目录
- 一、机器翻译简介
- 1. 什么是机器翻译 (MT)?
- 2. 源语言和目标语言
- 3. 翻译模型
- 4. 上下文的重要性
- 二、基于规则的机器翻译 (RBMT)
- 1. 规则的制定
- 2. 词典和词汇选择
- 3. 限制与挑战
- 4. PyTorch实现
- 三、基于统计的机器翻译 (SMT)
- 1. 数据驱动
- 2. 短语对齐
- 3. 评分和选择
- 4. PyTorch实现
- 四、基于神经网络的机器翻译
- 1. Encoder-Decoder结构
- 2. Attention机制
- 3. 词嵌入
- 4. PyTorch实现
- 五、评价和评估方法
- 1. BLEU Score
- 2. METEOR
- 3. ROUGE
- 4. TER
- 5. 人工评估
机器翻译是使计算机能够将一种语言转化为另一种语言的技术领域。本文从简介、基于规则、统计和神经网络的方法入手,深入解析了各种机器翻译策略。同时,详细探讨了评估机器翻译性能的多种标准和工具,包括BLEU、METEOR等,以确保翻译的准确性和质量。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、机器翻译简介
机器翻译,作为自然语言处理的一个核心领域,一直都是研究者们关注的焦点。其目标是实现计算机自动将一种语言翻译成另一种语言,而不需要人类的参与。
1. 什么是机器翻译 (MT)?

机器翻译(MT)是一种自动将源语言文本翻译成目标语言的技术。它使用特定的算法和模型,尝试在不同语言之间实现最佳的语义映射。
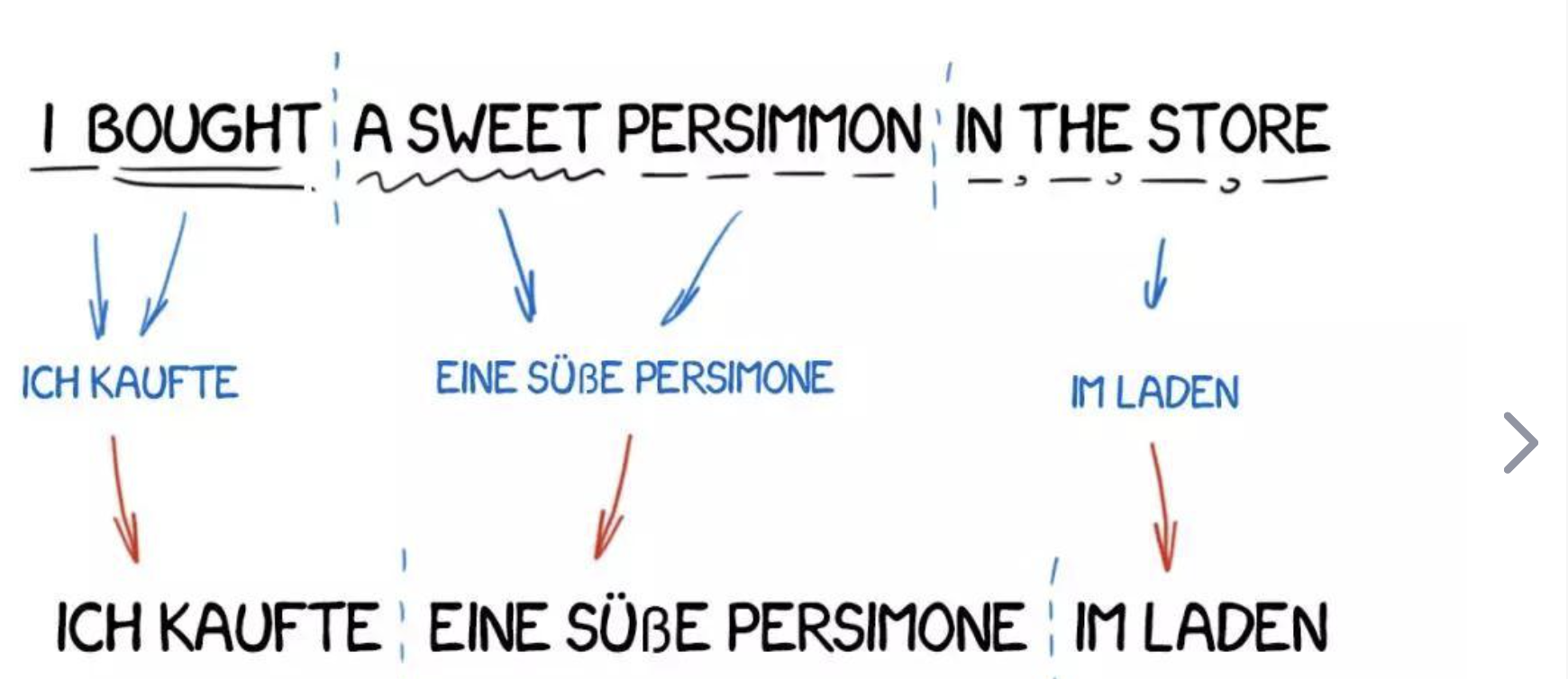
示例: 当你输入"Hello, world!“到Google翻译,并将其从英语翻译成法语,你会得到"Bonjour le monde!”。这就是机器翻译的一个简单示例。
2. 源语言和目标语言
- 源语言: 你想要翻译的原始文本的语言。
示例: 在前面的例子中,"Hello, world!"的语言,即英语,就是源语言。
- 目标语言: 你想要将源语言文本翻译成的语言。
示例: 在上述示例中,法语是目标语言。
3. 翻译模型
机器翻译的核心是翻译模型,它可以基于规则、基于统计或基于神经网络。这些模型都试图找到最佳的翻译,但它们的工作原理和侧重点有所不同。
示例: 一个基于规则的翻译模型可能会有一个词典来查找单词的直接对应关系。所以,它可能会将英文的"cat"直接翻译成法文的"chat"。而一个基于统计的模型可能会考虑语料库中的短语和句子的出现频率,来判断"cat"在某个上下文中是否应该翻译成"chat"。
4. 上下文的重要性
在机器翻译中,单独的单词翻译通常是不够的。上下文对于获得准确翻译至关重要。一些词在不同的上下文中可能有不同的含义和翻译。
示例: 英文单词"bank"可以指"河岸"也可以指"银行"。如果上下文中提到了"money",那么正确的翻译可能是"银行"。而如果上下文中提到了"river",则"bank"应该被翻译为"河岸"。
以上内容提供了机器翻译的一个简要介绍。从定义到各种细节,每一部分都是为了帮助读者更好地理解这一复杂但令人兴奋的技术领域。
二、基于规则的机器翻译 (RBMT)
基于规则的机器翻译(RBMT)是一种利用语言学规则将源语言文本转换为目标语言文本的技术。这些规则通常由语言学家手工编写,覆盖了语法、词汇和其他语言相关的特性。
1. 规则的制定
在RBMT中,语言学家需要为源语言和目标语言编写大量的转换规则。这些规则描述了如何根据源语言的语法结构将其转换为目标语言的语法结构。
示例: 在英法翻译中,英文的形容词通常位于名词之前,而法语的形容词则通常位于名词之后。因此,规则可能会指示将"red apple"翻译为"pomme rouge"。
2. 词典和词汇选择
除了语法转换规则,RBMT还依赖于详细的双语词典。这些词典包含了源语言和目标语言之间的单词和短语的对应关系。
示例: 词典可能会指出英文单词"book"可以翻译为法文的"livre"。
3. 限制与挑战
尽管RBMT在某些领域和应用中可以提供相对准确的翻译,但它也面临着一些限制。规则的数量可能会变得非常庞大,难以维护;并且,对于某些复杂和歧义的句子,规则可能无法提供准确的翻译。
示例: “I read books on the bank.” 这句话中的"bank"是指"河岸"还是"银行"?没有上下文,基于规则的翻译系统可能会难以做出准确的选择。
4. PyTorch实现
虽然现代的机器翻译系统很少完全依赖于RBMT,但我们可以简单地使用PyTorch来模拟一个简化版的RBMT系统。
import torch
# 假设我们已经有了一个英法词典
dictionary = {
"red": "rouge",
"apple": "pomme"
}
def rule_based_translation(sentence: str) -> str:
translated_words = []
for word in sentence.split():
translated_words.append(dictionary.get(word, word))
return ' '.join(translated_words)
# 输入输出示例
sentence = "red apple"
print(rule_based_translation(sentence)) # 输出: rouge pomme
在这个简单的例子中,我们定义了一个基本的英法词典,并创建了一个函数来执行基于规则的翻译。这只是一个非常简化的示例,真实的RBMT系统将涉及更复杂的语法和结构转换规则。
三、基于统计的机器翻译 (SMT)
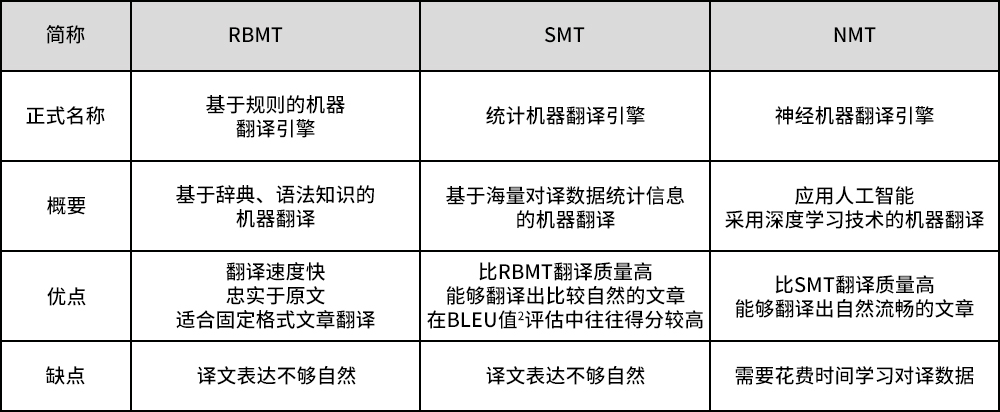
基于统计的机器翻译 (SMT) 利用统计模型从大量双语文本数据中学习如何将源语言翻译为目标语言。与依赖语言学家手工编写规则的RBMT不同,SMT自动从数据中学习翻译规则和模式。
1. 数据驱动
SMT系统通常从双语语料库(包含源语言文本和其对应的目标语言翻译)中学习。通过分析成千上万的句子对,系统学会了词语、短语和句子的最有可能的翻译。
示例: 如果在许多不同的句子对中,“cat”经常被翻译为“chat”,系统将学习到这种对应关系。
2. 短语对齐
SMT通常使用所谓的“短语表”,这是从双语语料库中自动提取的短语对齐的列表。
示例: 系统可能会从句子对中学习到"take a break"对应于法文中的"prendre une pause"。
3. 评分和选择
SMT使用多个统计模型来评估和选择最佳的翻译。这包括语言模型(评估目标语言翻译的流畅性)和翻译模型(评估翻译的准确性)。
示例: 在翻译"apple pie"时,系统可能会生成多个候选翻译,然后选择评分最高的那个。
4. PyTorch实现
完整的SMT系统非常复杂,涉及多个组件和复杂的模型。但为了说明,我们可以使用PyTorch创建一个简化的基于统计的词对齐模型:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们有一些双语句子对数据
source_sentences = ["apple", "red fruit"]
target_sentences = ["pomme", "fruit rouge"]
# 将句子转换为单词索引
source_vocab = {"apple": 0, "red": 1, "fruit": 2}
target_vocab = {"pomme": 0, "fruit": 1, "rouge": 2}
source_indices = [[source_vocab[word] for word in sentence.split()] for sentence in source_sentences]
target_indices = [[target_vocab[word] for word in sentence.split()] for sentence in target_sentences]
# 简单的对齐模型
class AlignmentModel(nn.Module):
def __init__(self, source_vocab_size, target_vocab_size, embedding_dim=8):
super(AlignmentModel, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size, embedding_dim)
self.target_embedding = nn.Embedding(target_vocab_size, embedding_dim)
self.alignment = nn.Linear(embedding_dim, embedding_dim, bias=False)
def forward(self, source, target):
source_embed = self.source_embedding(source)
target_embed = self.target_embedding(target)
scores = torch.matmul(source_embed, self.alignment(target_embed).transpose(1, 2))
return scores
model = AlignmentModel(len(source_vocab), len(target_vocab))
criterion = nn.CosineEmbeddingLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(1000):
total_loss = 0
for src, tgt in zip(source_indices, target_indices):
src = torch.LongTensor(src)
tgt = torch.LongTensor(tgt)
scores = model(src.unsqueeze(0), tgt.unsqueeze(0))
loss = criterion(scores, torch.ones_like(scores), torch.tensor(1.0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {total_loss}")
# 输入: apple
# 输出: pomme (根据得分选择最佳匹配的词)
此代码为一个简单的词对齐模型,它试图学习源词和目标词之间的对齐关系。这只是SMT的冰山一角,完整的系统会涉及句子级别的对齐、短语提取、多个统计模型等。
四、基于神经网络的机器翻译
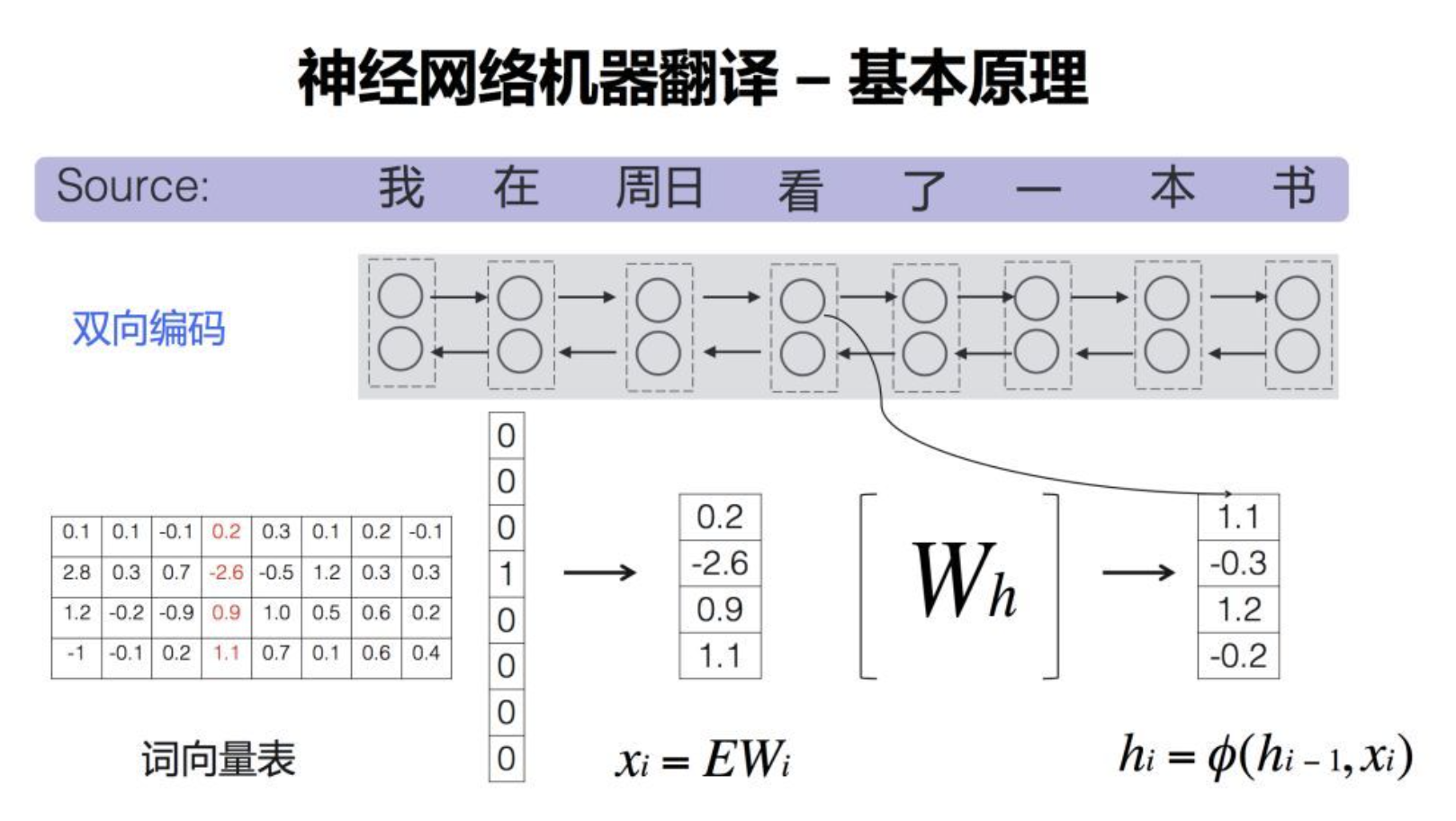
基于神经网络的机器翻译(NMT)使用深度学习技术,特别是递归神经网络(RNN)、长短时记忆网络(LSTM)或Transformer结构,以端到端的方式进行翻译。它直接从源语言到目标语言的句子或序列进行映射,不需要复杂的特性工程或中间步骤。
1. Encoder-Decoder结构
NMT的核心是Encoder-Decoder结构。Encoder将源语句编码为一个固定大小的向量,而Decoder将这个向量解码为目标语句。
示例: 在将英文句子 “I am learning” 翻译成法文 “Je suis en train d’apprendre” 时,Encoder首先将英文句子转换为一个向量,然后Decoder使用这个向量来生成法文句子。
2. Attention机制
Attention机制允许模型在解码时“关注”源句子中的不同部分。这使得翻译更加准确,尤其是对于长句子。
示例: 在翻译 “I am learning to translate with neural networks” 时,当模型生成 “réseaux”(网络)这个词时,它可能会特别关注源句中的 “networks”。
3. 词嵌入
词嵌入是将单词转换为向量的技术,这些向量捕捉单词的语义信息。NMT模型通常使用预训练的词嵌入,如Word2Vec或GloVe,但也可以在训练过程中学习词嵌入。
示例: “king” 和 “queen” 的向量可能会在向量空间中很接近,因为它们都是关于皇室的。
4. PyTorch实现
以下是一个简单的基于LSTM和Attention的NMT模型实现示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 为简化,定义一个小的词汇表和数据
source_vocab = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "I": 3, "am": 4, "learning": 5}
target_vocab = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "Je": 3, "suis": 4, "apprenant": 5}
source_sentences = [["<SOS>", "I", "am", "learning", "<EOS>"]]
target_sentences = [["<SOS>", "Je", "suis", "apprenant", "<EOS>"]]
# 参数
embedding_dim = 256
hidden_dim = 512
vocab_size = len(source_vocab)
target_vocab_size = len(target_vocab)
# Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
def forward(self, x):
x = self.embedding(x)
outputs, (hidden, cell) = self.lstm(x)
return outputs, (hidden, cell)
# Attention and Decoder
class DecoderWithAttention(nn.Module):
def __init__(self):
super(DecoderWithAttention, self).__init__()
self.embedding = nn.Embedding(target_vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim + hidden_dim, hidden_dim, batch_first=True)
self.attention = nn.Linear(hidden_dim + hidden_dim, 1)
self.fc = nn.Linear(hidden_dim, target_vocab_size)
def forward(self, x, encoder_outputs, hidden, cell):
x = self.embedding(x)
seq_length = encoder_outputs.shape[1]
hidden_repeat = hidden.repeat(seq_length, 1, 1).permute(1, 0, 2)
attention_weights = torch.tanh(self.attention(torch.cat((encoder_outputs, hidden_repeat), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
context = torch.sum(attention_weights * encoder_outputs, dim=1).unsqueeze(1)
x = torch.cat((x, context), dim=2)
outputs, (hidden, cell) = self.lstm(x, (hidden, cell))
x = self.fc(outputs)
return x, hidden, cell
# Training loop
encoder = Encoder()
decoder = DecoderWithAttention()
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=0.001)
criterion = nn.CrossEntropyLoss(ignore_index=0
)
for epoch in range(1000):
for src, tgt in zip(source_sentences, target_sentences):
src = torch.tensor([source_vocab[word] for word in src]).unsqueeze(0)
tgt = torch.tensor([target_vocab[word] for word in tgt]).unsqueeze(0)
optimizer.zero_grad()
encoder_outputs, (hidden, cell) = encoder(src)
decoder_input = tgt[:, :-1]
decoder_output, _, _ = decoder(decoder_input, encoder_outputs, hidden, cell)
loss = criterion(decoder_output.squeeze(1), tgt[:, 1:].squeeze(1))
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 输入: <SOS> I am learning <EOS>
# 输出: <SOS> Je suis apprenant <EOS>
此代码展示了一个基于注意力的NMT模型,从源语句到目标语句的映射。这只是NMT的基础,更高级的模型如Transformer会有更多的细节和技术要点。
五、评价和评估方法
机器翻译的评价是衡量模型性能的关键部分。准确、流畅和自然的翻译输出是我们的目标,但如何量化这些目标并确定模型的质量呢?
1. BLEU Score
BLEU(Bilingual Evaluation Understudy)分数是机器翻译中最常用的自动评估方法。它通过比较机器翻译输出和多个参考翻译之间的n-gram重叠来工作。
示例: 假设机器的输出是 “the cat is on the mat”,而参考输出是 “the cat is sitting on the mat”。1-gram精度是5/6,2-gram精度是4/5,以此类推。BLEU分数会考虑到这些各级的精度。
2. METEOR
METEOR(Metric for Evaluation of Translation with Explicit ORdering)是另一个评估机器翻译的方法,它考虑了同义词匹配、词干匹配以及词序。
示例: 如果机器输出是 “the pet is on the rug”,而参考翻译是 “the cat is on the mat”,尽管有些词不完全匹配,但METEOR会认为"pet"和"cat"、"rug"和"mat"之间有某种相似性。
3. ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 通常用于评估自动文摘,但也可以用于机器翻译。它考虑了机器翻译输出和参考翻译之间的n-gram的召回率。
示例: 对于同样的句子 “the cat is on the mat” 和 “the cat is sitting on the mat”,ROUGE-1召回率为6/7。
4. TER
TER (Translation Edit Rate) 衡量了将机器翻译输出转换为参考翻译所需的最少编辑次数(如插入、删除、替换等)。
示例: 对于 “the cat sat on the mat” 和 “the cat is sitting on the mat”,TER是1/7,因为需要添加一个"is"。
5. 人工评估
尽管自动评估方法提供了快速的反馈,但人工评估仍然是确保翻译质量的金标准。评估者通常会根据准确性、流畅性和是否忠实于源文本来评分。
示例: 一个句子可能获得满分的BLEU分数,但如果其翻译内容与源内容的意图不符,或者读起来不自然,那么人类评估者可能会给予较低的评分。
总的来说,评估机器翻译的性能是一个多方面的任务,涉及到多种工具和方法。理想情况下,研究者和开发者会结合多种评估方法,以获得对模型性能的全面了解。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。