可以发挥作用,它可以在 SQL 查询、数据导出等数据出库的场景中对敏感数据进行脱敏处理再进行输出,以既保证数据库可访问性,又不暴露隐私数据。
让我们通过一个直观的例子来说明:假设在数据库中存在一个名为"student"的表,记录了所有学生的基本信息。现在,我们需要统计学生的年龄,但又不希望透露学生的住址、联系方式等敏感信息。在这种情况下,执行 SQL 查询后,"student"表的结果应该如下所示。这种数据脱敏技术不仅确保了高效灵活的工作流程,还在任何时候都能最大程度地保护敏感信息的隐私安全。
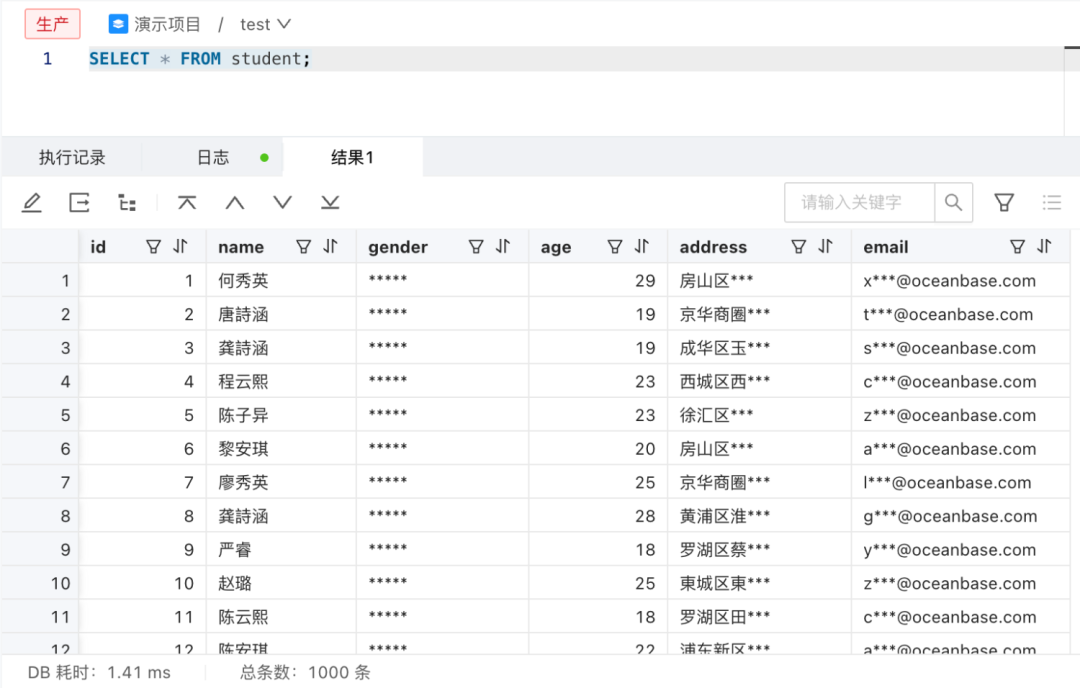

ODC 将敏感数据的保护放在首要位置,为企业提供了可信赖的全场景敏感数据保护,确保用户的数据安全合规。访问数据库通常是获取敏感数据的主要途径,甚至在某些情况下可能是唯一途径。如果能够在数据库查询阶段对敏感数据进行脱敏处理,这就成为数据交互的第一道防线,最大程度地保障数据的安全。
同时,通过数据隐私保护能力,安全管理员可以根据需要配置敏感数据规则和脱敏算法,确保敏感数据的绝对安全。即便是数据库管理员(DBA)和开发人员,经过配置后也无法直接接触敏感数据,从而极大地降低了数据泄露的风险。这种严格的数据隐私保护机制,使得企业的敏感信息在任何时候都能得到最大程度的保护。
在 ODC 的数据库协作开发流程中,用户无法直接访问数据库做数据查询。要想查看数据,只能通过以下方式:
1. 在数据库对象管理页查看表数据;
2. 提交导出工单,将数据导出到文件后进行查看;
3. 提交数据库变更工单,在变更任务中执行 SELECT 语句,然后查看执行结果集;
4. 在 SQL 窗口执行 SELECT 语句,查看结果集。
对于方式 1 和 2,实现数据脱敏相对容易。因为我们已经清楚地知道用户正在访问哪些库表列,只需要将敏感列进行脱敏处理即可。但是在方式 3 和 4 中,用户可以输入各种复杂的 SQL 查询,很难准确识别用户到底在查哪些数据,这是为什么动态脱敏比静态脱敏更具挑战的原因。
值得一提的是,ODC 的数据脱敏覆盖了所有数据出库场景,并且支持 OceanBase 数据库所有类型的 SQL 语法。无论 MySQL 兼容模式 和 Oracle 兼容模式,ODC 都可以提供数据脱敏解决方案。

以下我们通过一个实际的业务场景,体验如何使用 ODC 实现全场景敏感数据防护。
(一)关键术语
首先了解一些与 ODC 相关的关键术语,为了方便理解,本文先约定以下术语:
-
敏感列:数据库表中,存储敏感数据的列;
-
脱敏算法:用于对敏感数据进行脱敏处理的算法;
-
识别规则:用于标记数据库的某一列为敏感列的匹配条件,ODC 可以将符合规则的列自动识别敏感列。
(二)准备验证数据
在开始验证之前,我们首先使用 ODC 创建了两张数据表:数据表 1(employee_info)和数据表 2(employee_salary):
CREATE TABLE test.employee_info (id int NOT NULL COMMENT '员工 ID',name varchar(32) NULL COMMENT '员工姓名',email varchar(64) NULL COMMENT '员工邮箱',address varchar(128) NULL COMMENT '员工住址',CONSTRAINT pk_id PRIMARY KEY (id)) DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci;CREATE TABLE test.employee_salary (id int NOT NULL COMMENT '员工 ID',salary float(10) NULL COMMENT '员工工资',CONSTRAINT pk_id PRIMARY KEY (id)) DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_general_ci;
接下来,我们插入了模拟数据,以下是原始表数据的示例(请注意,以下数据仅为模拟,不包含真实用户信息):
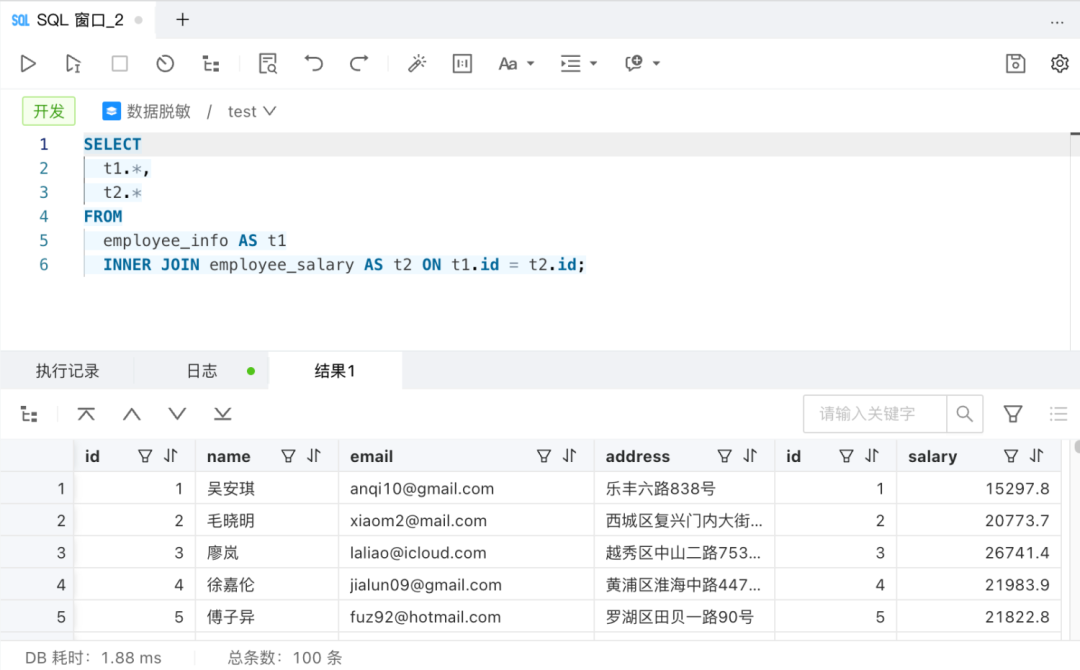
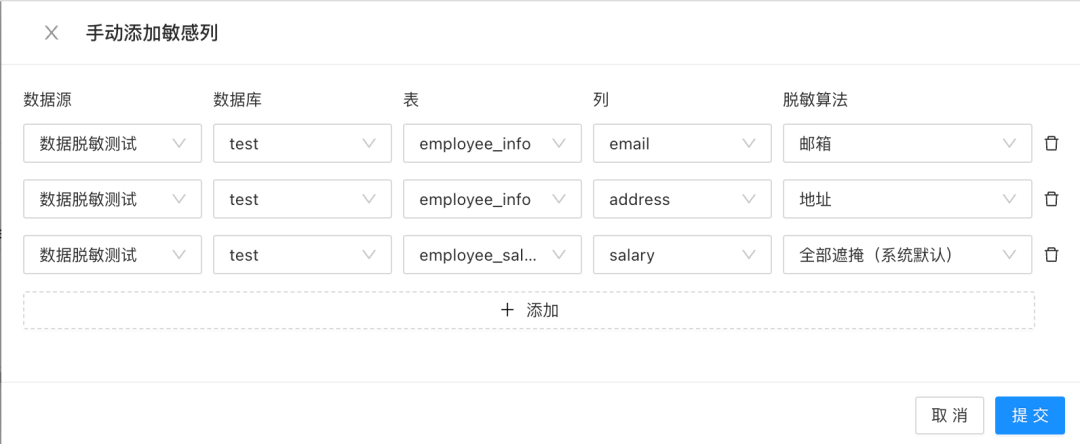
最后,我们将需要进行脱敏处理的列添加到敏感列列表中。鉴于展示的数据列较少,我们采用手动添加的方式进行配置:
(三)场景验证
接下来,让我们探讨在各种数据出库场景下,ODC 如何更好地帮助用户进行数据脱敏处理。
场景一:白屏查看表数据,敏感字段脱敏后再展示
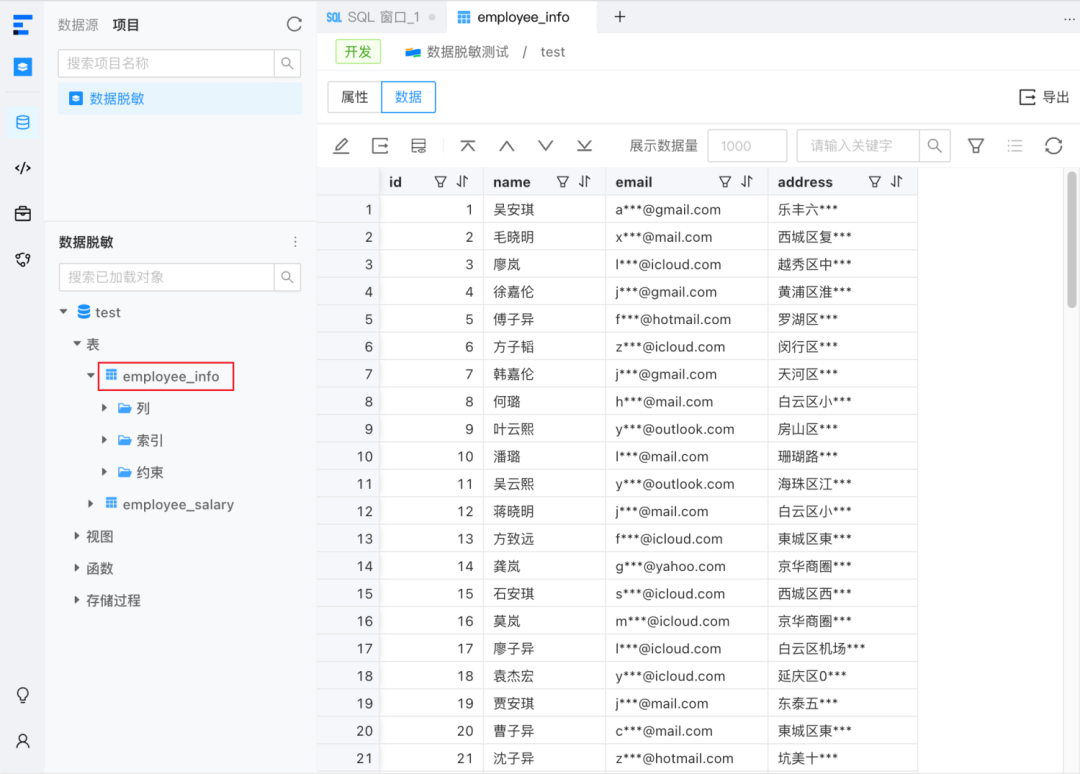
首先,在数据库对象树查看表 employee_info 的数据时,可以注意到表中的敏感列数据已经经过脱敏处理:
场景二:将数据导出到文件,敏感数据被脱敏处理
接下来,我们尝试将包含敏感列的表导出为 CSV 文件:
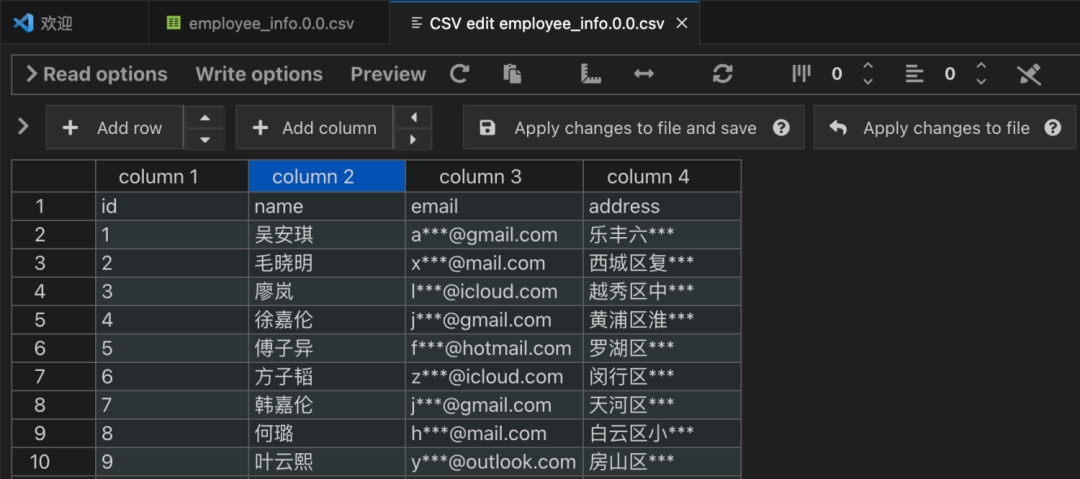
查看导出的 CSV 文件内容,可以发现发现敏感列同样已被脱敏处理:
场景三:执行 SELECT 查询,任何 SQL 语法都无法绕过数据脱敏
正如前面提到的,动态数据脱敏的核心挑战在于在各种复杂 SQL 语法下准确识别敏感列。下面我们逐步探讨 ODC 动态数据脱敏对 SQL 语法的支持水平。
首先是一个简单的单表查询:
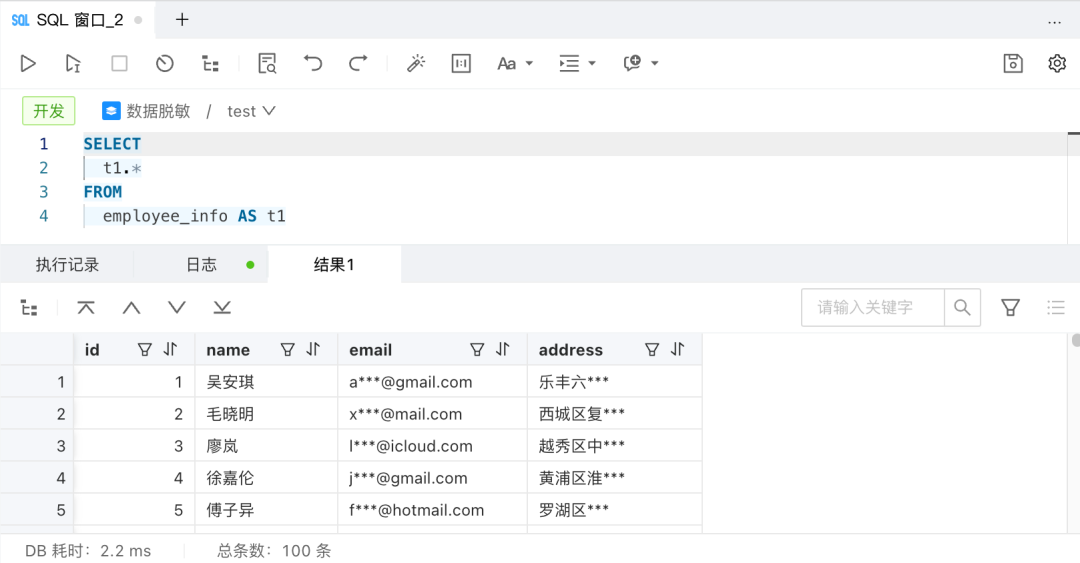
正如大家看到的,作为敏感数据的 email 列和 address 列被成功脱敏。接下来,我们测试了一些内置函数、CASE WHEN 以及 JOIN 和 UNION 查询:
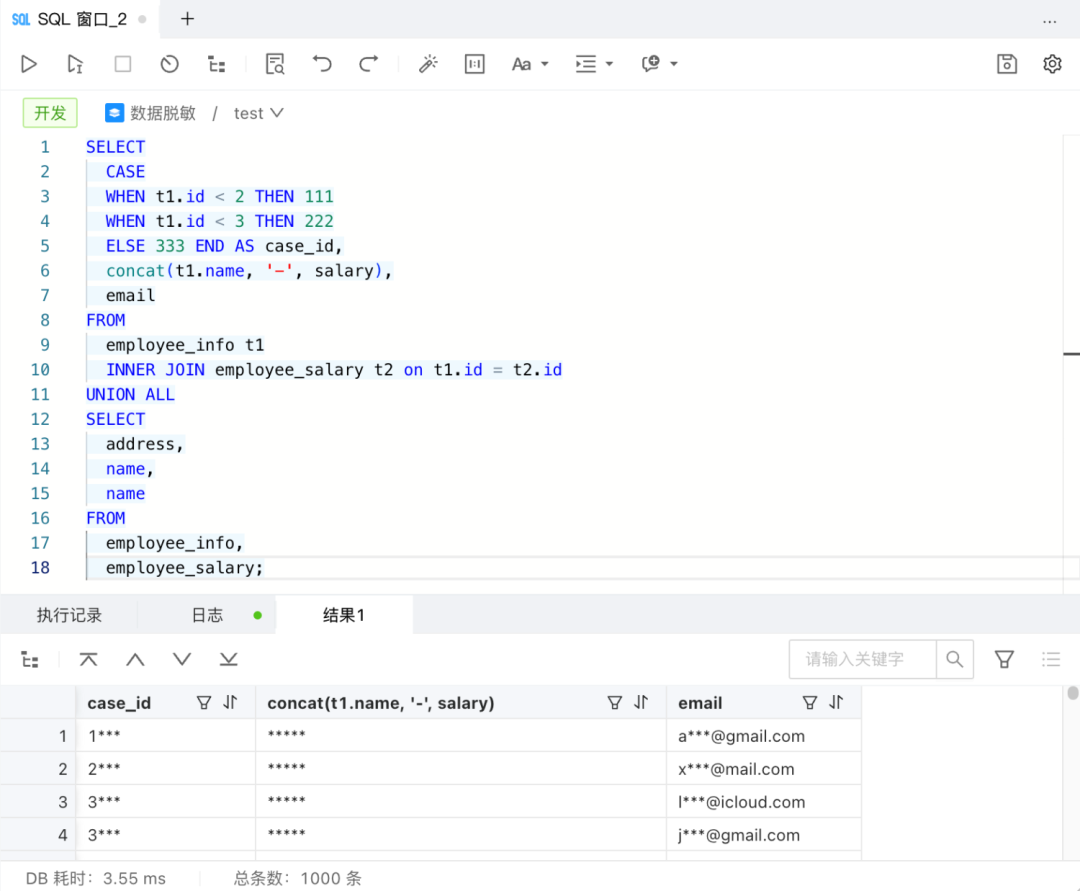
这些查询对于 ODC 动态数据脱敏来说也是“小意思”。结果集的三列均已成功脱敏,让我们逐一分析原因:首先,id 列并非敏感数据,但因与其进行 UNION 运算的 address 列是敏感数据,导致结果集的 case_id 列需要脱敏;同样地,name 列并非敏感列,因为使用了 CONCAT() 函数将其与 salary 列进行了拼接,导致 concat(t1.name, '-', salary) 列也需要脱敏;最后,email 列和 name 列合并的结果自然也是需要脱敏的。
我们进一步测试了多层嵌套子查询:
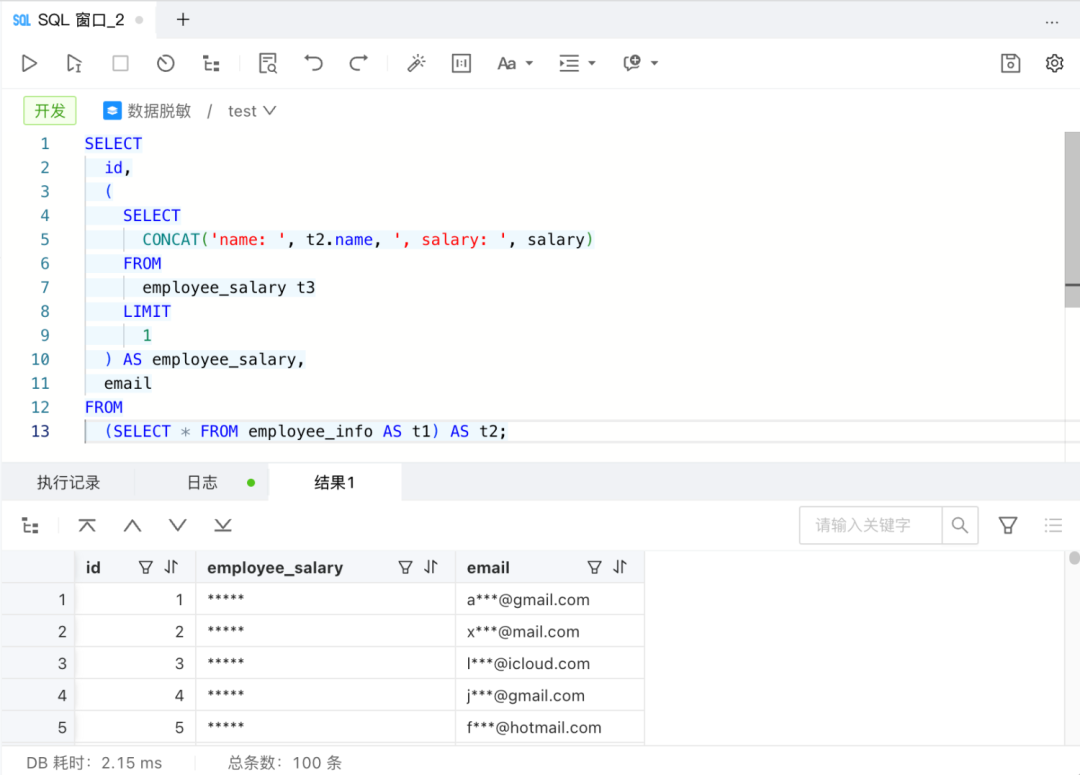
这看起来可能相当具有挑战性,但是我们还是成功应对了这一挑战

。可以看到,对于 FROM 子句和 SELECT 子句中出现的子查询,无论是关联子查询还是非关联子查询,ODC 都能够正确应对。
虽然我们已经能够处理绝大多数 SQL 查询,但 ODC 并不满足于此。ODC 还支持对递归和非递归 CTE 的语法支持,并且能处理递归 CTE 中出现的敏感列传递:
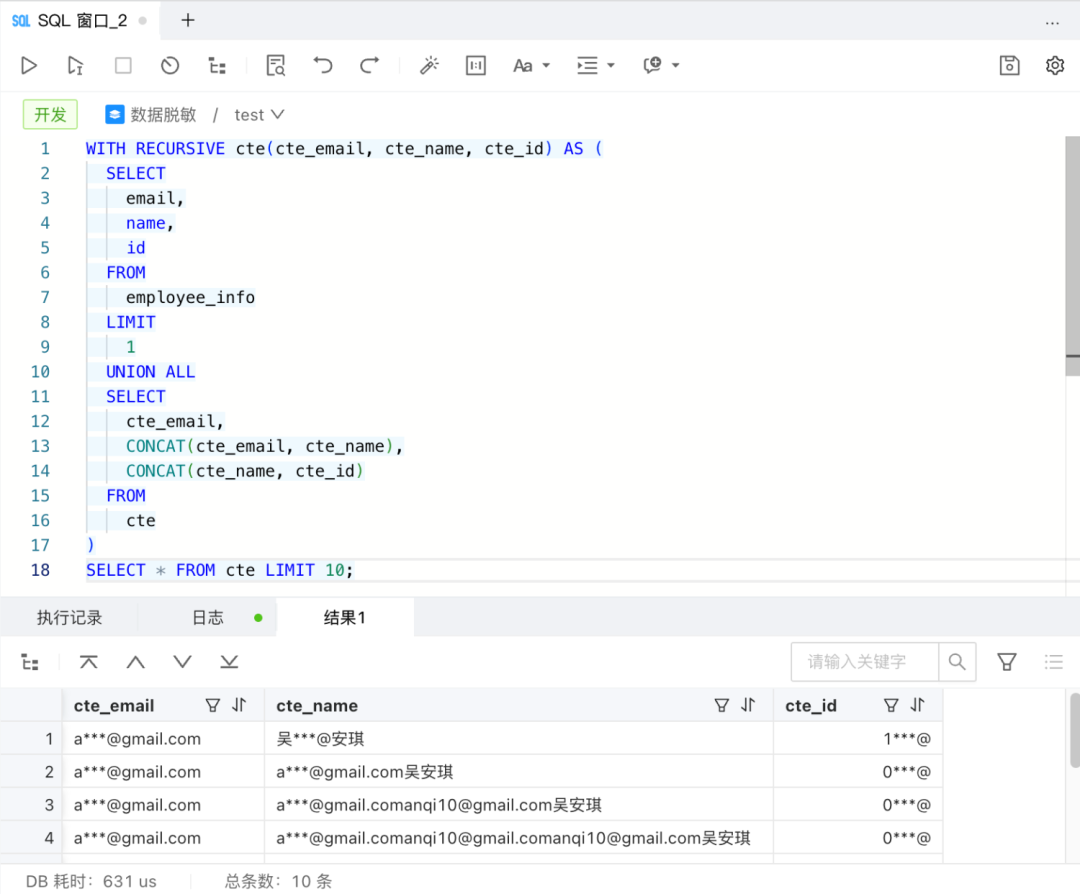
上面的例子中,你可能会好奇为什么 cte_id 列也被脱敏了?这是因为 Recursive CTE 的敏感数据“传染”问题:在第一次递归中,CONCAT(cte_email, cte_name) 运算导致 cte_name 列包含了敏感数据,即 cte_name 列变成了敏感列;而在第二次递归中, CONCAT(cte_name, cte_id) 运算使 cte_id 列也被“感染”上敏感数据。因此,最终的结果是,ODC 对结果集的三列均作了脱敏处理。
其它场景
数据库变更与 SQL 窗口查询在本质上没有太大区别,都是执行 SQL 语句并输出结果。因此,在 SQL 窗口中支持的动态数据脱敏能力同样适用于数据库变更工单。
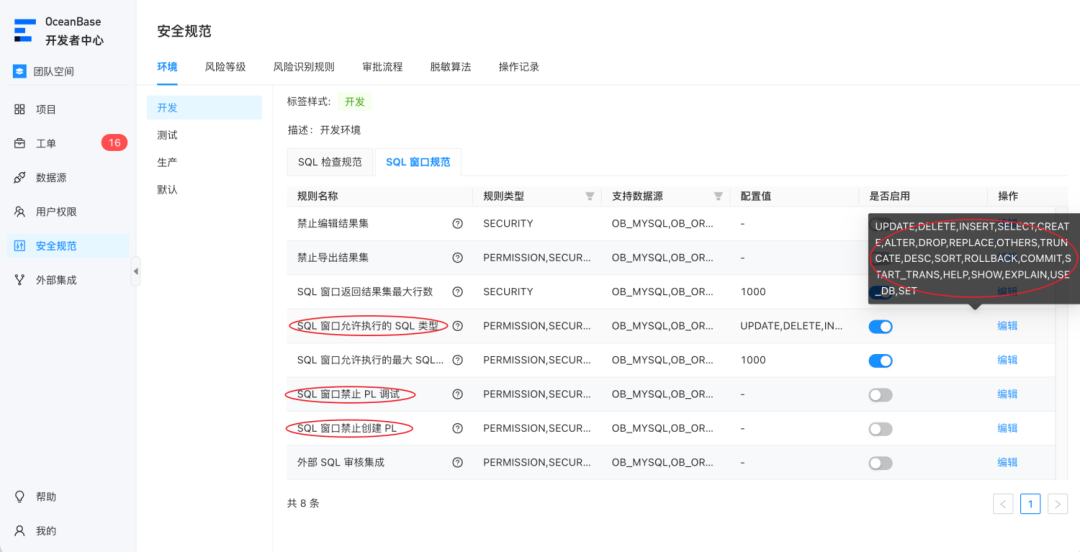
对于存储过程、程序包、触发器和自定义函数,我们目前尚未找到合适的方案来动态拦截它们对敏感数据的访问。但这并不会影响敏感数据管控的有效性。因为上述 4 种数据库对象访问敏感数据的前提是首先创建它们,而 ODC 最新版本(4.2.0)已经将这些数据库对象的 CREATE 权限和 PL 的调试与执行权限都纳入了管控(如下图所示 SQL 窗口规范),没有相应权限的用户将无法执行这些“危险”操作。因此,ODC 的敏感数据管控能力在各方面都形成了完备的闭环。

接下来我们将聚焦功能特性,从产品设计层面介绍 ODC 数据脱敏的实现原理。如果你对技术细节感兴趣,欢迎访问 ODC 的开源社区(https://github.com/oceanbase/odc),携手共建 ODC 开源宇宙 ~🚀 🚀 🚀
要实现数据脱敏,关键要解决两个问题:
-
如何知道数据库中的哪些列是敏感数据?
-
对敏感数据采用什么方式进行脱敏处理?
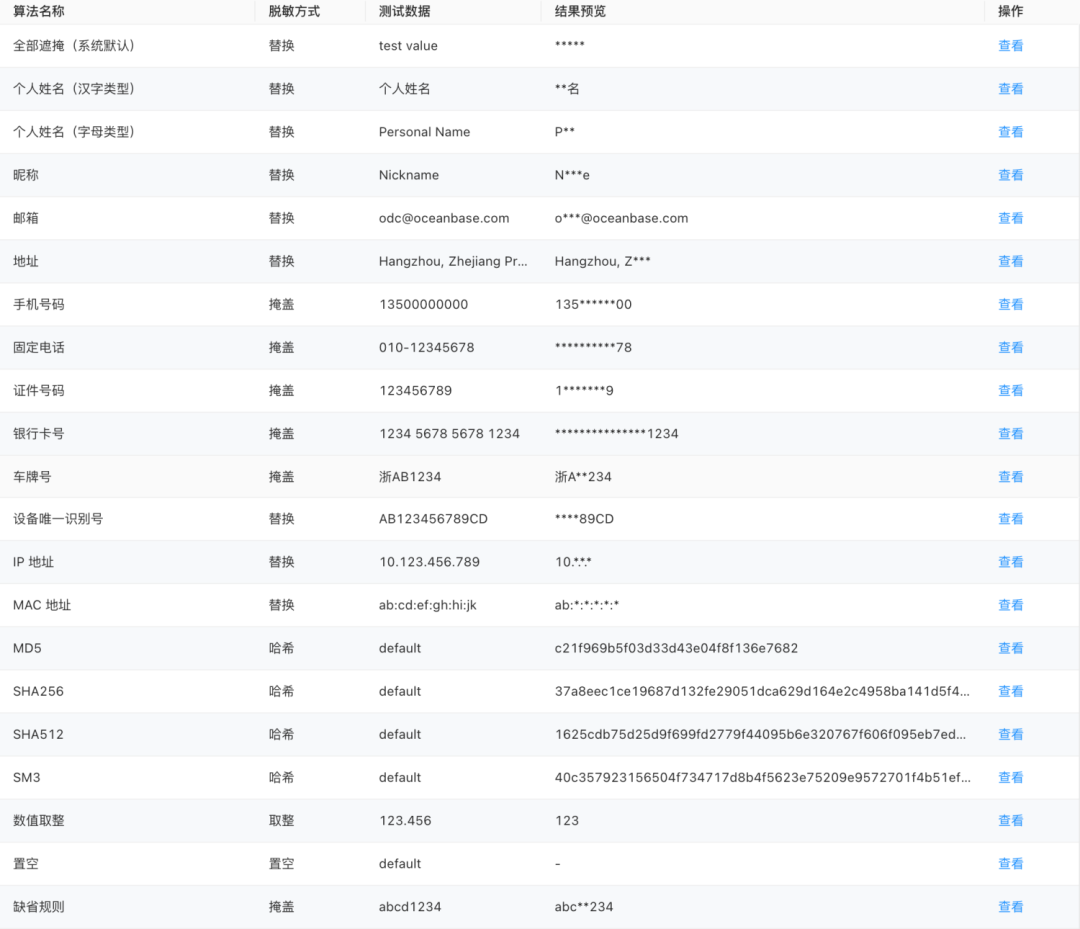
为了解决第一个问题,我们引入了敏感列的概念:将数据库中存储敏感数据的物理列标记为敏感列,在数据出库时,所有涉及敏感列的数据都会被视为敏感数据。至于第二个问题,我们提供了 21 种不同的数据脱敏算法,包括全脱敏和半脱敏方式,覆盖了中/英文姓名、手机号、邮箱、证件号码、地址、车牌号、IP 等常见敏感数据类型。
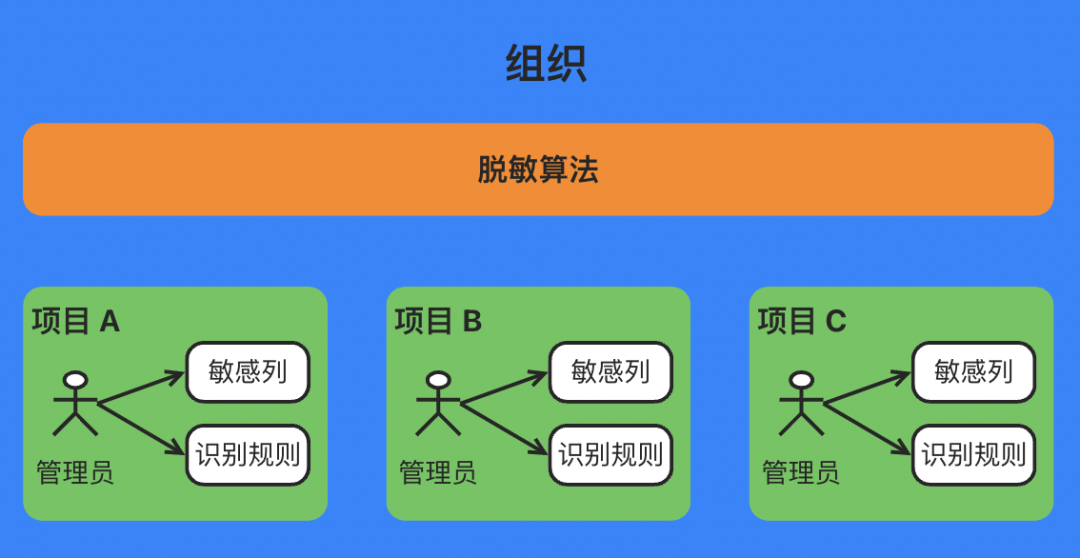
(一)领域模型
ODC 是多组织架构的,并且在 V4.2.0 开始引入了基于项目的管控模式:不同组织间的资源和数据完全隔离,同一组织内的多个项目可以共享同一个数据源。因此,为实现数据脱敏,我们做了下图所示的产品设计:
(二)脱敏算法
同一组织共用同一套脱敏算法,允许项目内所有成员查看脱敏算法、测试脱敏效果。蚂蚁集团在隐私计算和敏感数据保护方面一直处于国内第一梯队。因此,我们参考了蚂蚁集团的脱敏规范,提供了以下 21 种脱敏算法,能覆盖绝大部分应用场景。
(三)敏感数据管理
事实上,数据的敏感与否是与具体存储的内容相关的,往往只有项目内成员才知悉到底哪些列是需要脱敏的。因此,我们把敏感数据(即敏感列)放在项目级别,由项目管理员或 DBA 负责管理。为了保证脱敏结果符合预期,避免误判,用户可以主动将需要脱敏的数据列添加为敏感列。通过手动添加敏感列,依次选择敏感列所属的数据源、数据库、表和列然后添加即可。如果数据源中需要脱敏处理的列有很多,我们推荐使用自动扫描的方式。只需要根据敏感列所处的位置和基本属性,创建合适的识别规则,然后发起一个自动扫描任务即可。
为了最大程度满足用户的需求,ODC 支持三种方式配置敏感列的识别规则,分别是:
-
路径:就是根据敏感列所处的库、表、列来匹配。这种方式最为简单粗暴,能满足用户的大部分需求。
-
正则:基于正则表达式,根据库名、表名、列名和列备注来匹配。这种方式适用于敏感列分布在多个数据库,且需要批量添加的场景。
-
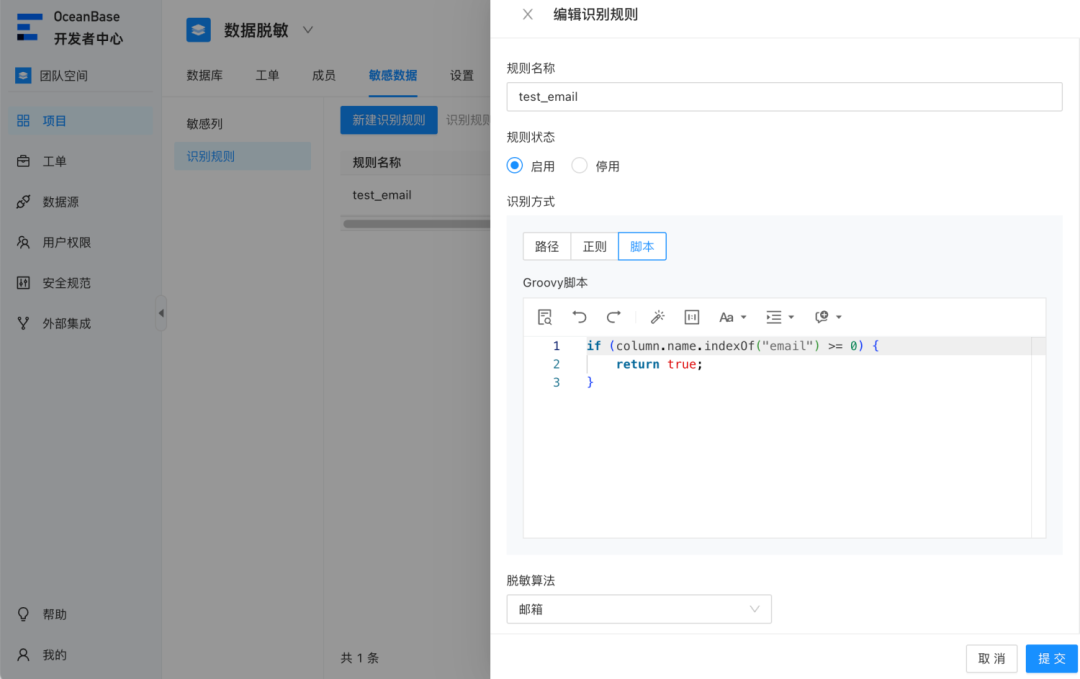
脚本:基于 Groovy 脚本匹配。这种方式非常灵活,可以实现大范围筛选,也可以实现特别细粒度的定制化匹配规则,非常推荐用户使用这种方法。只需花五分钟的时间熟悉 Groovy 语法,就可以愉快地 coding 识别规则。
举个例子,你希望将某个数据源下所有名为 email 的列设为敏感列,那只需要编写以下脚本识别规则:
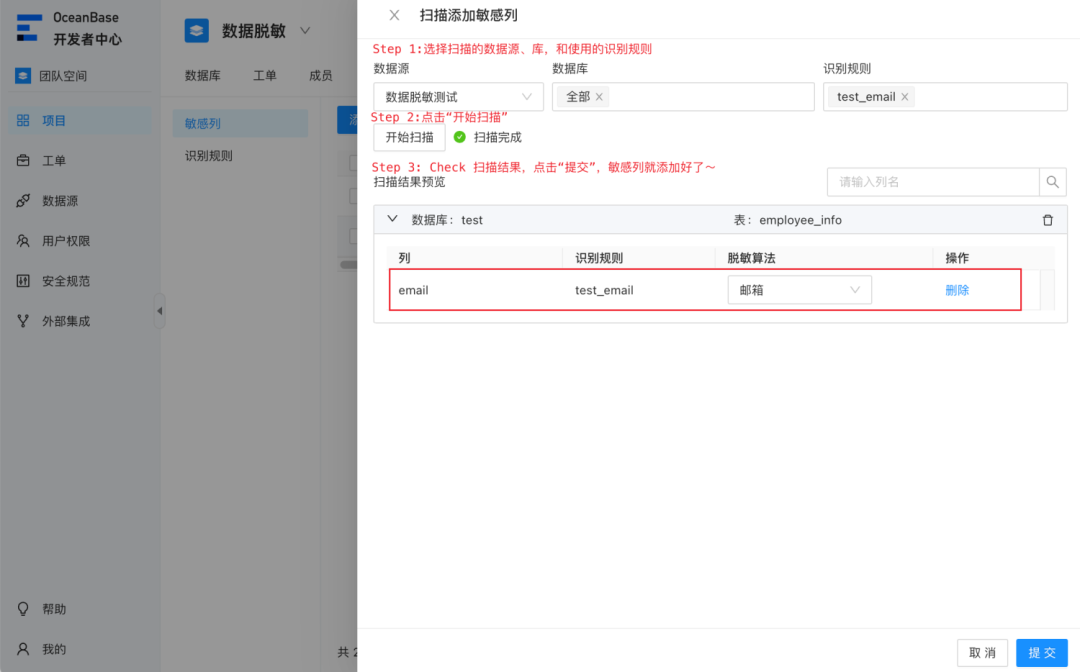
然后使用它来扫描即可(只需要三步):

在过去的两个半月里,ODC 团队不遗余力地呈现了数据脱敏功能,希望能够解决用户对数据安全的担忧。ODC 希望每一位用户可以更加安全、高效,同时愉快进行数据库协同开发。虽然 ODC 4.2.0 版本已经解决了从零到一的动态数据脱敏问题,但仍然需要管理员花费较多的精力来主动监控库中的敏感数据。实际上,ODC 目前只是一个执行者,需要用户判断哪些数据是敏感的。
未来,我们的目标是实现角色反转,让 ODC 能够主动帮助用户识别和提示可能包含敏感数据的情况,并建议使用何种脱敏算法来更好地保护这些数据。更智能、更无感的数据脱敏能力是我们下一步发展的方向。
注:本文中出现的测试数据均为虚构,如有雷同,纯属巧合。