部署kibana可视化平台
案例版本:kibana 8.6.2
1、下载
去官网中查找与安装的ES版本一致的安装包:官网kibana下载。
可以选择自行下载好后放入服务器中进行安装,也可以使用wget下载:
# 下载
cd /home/elasticsearch/kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.6.2-linux-x86_64.tar.gz
# 解压到对应目录
tar -zxvf kibana-8.6.2-linux-x86_64.tar.gz
2、配置kibana
# 进入到kibana的config目录
cd /home/elasticsearch/kibana/kibana-8.6.2/config/
# 修改配置
vim kibana.yml
# 添加以下内容
# 端口号
server.port: 9898
# 任意地址都可以访问
server.host: "0.0.0.0"
# 查询的Elasticsearch实例的URL;安装在本地,按实际的情况填写
elasticsearch.hosts: ["http://192.168.127.10:9200","http://192.168.127.11:9200"]
# 访问elasticsearchd的认证
# 集群访问密码中的kibana账号密码
elasticsearch.username: "kibana“
elasticsearch.password: "123456"
# 支持的语言设置
i18n.locale: "zh-CN"
3、启动kibana
cd /home/elasticsearch/kibana/kibana-8.6.2
# 保持后台启动
nohup bin/kibana &
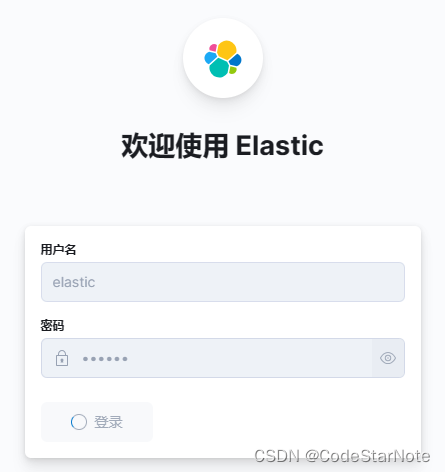
4、访问web
地址:http://192.168.127.10:9898
输入账号密码即可访问(注意是ES的elastic账户)。
5、基本使用操作
5.0 进入开发工具
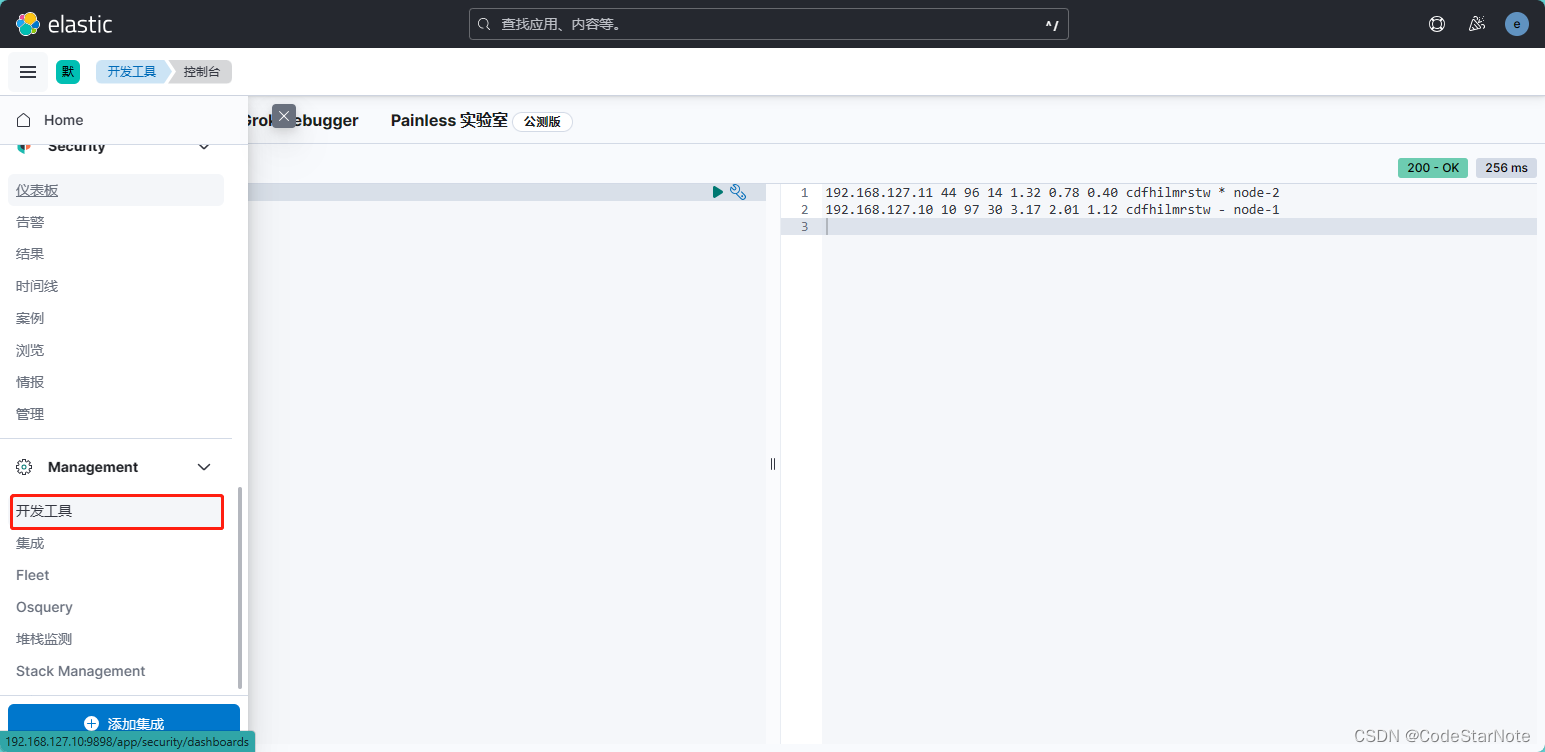
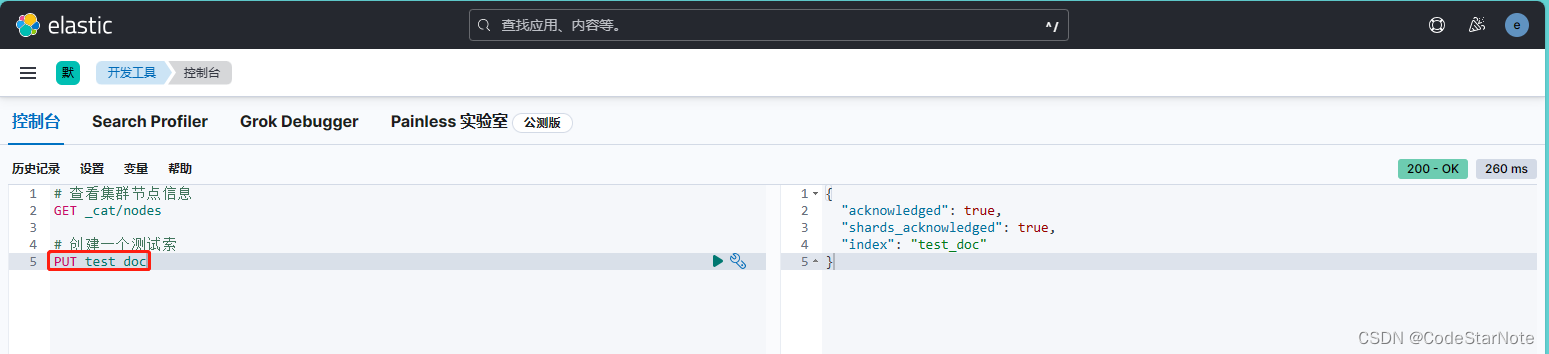
5.1 查看集群节点信息:
GET _cat/nodes

5.2 创建一个测试索引
PUT test_doc
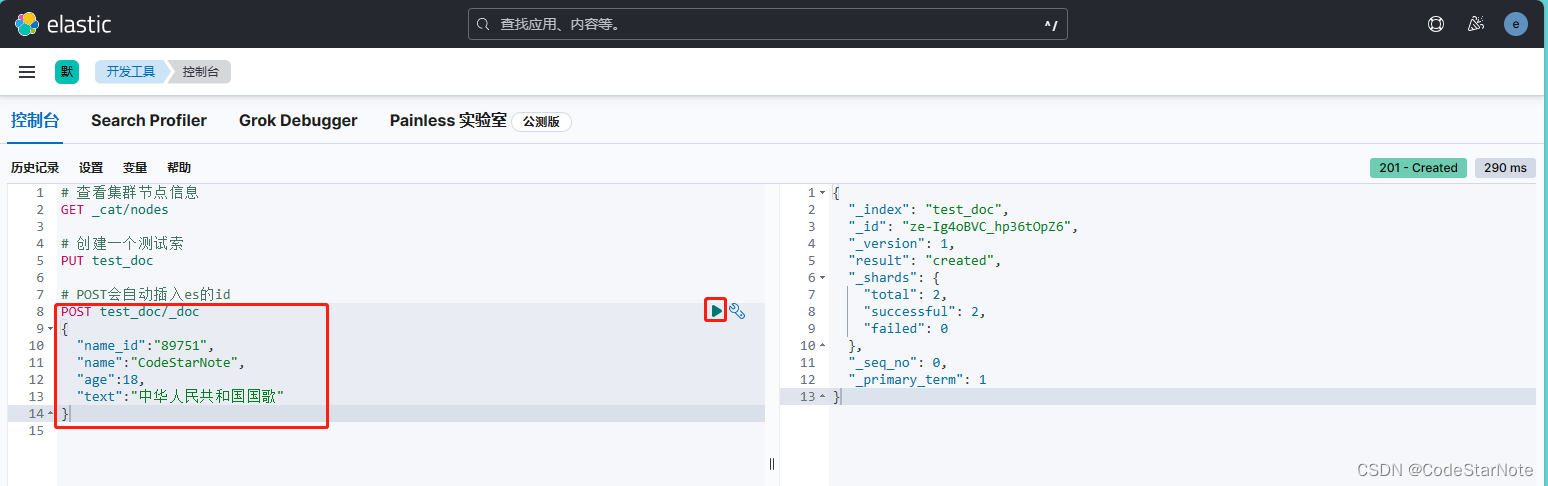
5.3 插入数据
#POST会自动帮我们插入es的id
POST test_doc/_doc
{
"name_id":"89751",
"name":"CodeStarNote",
"age":18,
"text":"中华人民共和国国歌"
}
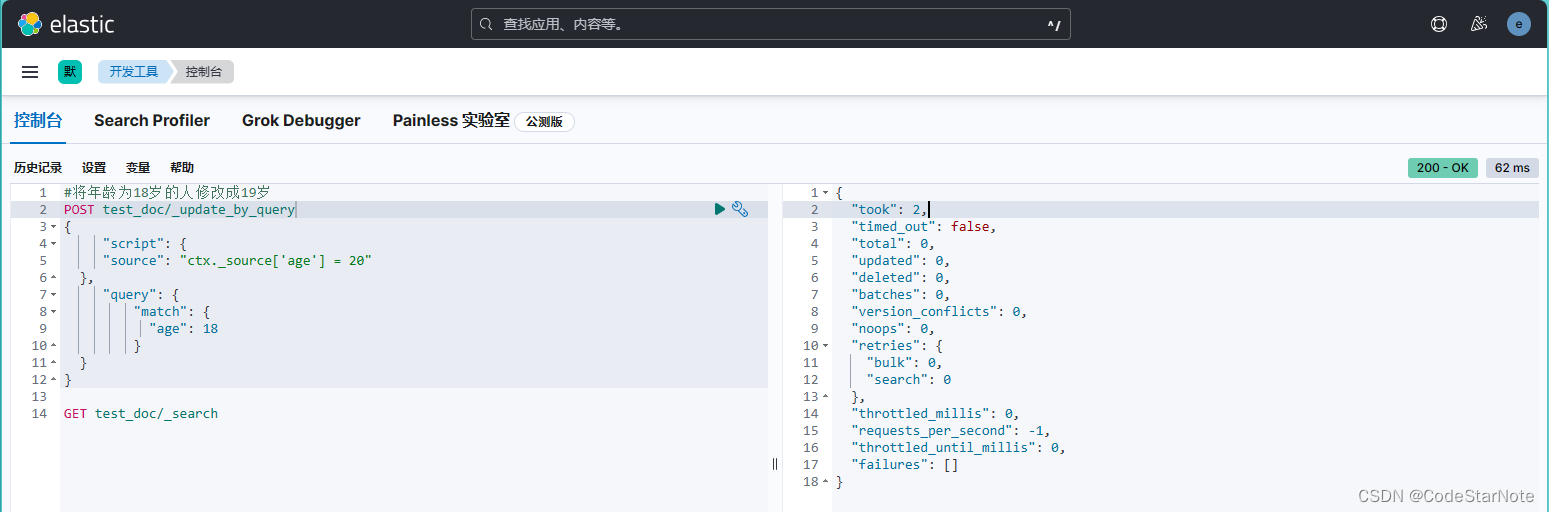
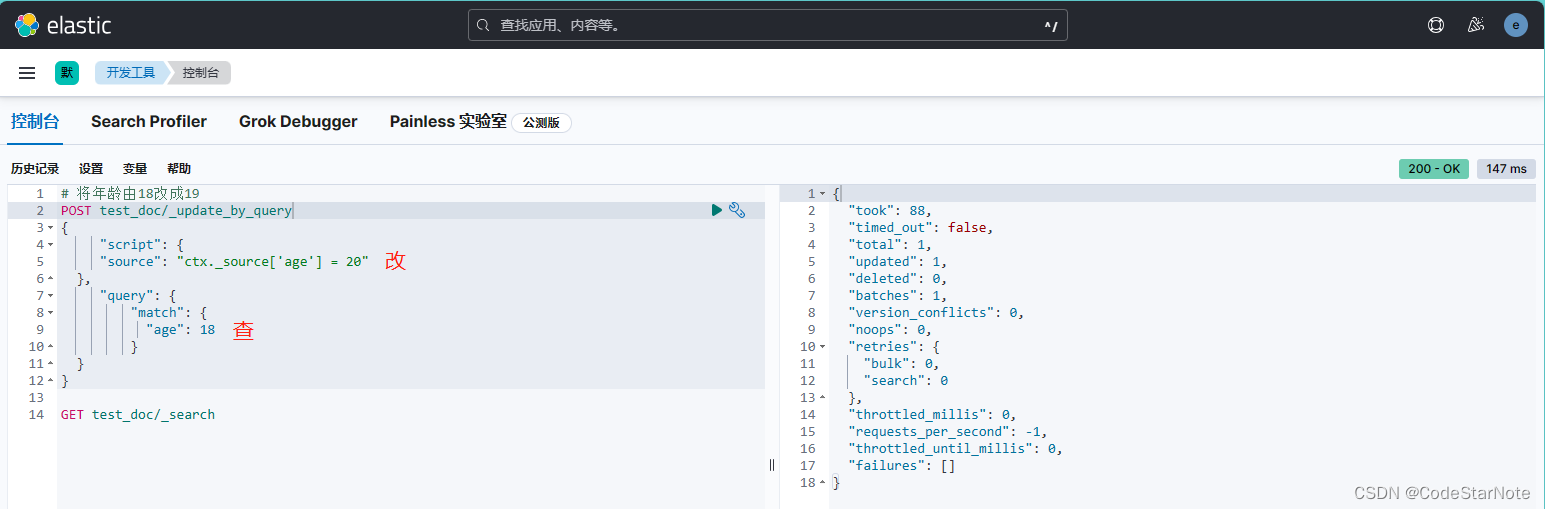
5.4 修改指定条件的数据
# 将年龄由18改成19
POST test_doc/_update_by_query
{
"script": {
"source": "ctx._source['age'] = 20"
},
"query": {
"match": {
"age": 18
}
}
}
使用PUT加id也可以直接修改或者新增字段。
5.5 查询指定条件的文档
通过IK分词器可以做到分词查询
# 新增一条age为15的数据
POST test_doc/_doc
{
"name_id":"89752",
"name":"CodeStarNote2",
"age":15,
"text":"中华人民共和国国歌2"
}
# 查询test包含“国歌”并且年龄大于18的数据
GET test_doc/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"text": "国歌"
}
},
{
"range":{
"age": {
"gte": 18
}
}
}
]
}
}
}
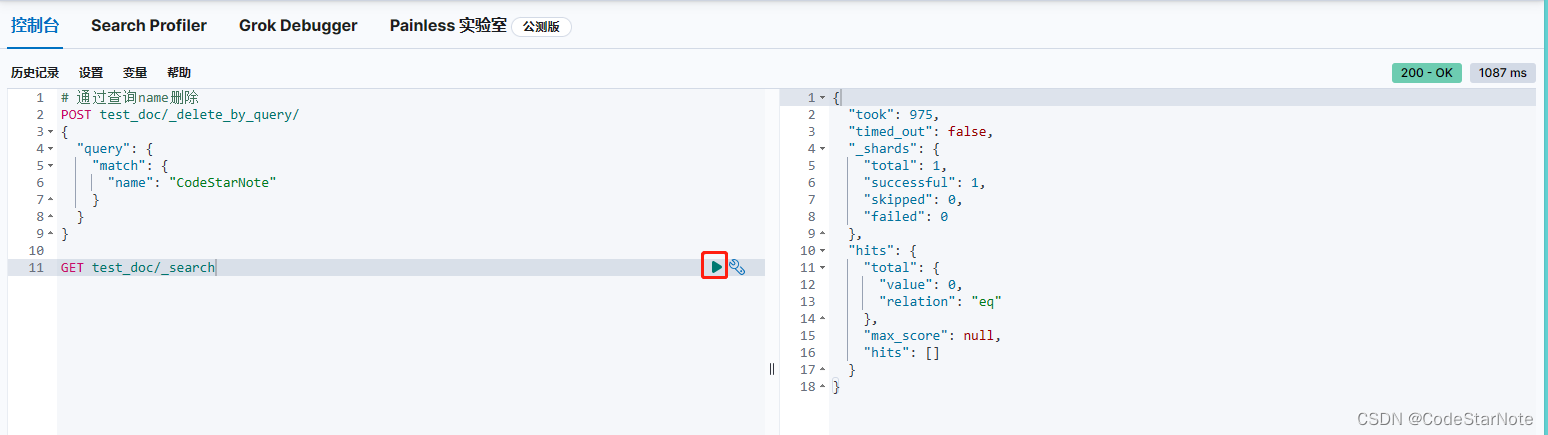
# 查询
GET test_doc/_search
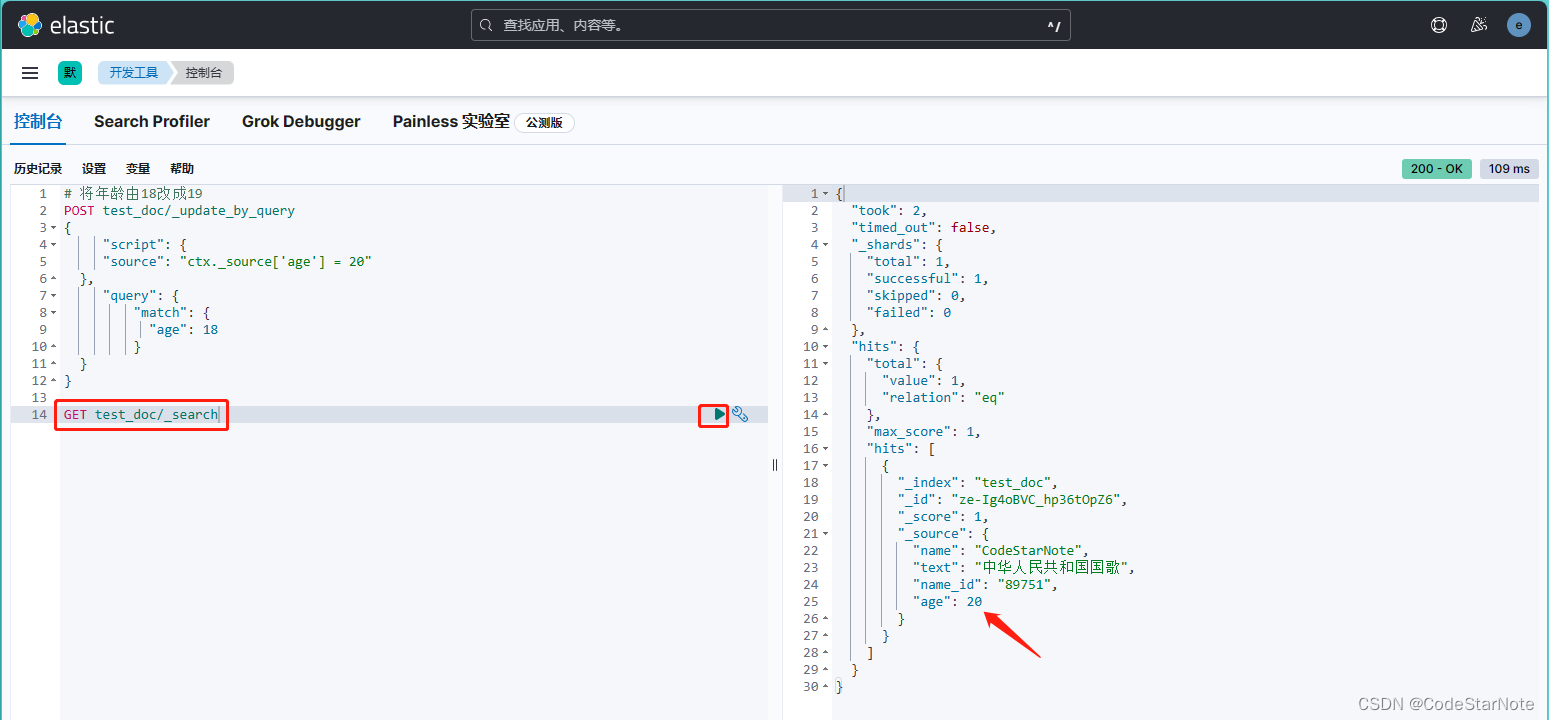
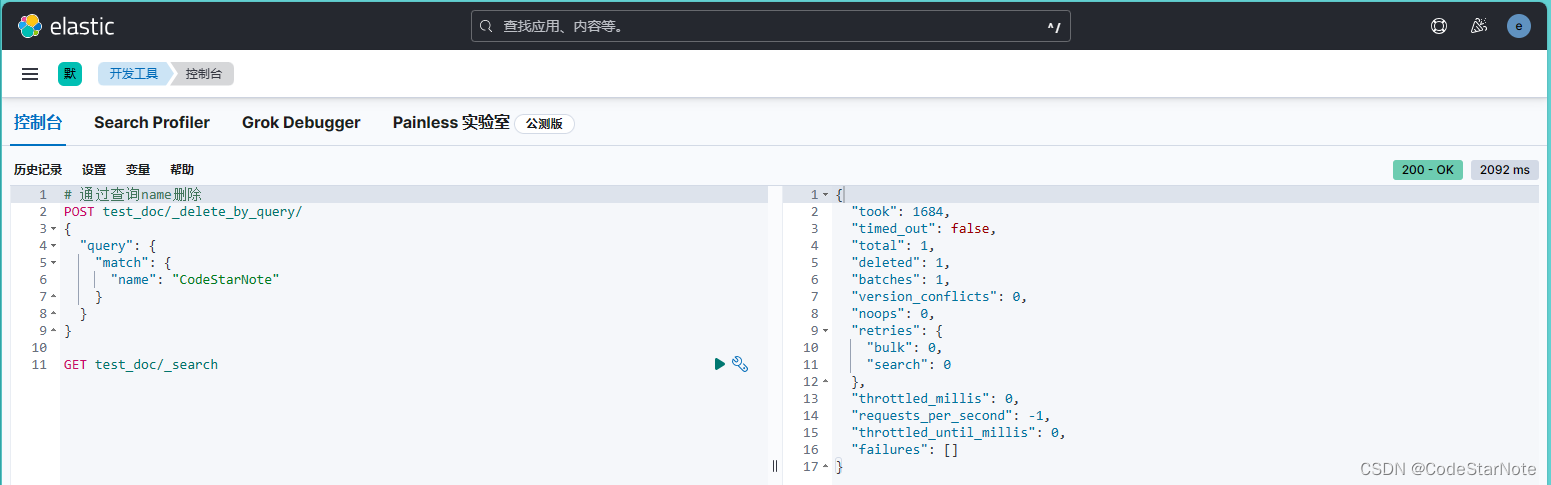
5.5 删除指定条件的数据
POST test_doc/_delete_by_query/
{
"query": {
"match": {
"name": "CodeStarNote"
}
}
}
如果是通过id删除,使用DELETE。
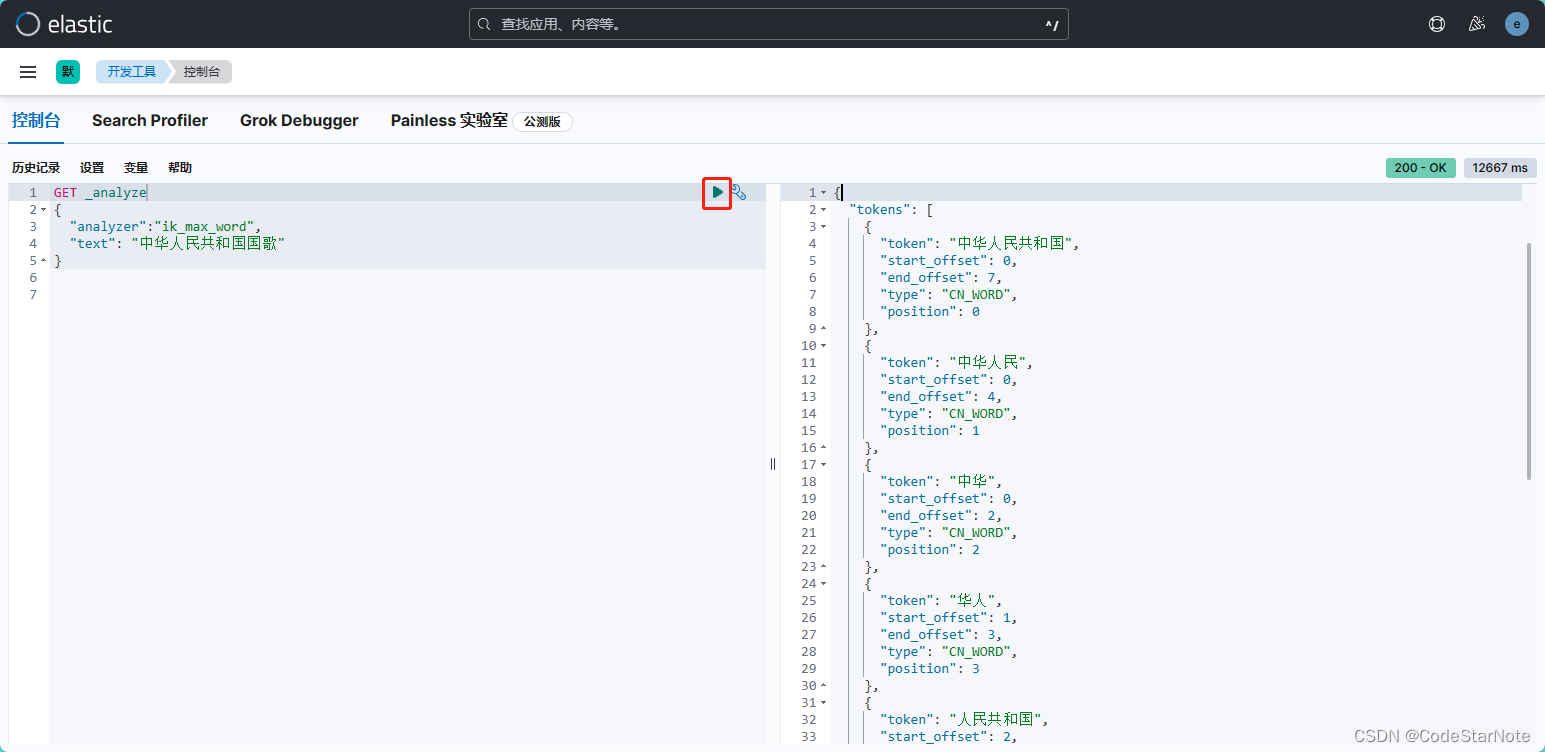
5.6 分词效果展示
ik_max_word 和 ik_smart 什么区别?
官网解释:
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
GET _analyze
{
"analyzer":"ik_max_word",
"text": "中华人民共和国国歌"
}
传送门:【部署elasticsearch集群】
传送门:【部署ik分词器】