1、前言
Flink API 提供了FileSink连接器,来帮助我们将数据写出到文件系统中去
版本说明:java1.8、flink1.17
官网链接:官网

2、Format Types - 指定文件格式
FileSink 支持 Row-encoded 、Bulk-encoded 两种格式写入文件系统
Row-encoded:文本格式
Bulk-encoded:Parquet、Avro、SequenceFile、Compress、Orc
Row-encoded sink: FileSink.forRowFormat(basePath, rowEncoder)
Bulk-encoded sink: FileSink.forBulkFormat(basePath, bulkWriterFactory)3、桶分配 - 文件分区策略(分目录)
桶的逻辑定义了如何将数据分配到基本输出目录内的子目录中。(好比Hive中的分区)
Flink 内置了两种同分配策略:
DateTimeBucketAssigner:默认的基于时间的分配器BasePathBucketAssigner:分配所有文件存储在基础路径上(单个全局桶)
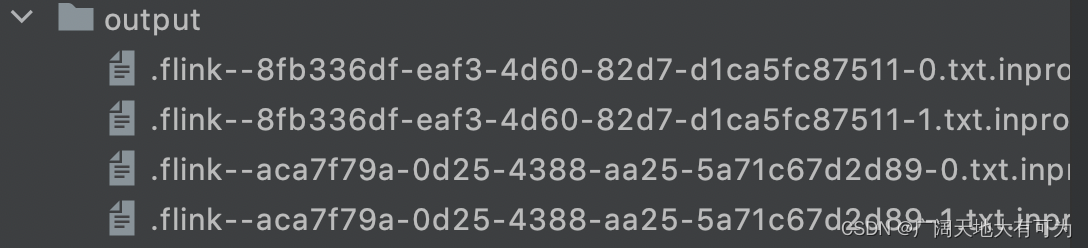
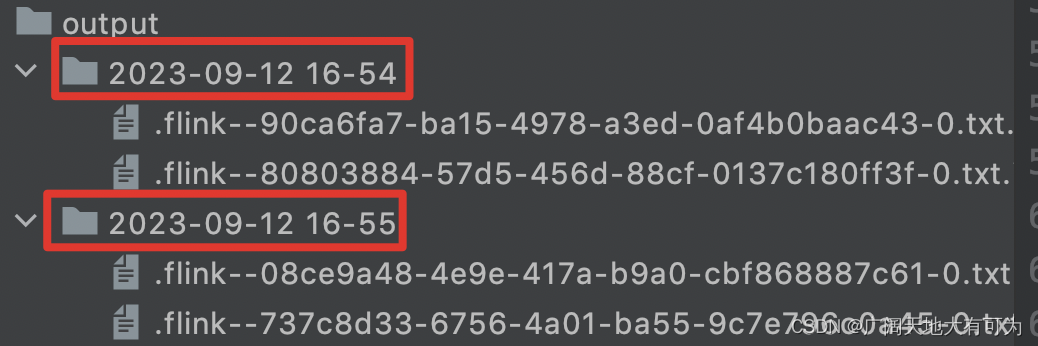
代码示例:
// TODO 按照时间进行分桶,每分钟生成一个子目录,目录名称为 yyyy-MM-dd HH-mm
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH-mm", ZoneId.systemDefault()))
// TODO 当个全局桶,不生成子目录
.withBucketAssigner(new BasePathBucketAssigner())4、滚动策略 - 分文件
滚动策略定义`何时生成新的文件`,可以指定 文件创建时间和文件大小 进行配置
// TODO 文件滚动策略: 文件创建后1分钟 或 大小超过1m 时生成新的文件
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1)) // 指定文件持续时间
.withMaxPartSize(new MemorySize(1024 * 1024)) // 指定文件大小
.build()
)5、文件命名&生命周期
Part 文件可以处于以下三种状态中的任意一种:
- In-progress :当前正在写入的 Part 文件处于 in-progress 状态
- Pending :由于指定的滚动策略)关闭 in-progress 状态文件,并且等待提交
- Finished :流模式(
STREAMING)下的成功的 Checkpoint 或者批模式(BATCH)下输入结束,文件的 Pending 状态转换为 Finished 状态
注意:在 STREAMING 模式下使用 FileSink 需要开启 Checkpoint 功能。 Finished状态的文件只在 Checkpoint 成功时生成。如果没有开启 Checkpoint 功能,文件将永远停留在 in-progress 或者 pending 的状态,并且下游系统将不能安全读取该文件数据。
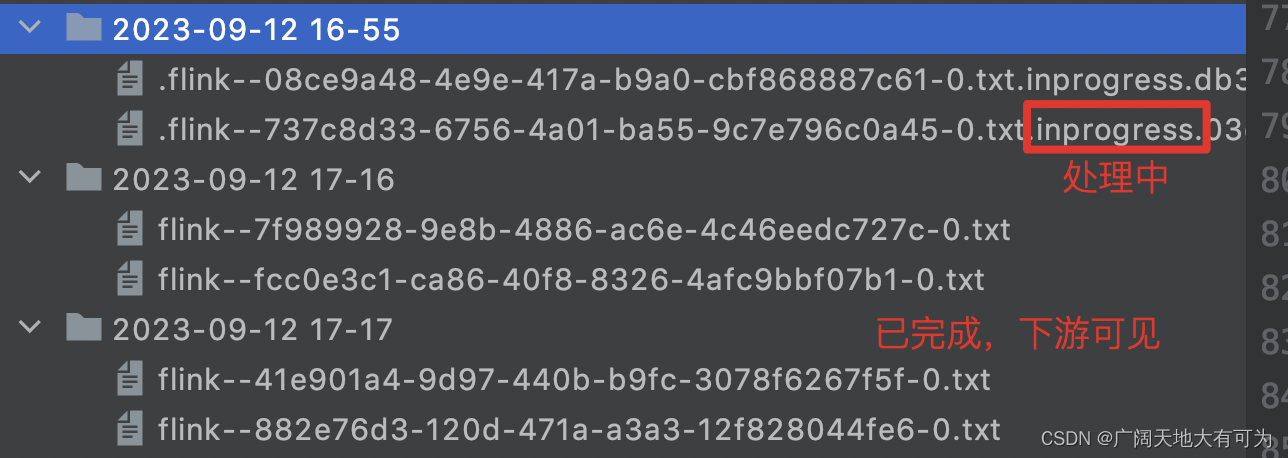
文件命名策略:
- In-progress / Pending:prefix-
part-<uid>-<partFileIndex>.ext.inprogress.uid - Finished:prefix-
part-<uid>-<partFileIndex>.ext
prefix : 文件名称前缀(默认为空)
ext :文件名称后缀(默认为空)
uid :uid 是一个分配给 Subtask 的随机 ID 值
└── 2019-08-25--12
├── prefix-4005733d-a830-4323-8291-8866de98b582-0.ext
├── prefix-4005733d-a830-4323-8291-8866de98b582-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-81fc4980-a6af-41c8-9937-9939408a734b-0.ext
└── prefix-81fc4980-a6af-41c8-9937-9939408a734b-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11代码示例:
// TODO 指定输出文件的名称配置 前缀、后缀
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("flink") // 指定前缀
.withPartSuffix("txt") // 指定后缀
.build()
)6、这是一个完整的例子
package com.baidu.datastream.sink;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
import java.time.ZoneId;
// TODO flink 数据输出到文件系统
public class SinkFiles {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// STREAMING 模式时,必须开启checkpoint,否则文件一直都是 .inprogress
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 2.指定数据源
DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);
// 3.初始化 FileSink 实例
FileSink<String> fileSink = FileSink
// TODO 指定输出方式 行式输出、文件路径、编码
.<String>forRowFormat(new Path("data/output"), new SimpleStringEncoder<String>("UTF-8"))
// TODO 指定输出文件的名称配置 前缀、后缀
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("flink") // 指定前缀
.withPartSuffix(".txt") // 指定后缀
.build()
)
// TODO 按照时间进行目录分桶:每分钟生成一个目录,目录格式为 yyyy-MM-dd HH-mm
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH-mm", ZoneId.systemDefault()))
// TODO 文件滚动策略: 1分钟 或 1m 生成新的文件
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1))
.withMaxPartSize(new MemorySize(1024 * 1024))
.build()
)
.build();
streamSource.sinkTo(fileSink);
// 3.触发程序执行
env.execute();
}
}