import torch
from torch import nn
from d2l import torch as d2l
4.6.1 重新审视过拟合
整节理论,详见书本。
4.6.2 扰动的稳健性
整节理论,详见书本。
4.6.3 实践中的暂退法
整节理论,详见书本。
4.6.4 从零开始实现
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float() # 从均匀分布U[0,1]中抽取与神经网络同维度的样本,保留大于 dropout 的样本
return mask * X / (1.0 - dropout)
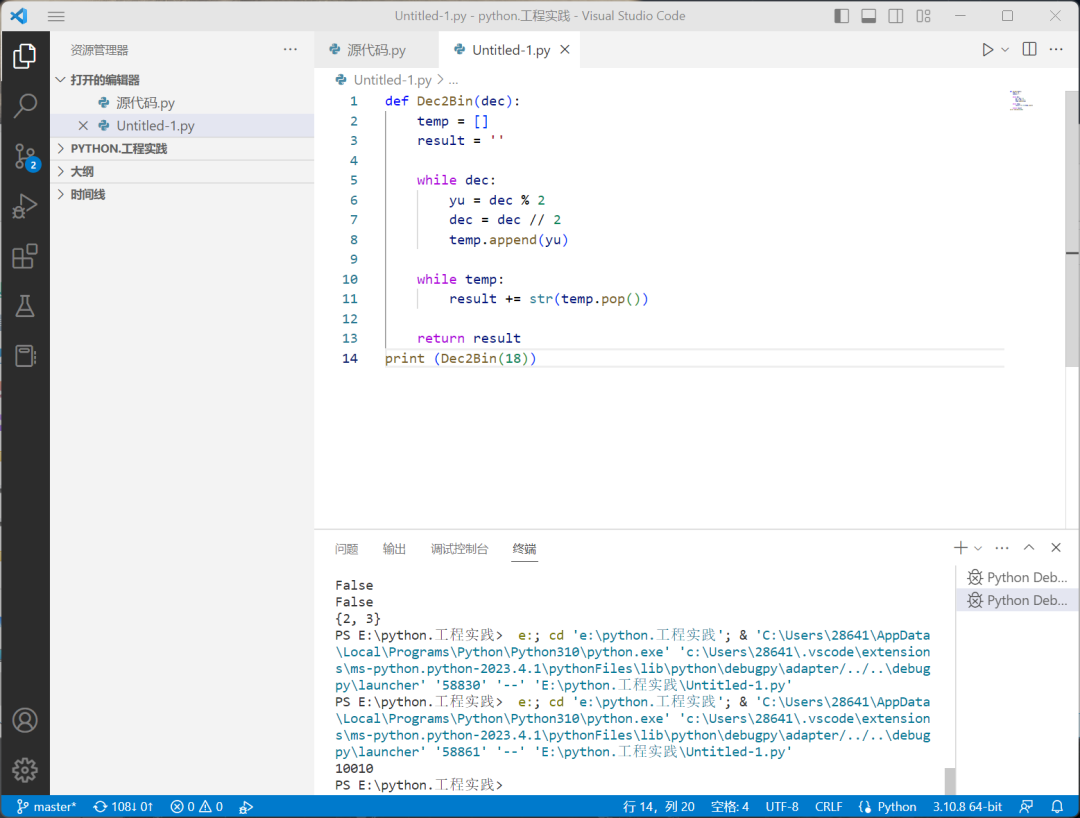
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 0., 6., 0., 10., 12., 0.],
[16., 0., 0., 0., 24., 26., 0., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
- 定义模型参数
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
-
定义模型
将暂退法应用于激活函数之后每个隐藏层的输出,常见的技巧是在靠近输入层的地方设置较低的暂退概率
dropout1, dropout2 = 0.2, 0.5 # 将第一个和第二个隐藏层的暂退概率分别设置为 0.2 和 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
- 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

4.6.5 简洁实现
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Dropout(p=0.2, inplace=False)
(4): Linear(in_features=256, out_features=256, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=256, out_features=10, bias=True)
)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

练习
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
(1)如果更改第一层和第二层的暂退概率,会出现什么情况?具体说说,如果交换这两个层会出现什么问题?设计一个实验来回答这些问题,定量描述该结果,并总结定性的结论。
for dropouts in [(0.1, 0.5), (0.1, 0.6), (0.2, 0.5), (0.2, 0.6), (0.5, 0.2)]:
net0 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropouts[0]),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropouts[1]),
nn.Linear(256, 10))
net0.apply(init_weights)
trainer0 = torch.optim.SGD(net0.parameters(), lr=lr)
d2l.train_ch3(net0, train_iter, test_iter, loss, num_epochs, trainer0)





虽然区别不大,但确实是靠近输入层的暂退概率低一点好些。
(2)增加训练轮数,并将使用暂退法和不使用暂退法时获得的结果进行比较。
num_epochs1, lr, batch_size = 15, 0.5, 256
net1 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 10))
net2 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10))
net1.apply(init_weights)
net2.apply(init_weights)
trainer1 = torch.optim.SGD(net1.parameters(), lr=lr)
d2l.train_ch3(net1, train_iter, test_iter, loss, num_epochs1, trainer1)

trainer2 = torch.optim.SGD(net2.parameters(), lr=lr)
d2l.train_ch3(net2, train_iter, test_iter, loss, num_epochs1, trainer2)

用暂退法确实能缓解过拟合现象。
(3)当使用或不使用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以展现这两个模型的每个隐藏层中的激活值的方差是如何随时间变化的。
不会画,略 。
(4)为什么测试时通常不使用暂退法?
使用暂退法是为了减少训练过程中的过拟合现象,测试的目的并非为了训练,而是要一个结果,网络已经固定,当然无须使用暂退法。
(5)以本节中的模型为例,比较使用暂退法和权重衰减的效果。如果同时使用暂退法和权重衰减,会出现什么情况?结果是累加的吗?收益是否减少(或更糟)?它们互相抵消了吗?
不会,略。
(6)如果我们将暂退法应用到权重矩阵的各个权重,而不是激活值,会发生什么?
net3 = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.Dropout(0.2),
nn.ReLU(),
nn.Linear(256, 256),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(256, 10))
net3.apply(init_weights)
trainer3 = torch.optim.SGD(net3.parameters(), lr=lr)
d2l.train_ch3(net3, train_iter, test_iter, loss, num_epochs, trainer3)

目测没什么差别
(7)开发一种用于在每一层注入噪声的技术,该技术不同于标准的暂退法技术。尝试开发一种在 Fashion-MINIST 数据集(对于固定架构)上性能优于暂退法的方法。
不会,略。