本教程基于韦东山百问网出的 DShanMCU-RA6M5开发板 进行编写,需要的同学可以在这里获取: https://item.taobao.com/item.htm?id=728461040949
配套资料获取:https://renesas-docs.100ask.net
瑞萨MCU零基础入门系列教程汇总: https://blog.csdn.net/qq_35181236/article/details/132779862
第29章 改进型环形缓冲区
29.1 基本概念
环形缓冲区是一个先进先出(FIFO)的闭环的存储空间。通俗的理解为,在内存中规划了一块“圆形”的地,将该“圆形”进行N(Ring Buffer的大小)等分,如下图所示:

但是实际上,处理器的内存不可能是这样一个闭环的存储方式,而是一片连续的,有起始有结束的空间:

开发者在程序中只能申请一段有头有尾的内存,通过软件设计将这片内存实现为一个环形的缓冲区。
一般而言,对于环形缓冲区的操作需要了解几个基本单位:
- 内存起始地址pHead
- 内存结束地址pEnd
- 内存总大小Length
- 可写内存起始地址pwStart
- 可写内存大小wLength
- 可读内存起始地址prStart
- 可读内存大小rLength

可以发现这几个单位中是存在算术关系的:
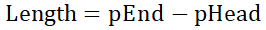 ①
①
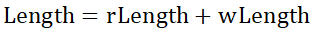 ②
②
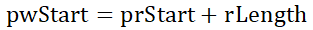 ③
③
将②式换算下,以可写内存大小为结果:
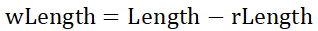
将可读的数据称作有效数据valid data,可读的起始内存地址叫有效数据起始地址pValid,可读的数据个数叫有效数据个数pValidLength。而可写的内存,位于有效数据之后,称之为pValidEnd:

基于以上信息,就可以将环形缓冲区的信息抽象为结构体RingBufferInfo:
typedef struct RingBuffInfo{
unsigned char *pHead;
unsigned char *pEnd;
unsigned char *pValid;
unsigned char *pValidEnd;
unsigned int nBufferLength;
unsigned int nValidLength;
}RingBuffInfo;
由于可写的数据个数是可以通过缓冲区大小nBufferLength和有效数据个数nValidLength计算得到,因而未将其封装到RingBufferInfo结构体中。
对于环形缓冲区,主要的操作有:申请和释放空间,读写数据、清除数据。将这些操作方法和缓冲区信息一起封装为结构体RingBuffer:
typedef struct RingBuffer{
RingBuffInfo info;
int (*Write)(struct RingBuffer *ptbuf, const unsigned char *src, unsigned int length);
int (*Read)(struct RingBuffer *ptbuf, unsigned char *dst, unsigned int length);
int (*Clear)(struct RingBuffer *ptbuf);
int (*Free)(struct RingBuffer *ptbuf);
struct RingBuffer *next;
}RingBuffer;
第07行的链表,用来管理多个环形缓冲区:把它们放在一个链表里。
29.2 申请缓冲区
先申请一个RingBuffer结构体,再申请存储数据的空间,最后初始化。代码如下:
struct RingBuffer *RingBufferNew(unsigned int length)
{
struct RingBuffer *ptbuf;
if(0 == length) return NULL;
ptbuf = (struct RingBuffer*)malloc(sizeof(struct RingBuffer));
if(NULL == ptbuf) return NULL;
if(NULL != ptbuf->info.pHead)
{
free(ptbuf->info.pHead);
}
ptbuf->info.pHead = (uint8_t*)malloc(length);
if(NULL == ptbuf->info.pHead)
{
printf("Error. Malloc %d bytes failed.\r\n", length);
return -EIO;
}
ptbuf->info.pValid = ptbuf->info.pValidEnd = ptbuf->info.pHead;
ptbuf->info.pEnd = ptbuf->info.pHead + length;
ptbuf->info.nValidLength = 0;
ptbuf->info.nBufferLength = length;
ptbuf->Write = RingBufferWrite;
ptbuf->Read = RingBufferRead;
ptbuf->Clear = RingBufferClear;
ptbuf->Free = RingBufferFree;
return ptbuf;
}
- 第06行:使用C库函数malloc申请一个RingBuffer结构体;
- 第12行:分配存储数据的内存;
- 第18~21行:初始化缓冲区的信息;
- 第23~26行:填充操作函数;
29.3 释放缓冲区
先是否数据存储空间,再释放RingBuffer结构体本身。代码如下:
static int RingBufferFree(struct RingBuffer *ptbuf)
{
if(ptbuf == NULL) return -EINVAL;
if(ptbuf->info.pHead==NULL) return -EINVAL;
free((uint8_t*)ptbuf->info.pHead);
ptbuf->info.pHead = NULL;
ptbuf->info.pValid = NULL;
ptbuf->info.pValidEnd = NULL;
ptbuf->info.pEnd = NULL;
ptbuf->info.nValidLength = 0;
free((struct RingBuffer *)ptbuf);
return ESUCCESS;
}
29.4 写数据到缓冲区
往缓冲区中写入数据需要考虑三个点:
- 剩下的空间是否足够?
- 超过空间的数据是丢还是留?
- 写入数据时如果越界了,就需要缓冲器的头部继续写
如果从pValidEnd开始写入数据不会超过缓冲区的结束地址,那么直接从pValidEnd处开始写入数据即可:
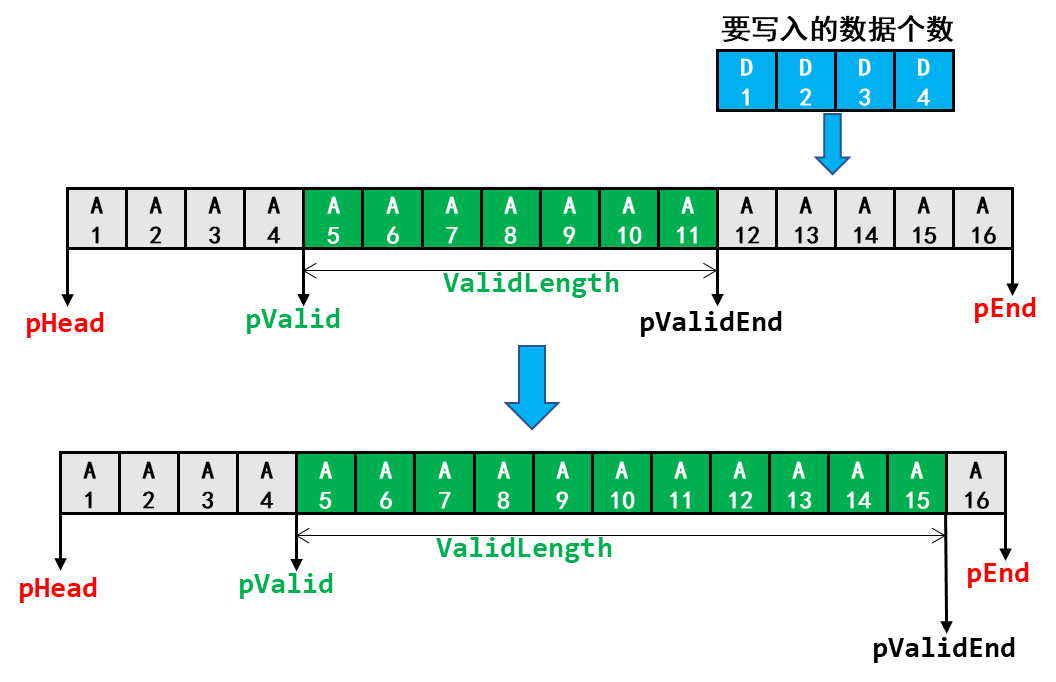
如果从pValidEnd开始写入数据会超过缓冲区的结束地址,那么就需要考虑很多:
- 计算从pValidEnd开始到pEnd可以写入多少个数据
- 还剩多少个数据需要从pHead处开始写
- 计算从pHead开始到pValid可以写入多少个数据,是否足够写入剩下的数据;不够的话如何处理?
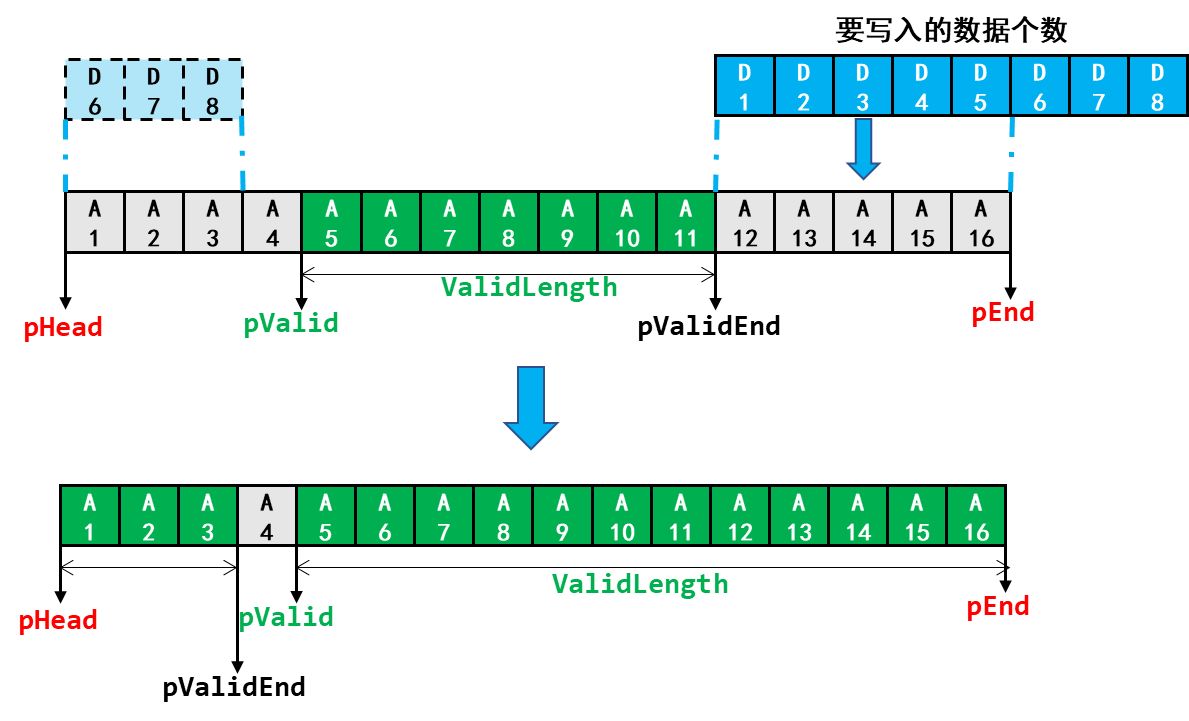
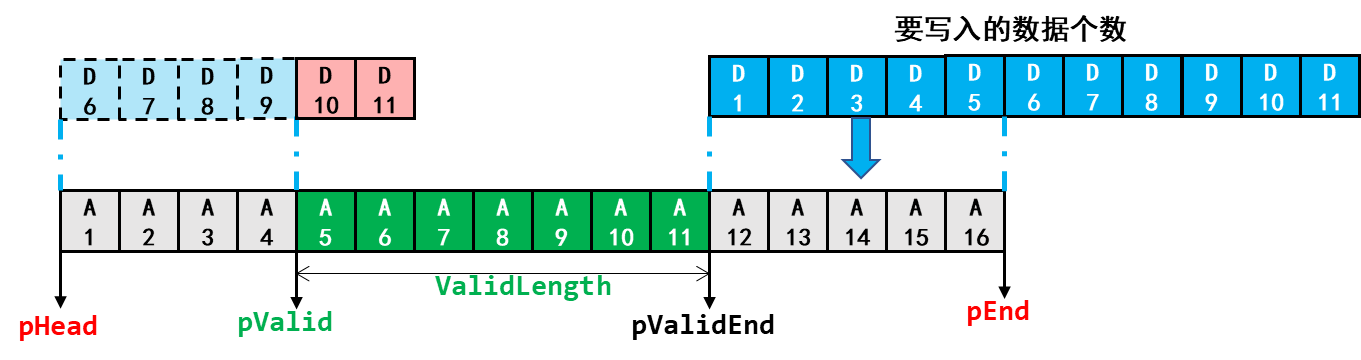
在本书实验例程中,如果出现了剩余空间不足以容纳新数据时,就用新数据覆盖旧数据:
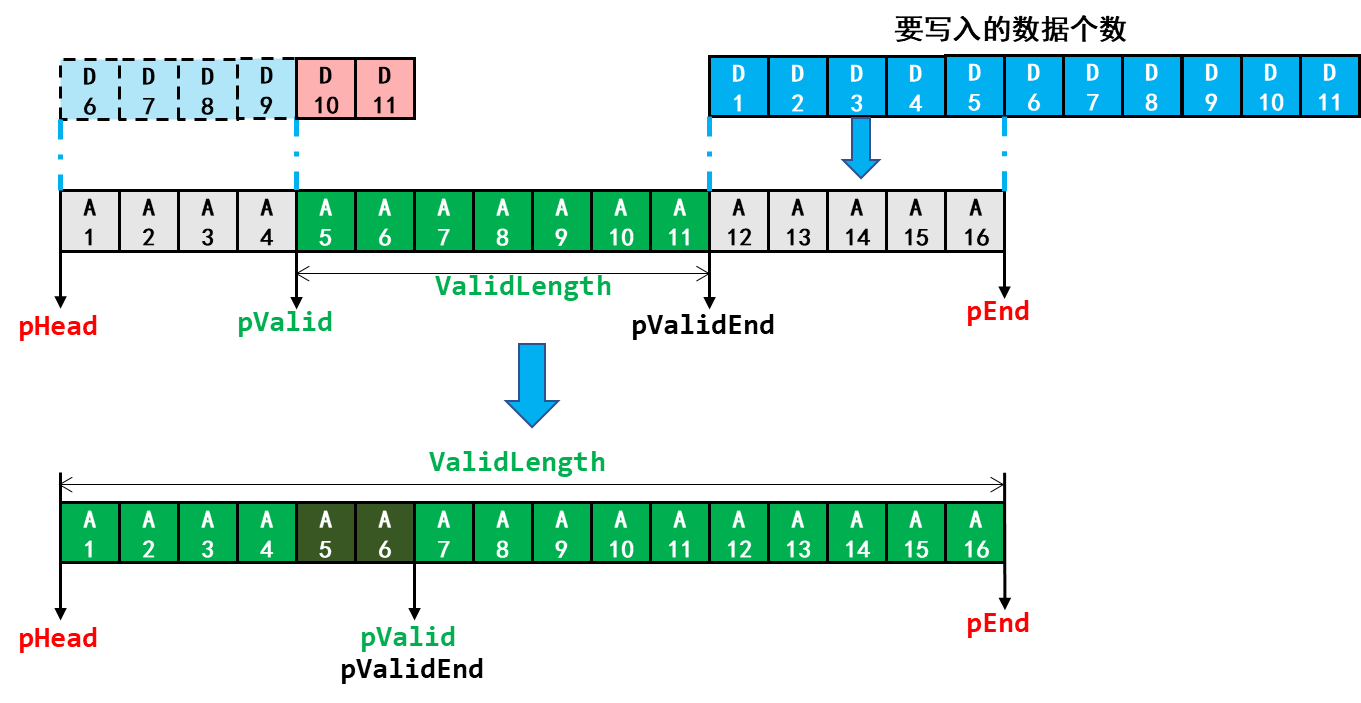
在这个过程中,有效数据的起始地址和结束地址,以及有效数据的个数,需要随着数据的写入跟着变化,这些数据的计算结合示意图可谓一目了然,此处就不再列出计算公式了。
如果缓冲区的剩余空间足够容纳新数据,那么写操作比较简单。代码如下:
static int RingBufferWrite(struct RingBuffer *ptbuf, const unsigned char *src, unsigned int length)
{
......(省略内容)
// copy buffer to pValidEnd
if( (ptbuf->info.pValidEnd + length) > ptbuf->info.pEnd ) // 超过了Buffer范围需要分为两段
{
len1 = (unsigned)(ptbuf->info.pEnd - ptbuf->info.pValidEnd);
len2 = length - len1;
memcpy((uint8_t*)ptbuf->info.pValidEnd, src, len1);
memcpy((uint8_t*)ptbuf->info.pHead, src + len1, len2);
ptbuf->info.pValidEnd = ptbuf->info.pHead + len2; // 更新有效数据区尾地址
}
else
{
memcpy((uint8_t*)ptbuf->info.pValidEnd, src, length);
ptbuf->info.pValidEnd = ptbuf->info.pValidEnd + length;
}
......(省略内容)
}
如果缓冲区的剩余空间不足以容纳新数据,在使用新数据覆盖老数据时,涉及的计算比较繁琐,代码如下:
static int RingBufferWrite(struct RingBuffer *ptbuf, const unsigned char *src, unsigned int length)
{
......(省略内容)
// 重新计算已使用区的起始位置
if( (ptbuf->info.nValidLength + length) > ptbuf->info.nBufferLength ) // 要写入的数据超过了缓冲区总长度,分为两段写
{
move_len = ptbuf->info.nValidLength + length - ptbuf->info.nBufferLength;
if( (ptbuf->info.pValid + move_len) > ptbuf->info.pEnd )
{
len1 = (unsigned)(ptbuf->info.pEnd - ptbuf->info.pValid);
len2 = move_len - len1;
ptbuf->info.pValid = ptbuf->info.pHead + len2;
}
else
{
ptbuf->info.pValid = ptbuf->info.pValid + move_len;
}
ptbuf->info.nValidLength = ptbuf->info.nBufferLength;
}
else
{
ptbuf->info.nValidLength = ptbuf->info.nValidLength + length;
}
return (int)length;
}
29.5 从缓冲区读数据
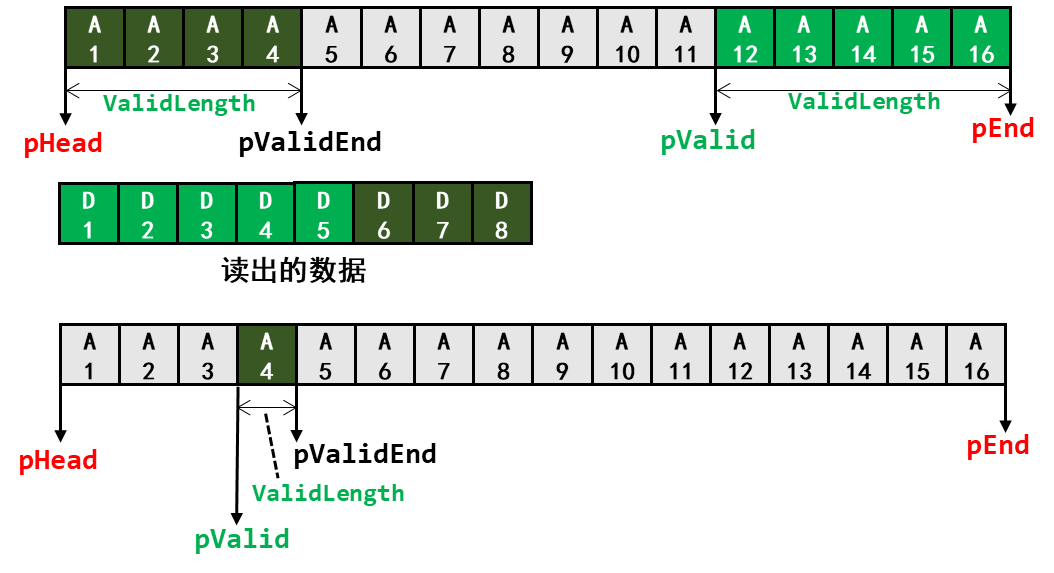
相比于写数据,读数据的操作就简单了许多。读数据时,从pValid处开始读,如果越过了pEnd,需要从pHead继续读取剩下的数据:
而如果从pValid处读取的数据个数不会越过pEnd,那么直接读出即可:
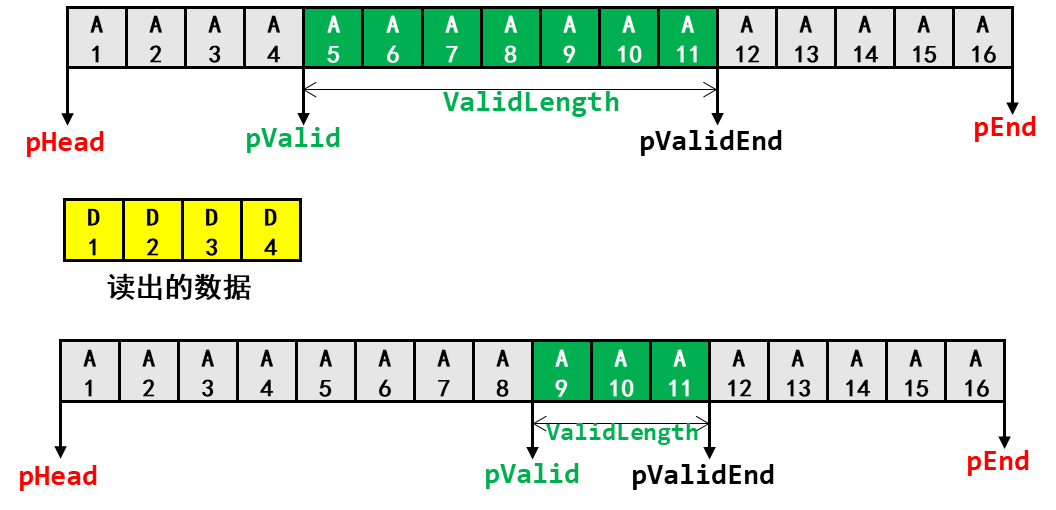
环形缓冲区的读函数代码如下:
static int RingBufferRead(struct RingBuffer *ptbuf, unsigned char *dst, unsigned int length)
{
unsigned int len1 = 0, len2 = 0;
if(ptbuf->info.pHead==NULL) return -EINVAL;
if(ptbuf->info.nValidLength==0) return -ENOMEM;
if(length > ptbuf->info.nValidLength)
{
length = ptbuf->info.nValidLength;
}
if( (ptbuf->info.pValid + length) > ptbuf->info.pEnd )
{
len1 = (unsigned int)(ptbuf->info.pEnd - ptbuf->info.pValid);
len2 = length - len1;
memcpy(dst, (uint8_t*)ptbuf->info.pValid, len1);
memcpy(dst + len1, (uint8_t*)ptbuf->info.pHead, len2);
ptbuf->info.pValid = ptbuf->info.pHead + len2;
}
else
{
memcpy(dst, (uint8_t*)ptbuf->info.pValid, length);
ptbuf->info.pValid = ptbuf->info.pValid + length;
}
ptbuf->info.nValidLength -= length;
return (int)length;
}
29.6 清除缓冲区
清除缓冲区时,让RingBuffer的各个成员恢复初始值即可:
static int RingBufferClear(struct RingBuffer *ptbuf)
{
if(ptbuf == NULL) return -EINVAL;
if(ptbuf->info.pHead==NULL) return -EINVAL;
if(ptbuf->info.pHead != NULL)
{
memset(ptbuf->info.pHead, 0, ptbuf->info.nBufferLength);
}
ptbuf->info.pValid = ptbuf->info.pValidEnd = ptbuf->info.pHead;
ptbuf->info.nValidLength = 0;
return ESUCCESS;
}