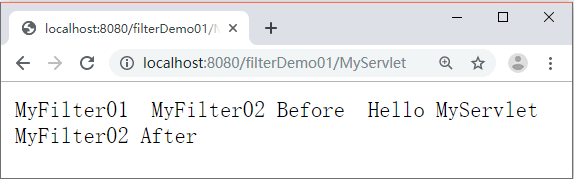
程序的翻译
程序在形成可执行程序之前都经历过一系列十分复杂的过程,也就是我们程序的翻译,程序的翻译经过以下阶段:
- 预处理(进行宏替换)
- 编译(生成汇编)
- 汇编(生成机器可识别代码)
- 连接(生成可执行文件或库文件)
就以C语言代码为例,当我们写好了一份C语言代码,第一部要进行头文件的包含,然后在主函数下咔咔一顿写,再开始翻译,也就是形成可执行程序的过程.
我们要了解翻译过程,大致是要将我们写的代码转换成汇编,然后将汇编形成二进制码,也就是计算机可以识别的代码,最后将目标二进制文件和链接库通过链接器连接生成可执行程序。
预处理阶段
预处理执行的就是:1.将文件的头文件展开 2.宏替换 3.条件编译 4.代码注释的删除
而头文件展开是干啥呢,这里就要大略的谈谈头文件和库文件了,头文件就是我们的stdio.h,而我们包含的这个头文件功能起到一些函数、变量类型定义的作用,而函数的具体实现是在库文件里的,例如我们的printf函数也是需要实现的,就是在stdio.h定义的,如果我们要使用函数的话,编译器就需要到特定的库文件中去寻找该函数的实现,而库文件的内容实质上都是一些二进制。所以回到问题,头文件展开的实质就是将stdio.h里面的内容拷贝一份放在咱们的代码里。
宏替换就比较简单,就是将#define定义的宏变量,宏函数等内容进行替换。
条件编译就是将#if #else #endif等内容的执行
代码注释删除就不解释了哈
linux下我们编译C语言代码时可以用gcc编译器,编写C++代码时可以用g++编译器,而且这些编译器还可以执行到具体某个过程终止:例如想让代码就执行完预处理过程就终止的话可以 gcc -E test.c -o test.i //其实-E是指预处理过程,而-o是预处理的文件存放在test.i的文件中
test.c代码
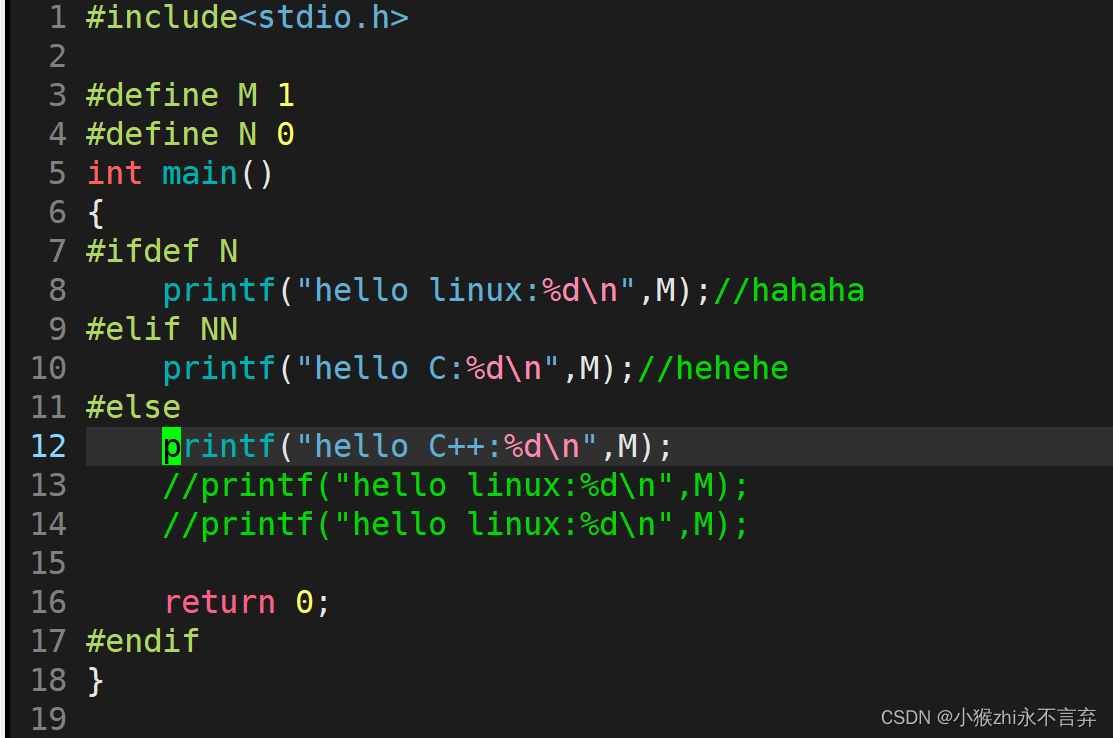
预处理之后:

其实并不仅仅只有这些,还有头文件展开的内容,由于内容过于丰富所以就未截取。
编译
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
- 编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化;
- 扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型
- 语法分析是根据语法规则,将输入的语句构建出分析树parse tree或者语法树syntax tree
- 语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的
- 目标代码优化就是执行死代码删除、函数内联、for循环的循环控制变量调度到寄存器访问、强度削弱...(而死代码的删除并不是注释删除而是移除根本执行不到的代码,或者对程序运行结果没有影响的代码 内联函数,也叫编译时期展开函数, 指的是建议编译器将内联函数体插入并取代每一处调用函数的地方,从而节省函数调用带来的成本,使用方式类似于宏,但是与宏不同的是内联函数拥有参数类型的校验,以及调试信息,而宏只是文本替换而已 for循环的循环控制变量,通常被cpu访问频繁,因此如果调度到寄存器中进行访问则不用每次从内存中取出数据,可以提高访问效率 强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令,比如 num % 128 与 num & 127 相较,则明显&127更加轻量)
上面这块内容为摘抄大佬文案,我也不太懂,看看猪肉就行了。![]()
而这一过程的指令就是:gcc -S test.i -o test.s//这里其实-S后面跟test.c也行,只不过我们刚刚已经执行了预处理过程,紧接着就是编译,所以直接对test.i操作即可。
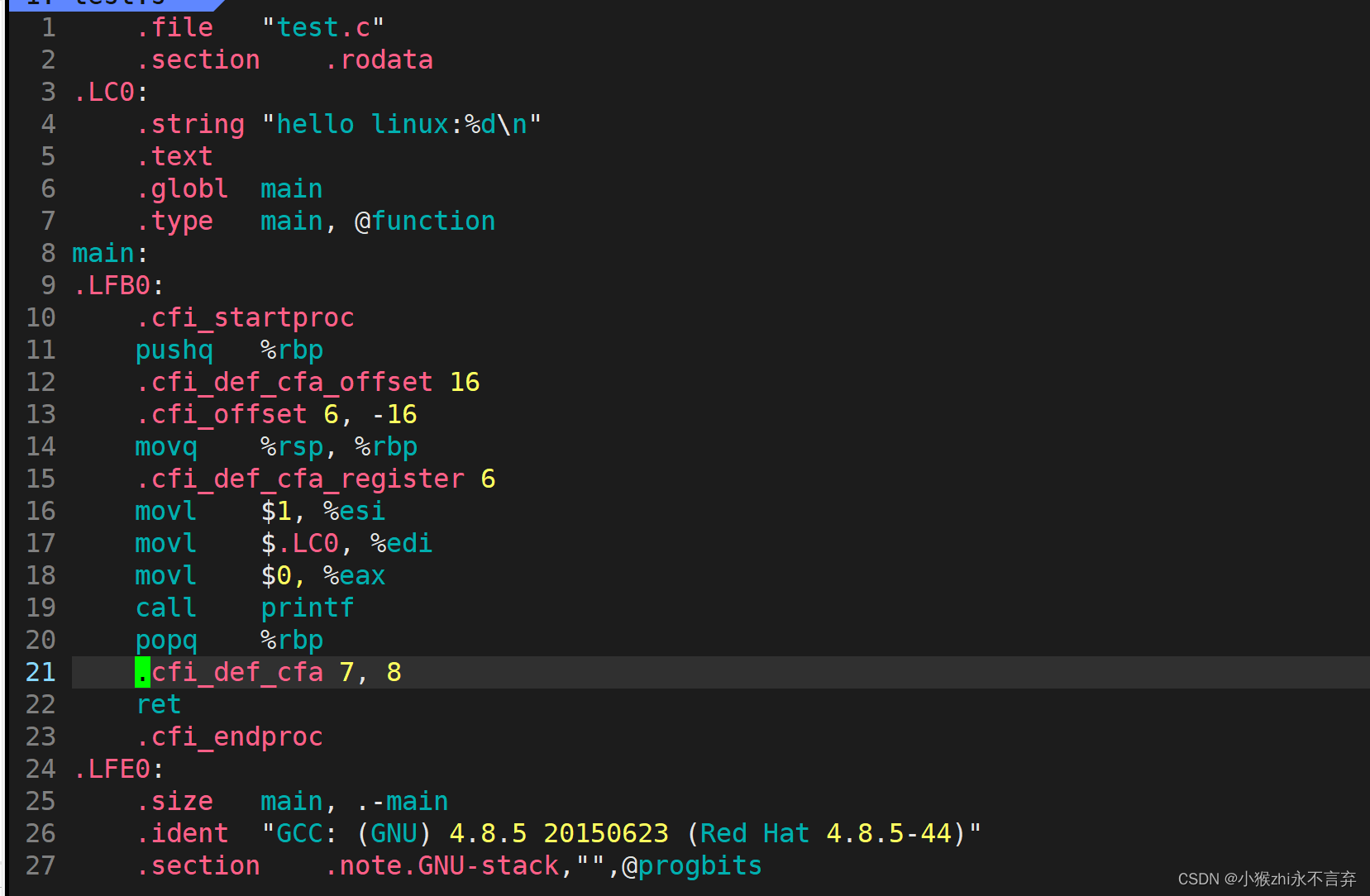
这其实就是编译的过程:形成汇编代码。
汇编
汇编就是将编译阶段形成的汇编代码转换成二进制文件,此时就可以被计算机识别。
而这一过程的指令就是:gcc -c test.s -o test.o//这里其实-c后面跟test.c也行,只不过我们刚刚已经执行了编译过程,紧接着就是汇编,所以直接对test.i操作即可。
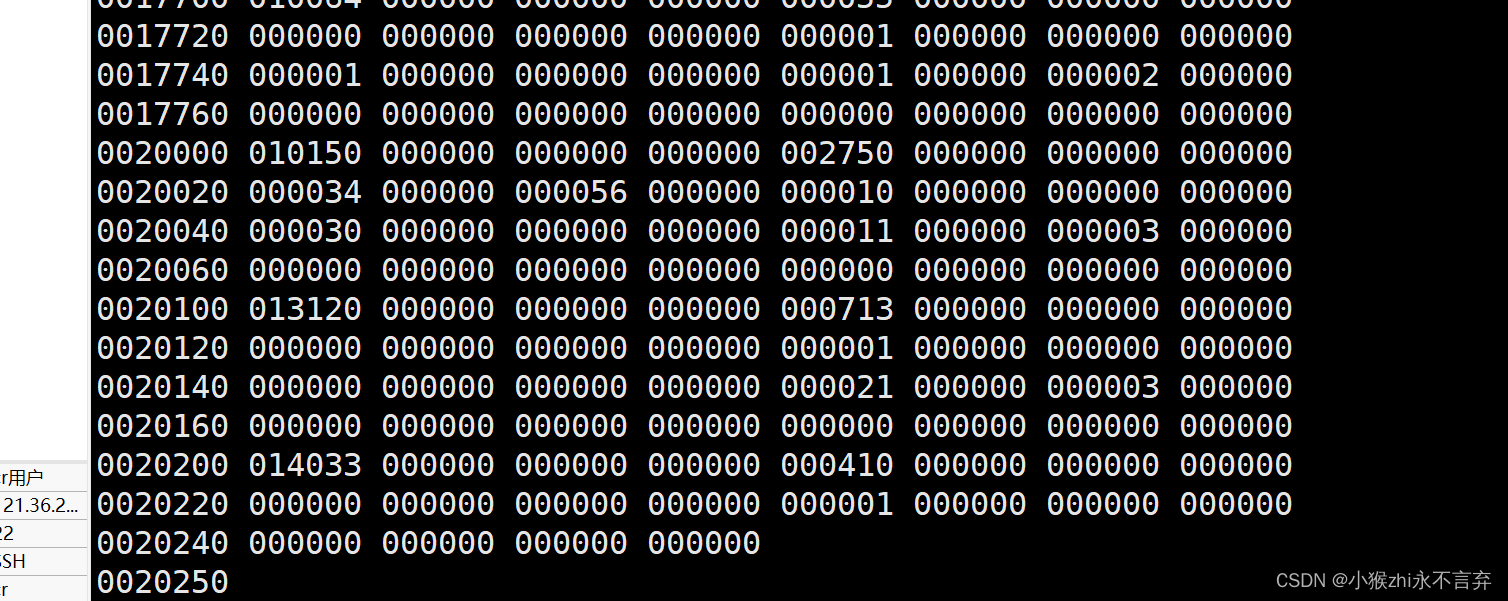
这里是部分截图,而且需要查看该二进制码的指令是od,如果一般的查看方式的话是一堆乱码。


![buu web [强网杯 2019]随便注](https://img-blog.csdnimg.cn/538b12bc39e6446b8919b0d14a9e84fd.png)





![[译] MySQL-恢复被删除的Performance Schema 数据库](https://img-blog.csdnimg.cn/img_convert/ef91a3bb41862ad3a3ac9c3396db673d.png)