join基本流程
Spark将参与Join的两张表抽象为流式遍历表(streamIter)和查找表(buildIter),通常streamIter为大表,buildIter为小表,我们不用担心哪个表为streamIter,哪个表为buildIter,这个spark会根据join语句自动帮我们完成。
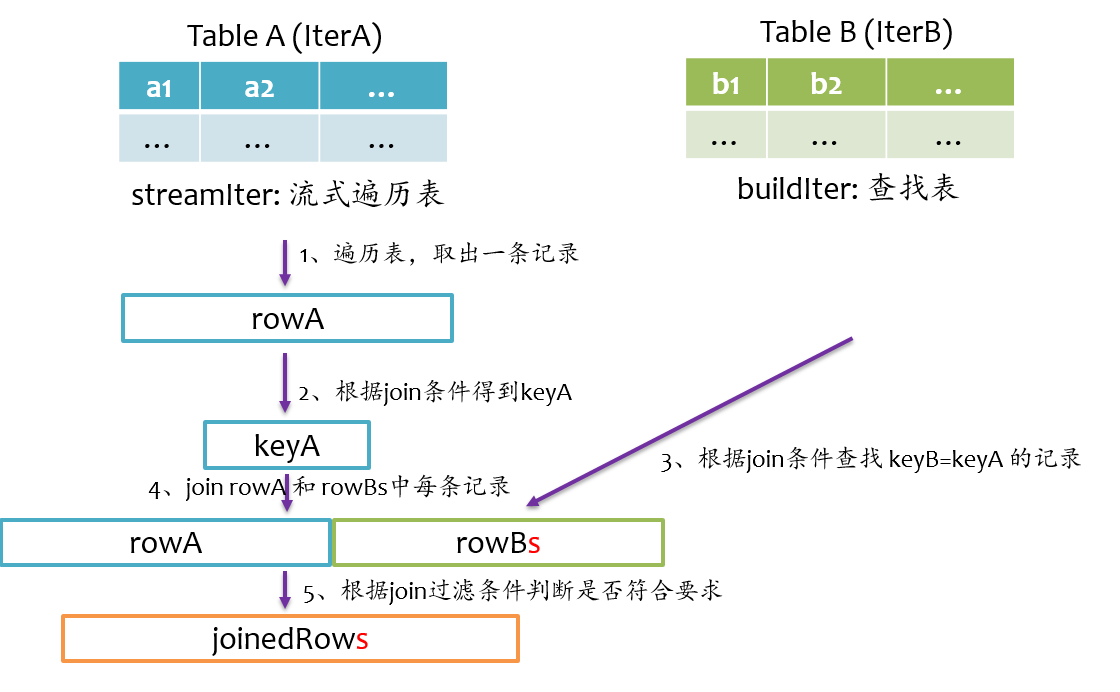
对于每条来自streamIter的记录,都要去buildIter中查找匹配的记录,所以buildIter一定要是查找性能较优的数据结构。spark提供了三种join实现:sort merge join、broadcast join以及hash join。
五种join策略
- Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join
- Cartesian Join
- Broadcast Nested Loop Join
大表join小表
Shuffle Hash Join
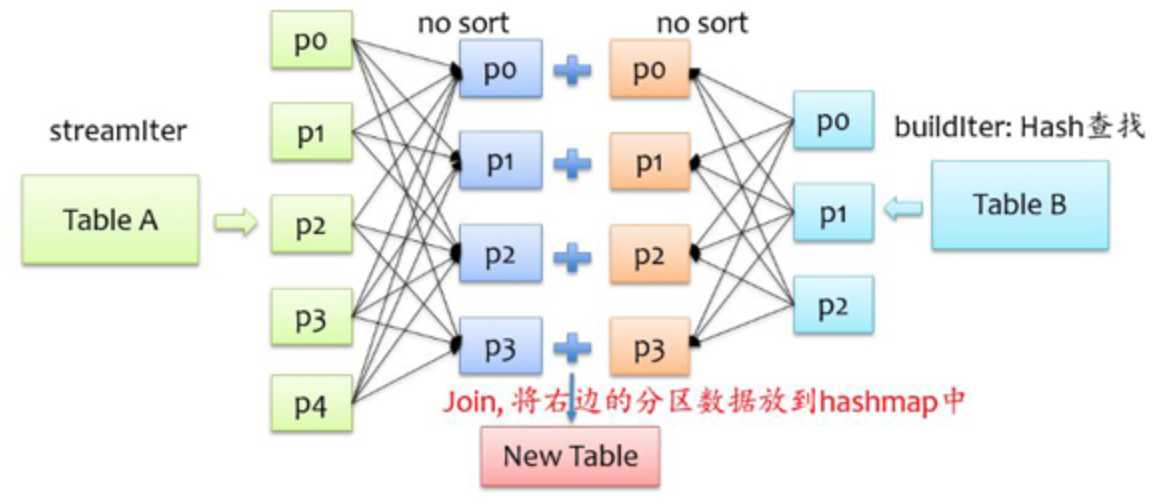
Join 步骤:把大表和小表按照相同的分区算法和分区数进行分区(Join 的 keys 进行分区),保证了 hash 值一样(相同key)的数据都分发到同一个分区中(分区内不排序),然后在同一个 Executor 中两张表 hash 值一样的分区就可以在本地进行 hash Join 。在进行 Join 之前,还会对小表的分区构建 Hash 桶(这就要求每个分区都不能太大),便于查找。
注意,和broadcast hash join的区别,这里并没有广播小表,在双方shuffle后的分区内,小表转成Hash桶与大表进行hash join。
苛刻的条件:
- buildIter总体估计大小超过spark.sql.autoBroadcastJoinThreshold设定的值,即不满足broadcast join条件
- 开启尝试使用hash join的开关,spark.sql.join.preferSortMergeJoin=false
- 每个分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold设定的值,即shuffle read阶段每个分区来自buildIter的记录要能放到内存中
- streamIter的大小是buildIter三倍以上
特点:
- 仅支持等值连接,join key不需要排序
- 支持除了全外连接(full outer joins)之外的所有join类型
- 需要对小表构建Hash map,属于内存密集型的操作,如果构建Hash表的一侧数据比较大,可能会造成OOM,不适合严重倾斜的join
- 对于FullOuter Join,需要建立双向hash表,代价太大。因此FullOuterJoin默认都是基于SortJoin来实现
Broadcast Hash Join
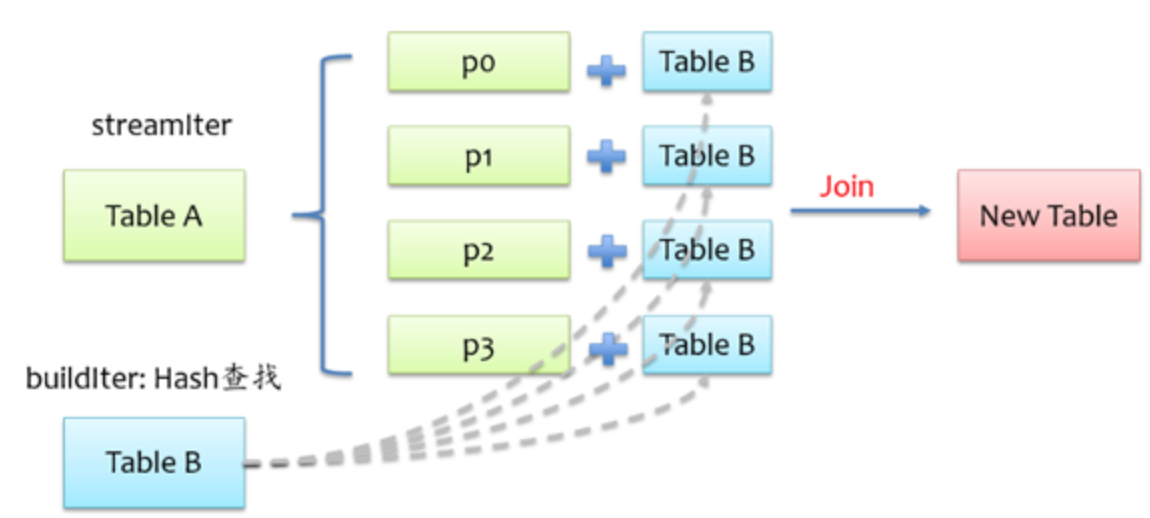
将小表的数据广播到 Spark 所有的 Executor 端,只能用于等值连接。避免了 Shuffle 操作。一般而言,Broadcast Hash Join 会比其他 Join 策略执行的要快。因为他直接在一个map中完成了,也称之为map join
Join 步骤:
- 利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端
- 在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端
- 在 Executor 端使用广播的数据与大表进行 Join 操作
使用条件:
- 必须为等值连接,不要求 Join 的 keys 可排序
- 小表大小小于
spark.sql.autoBroadcastJoinThreshold(default 10M)设定的值
Broadcast Nested Loop Join
该方式是在没有合适的JOIN机制可供选择时,最终会选择该种join策略。优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join > Broadcast Nested Loop Join.
最小的数据集被广播到另一个数据集的每个分区上,执行一个嵌套循环来执行join, 也就是说数据集1的每条记录都尝试join数据集2的每条记录(最笨的方法),效率比较低。既可以做等值join也可以做非等值join,而且是非等值join的默认策略。
没有排序,就是广播小表到每个分区上,尝试join每条记录,效率低!
大表之间join
Sort Merge Join
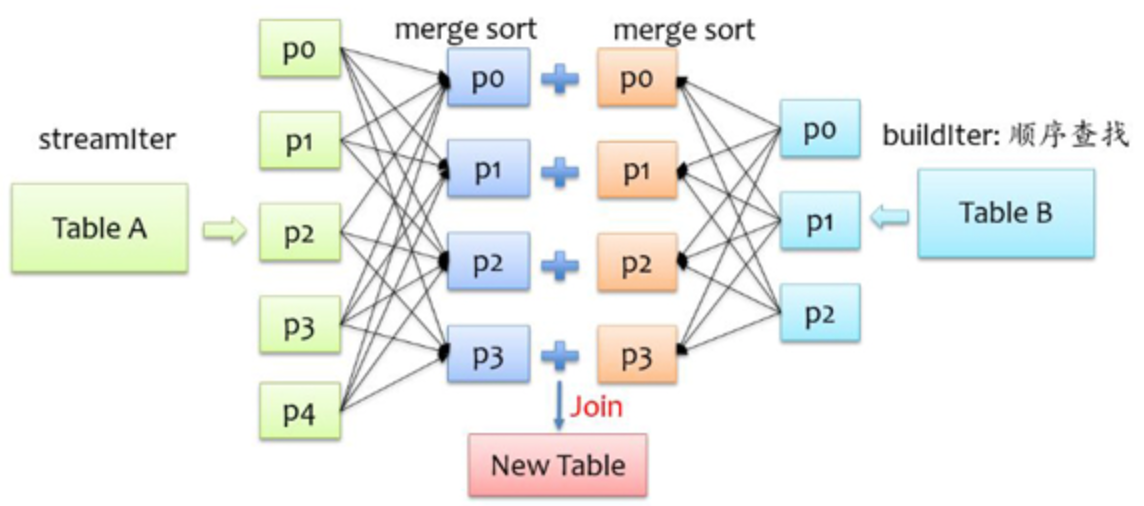
先hash到同一个分区且排好序,然后再在分区内顺序查找比对
对表的大小没有条件,不管分区多大,SortMergeJoin 都不用把一侧的数据全部加载到内存中,而是即用即丢;两个序列都有序。从头遍历,碰到 key 相同的就输出,如果不同,左边小就继续取左边,反之取右边,由于排序的特性,每次处理完一条记录后只需要从上一次结束的位置开始查找,SortMergeJoinExec执行时就能够避免大量无用的操作,提高了大数据量下sql join 的稳定性。
Join 步骤:
- shuffle: 将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区
- sort: 对每个分区内的数据进行排序
- merge: 排序后再对相应的分区内的记录进行连接
使用条件:
- 等值连接
- 参与 join 的 key 可排序
Cartesian Join
笛卡尔积
如果左表有n个分区,右表有m个分区,那么笛卡尔积后的分区数是K=n * m个;并且这K个分区中,第K(i)个分区获取的左表分区为 kn=i / m,获取的右表分区为 km=i % m,然后kn和km这两个分区做笛卡尔积;由于是以分区为单位,所以不会触发shuffle;
join策略选择
等值连接的情况
有join提示(hints)的情况,按照下面的顺序
- Broadcast Hint:如果join类型支持,则选择broadcast hash join
- Sort merge hint:如果join key是排序的,则选择 sort-merge join
- shuffle hash hint:如果join类型支持, 选择 shuffle hash join
- shuffle replicate NL hint: 如果是内连接,选择笛卡尔积方式
没有join提示(hints)的情况,则逐个对照下面的规则
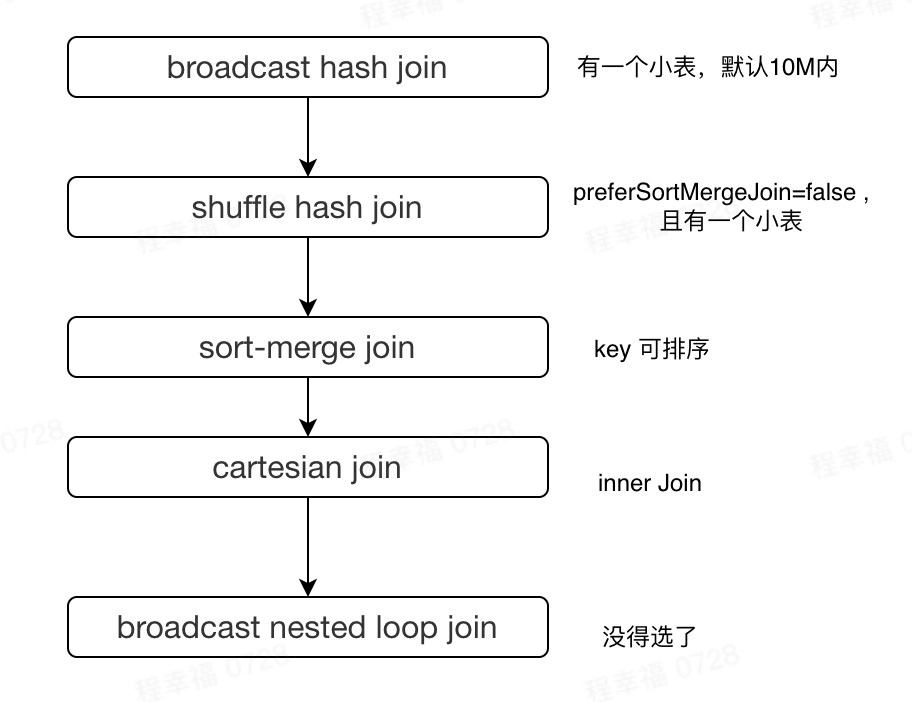
- 如果join类型支持,并且其中一张表能够被广播(spark.sql.autoBroadcastJoinThreshold值,默认是10MB),则选择 broadcast hash join
- 如果参数spark.sql.join.preferSortMergeJoin设定为false,且一张表足够小(可以构建一个hash map) ,则选择shuffle hash join
- 如果join keys 是排序的,则选择sort-merge join
- 如果是内连接,选择 cartesian join
- 没有可以选择的执行策略,则最终选择broadcast nested loop join,即使可能会发生OOM
非等值连接情况
有join提示(hints),按照下面的顺序
- broadcast hint:选择broadcast nested loop join.
- shuffle replicate NL hint: 如果是内连接,则选择cartesian product join
没有join提示(hints),则逐个对照下面的规则
- 如果一张表足够小(可以被广播),则选择 broadcast nested loop join
- 如果是内连接,则选择cartesian product join
- 如果可能会发生OOM或者没有可以选择的执行策略,则最终选择broadcast nested loop join
实验
非等值连接默认是BroadcastNestedLoopJoin
scala> spark.conf.get("spark.sql.join.preferSortMergeJoin")
res1: String = true
scala> spark.conf.get("spark.sql.autoBroadcastJoinThreshold")
res2: String = 10485760
scala> val data1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
data1: Seq[Int] = List(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
scala> val df1 = data1.toDF("id1")
df1: org.apache.spark.sql.DataFrame = [id1: int]
scala> val data2 = Seq(30, 20, 40, 50)
data2: Seq[Int] = List(30, 20, 40, 50)
scala> val df2 = data2.toDF("id2")
df2: org.apache.spark.sql.DataFrame = [id2: int]
scala> val dfJoined = df1.join(df2, $"id1" >= $"id2") //非等值连接
dfJoined: org.apache.spark.sql.DataFrame = [id1: int, id2: int]
// 注意查看执行计划是BroadcastNestedLoopJoin
scala> dfJoined.queryExecution.executedPlan
res3: org.apache.spark.sql.execution.SparkPlan =
BroadcastNestedLoopJoin BuildRight, Inner, (id1#3 >= id2#8)
:- LocalTableScan [id1#3]
+- BroadcastExchange IdentityBroadcastMode
+- LocalTableScan [id2#8]

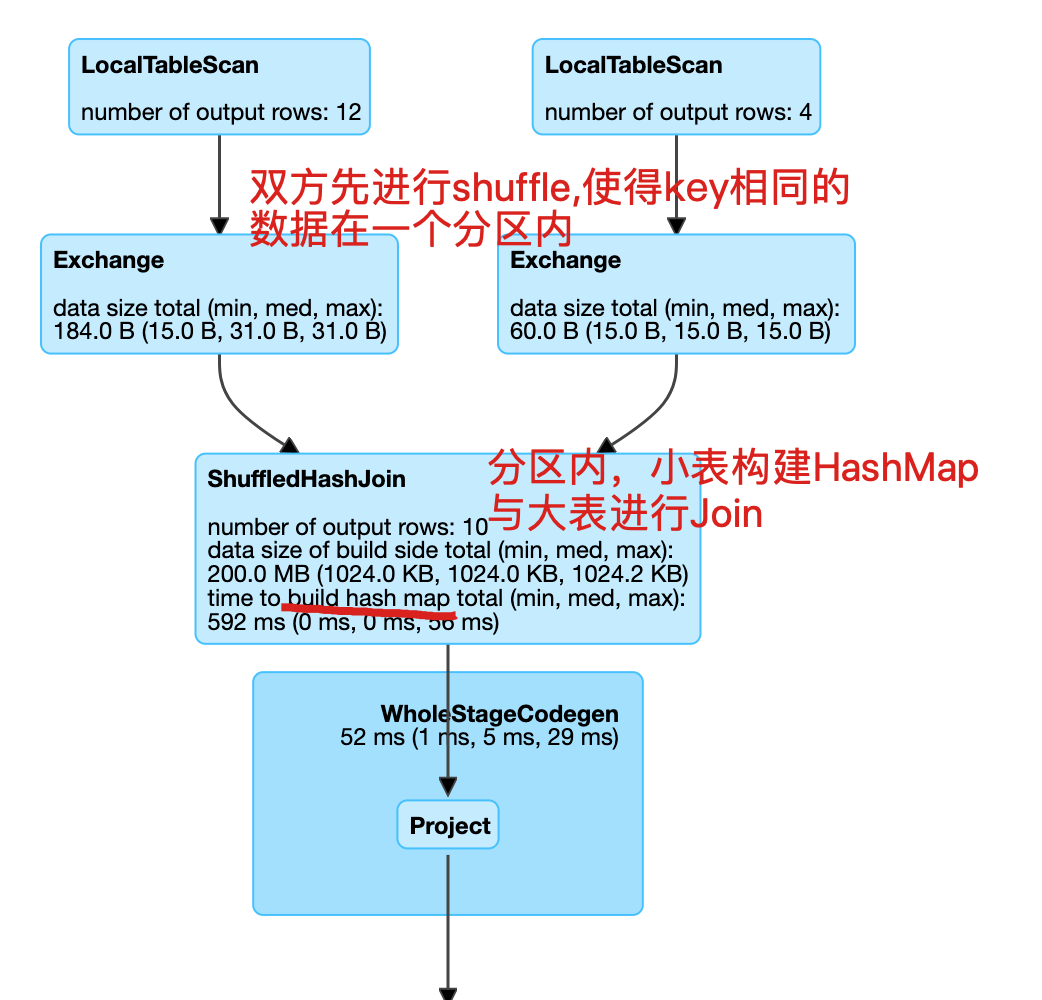
shuffle hash join
scala> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 2)
scala> spark.conf.set("spark.sql.join.preferSortMergeJoin", "false")
scala> val dfhashJoined = df1.join(df2, $"id1" === $"id2") //等值连接
dfhashJoined: org.apache.spark.sql.DataFrame = [id1: int, id2: int]
scala> dfhashJoined.queryExecution.executedPlan
res7: org.apache.spark.sql.execution.SparkPlan =
ShuffledHashJoin [id1#3], [id2#8], Inner, BuildRight
:- Exchange hashpartitioning(id1#3, 200)
: +- LocalTableScan [id1#3]
+- Exchange hashpartitioning(id2#8, 200)
+- LocalTableScan [id2#8]
sort MergeJoin
scala> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
scala> spark.conf.set("spark.sql.join.preferSortMergeJoin", "true")
scala> val sortJoined = df1.join(df2, $"id1" === $"id2")
sortJoined: org.apache.spark.sql.DataFrame = [id1: int, id2: int]
scala> sortJoined.queryExecution.executedPlan
res11: org.apache.spark.sql.execution.SparkPlan =
*(3) SortMergeJoin [id1#3], [id2#8], Inner
:- *(1) Sort [id1#3 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id1#3, 200)
: +- LocalTableScan [id1#3]
+- *(2) Sort [id2#8 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id2#8, 200)
+- LocalTableScan [id2#8]
scala> sortJoined.show

spark3 join策略提示
- Broadcast HashJoin
有三种方式
SELECT /*+ BROADCAST(t1) */ * FROM t1 INNER JOIN t2 ON t1.key = t2.key;
SELECT /*+ BROADCASTJOIN (t1) */ * FROM t1 left JOIN t2 ON t1.key = t2.key;
SELECT /*+ MAPJOIN(t2) */ * FROM t1 right JOIN t2 ON t1.key = t2.key;
- shuffle sort merge Join
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 INNER JOIN t2 ON t1.key = t2.key;
SELECT /*+ MERGEJOIN(t2) */ * FROM t1 INNER JOIN t2 ON t1.key = t2.key;
SELECT /*+ MERGE(t1) */ * FROM t1 INNER JOIN t2 ON t1.key = t2.key;
- shuffle Hash Join
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 INNER JOIN t2 ON t1.key = t2.key;