机器学习——协同过滤算法(CF)
文章目录
- 前言
- 一、基于用户的协同过滤
- 1.1. 原理
- 1.2. 算法步骤
- 1.3. 代码实现
- 二、基于物品的协同过滤
- 2.1. 原理
- 2.2. 算法步骤
- 2.3. 代码实现
- 三、比较与总结
- 四、实例解析
- 总结
前言
协同过滤算法是一种常用的推荐系统算法,它基于用户的历史行为和其他用户的行为进行推荐(即物以类聚,人以群分的意思)
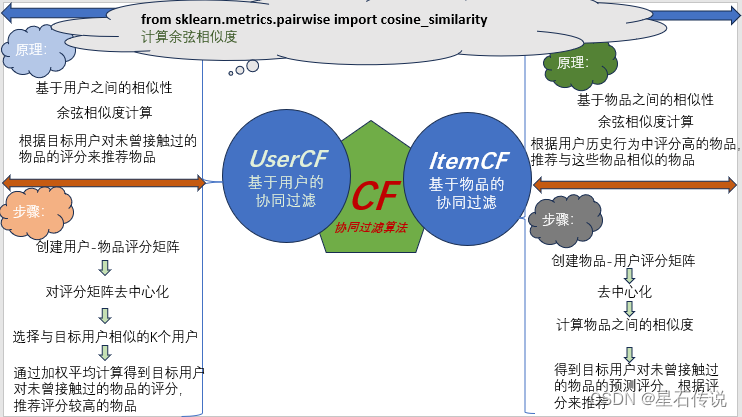
其原理主要分为两种类型:基于用户的协同过滤和基于物品的协同过滤。
本文将简单介绍一下协同过滤算法
一、基于用户的协同过滤
1.1. 原理
该算法基于用户之间的相似性来进行推荐。首先,计算用户之间的相似度,常用的相似度度量方法有余弦相似度、Pearson相关系数等。然后,根据相似度高的用户的行为(包括用户对物品的评分、点击、购买等行为),为目标用户推荐未曾接触过的物品。
1.2. 算法步骤
-
首先创建一个用户-物品评分矩阵,将用户的评分数据表示为一个矩阵,行表示用户,列表示物品
-
对数据进行去中心化处理。可以通过减去每个用户的平均评分来实现去中心化。
-
计算用户之间的相似度,可以使用余弦相似度公式计算两个用户之间的相似度:
c o s ( θ ) = ∑ i = 1 n ( x i ∗ y i ) ∑ i = 1 n ( x i ) 2 ∗ ∑ i = 1 n ( y i ) 2 cos(\theta ) = \frac{\sum_{i=1}^{n}(x_{i} * y_{i})}{\sqrt{\sum_{i=1}^{n}(x_{i})^{2}}*\sqrt{\sum_{i=1}^{n}(y_{i})^{2}}} cos(θ)=∑i=1n(xi)2∗∑i=1n(yi)2∑i=1n(xi∗yi) -
选择与目标用户最相似的k个用户
-
根据这k个用户的行为,为目标用户推荐未曾接触过的物品。可以通过加权平均计算得到目标用户对未曾接触过的物品的评分,然后按照评分进行排序,推荐评分较高的物品
1.3. 代码实现
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 假设得到了一个有缺失值的用户-物品评分矩阵(评分越高,表示此用户对该物品的喜好程度越高)
data = pd.DataFrame({
"one": [4, np.nan, 2, np.nan],
"two": [np.nan, 4, np.nan, 5],
"three": [5, np.nan, 2, np.nan],
"four": [3, 4, np.nan, 3],
"five": [5, np.nan, 1, np.nan],
"six": [np.nan, 5, np.nan, 5],
"seven": [np.nan, np.nan, np.nan, 4]
}, index=list('ABCD'))
print(data)
one two three four five six seven
A 4.0 NaN 5.0 3.0 5.0 NaN NaN
B NaN 4.0 NaN 4.0 NaN 5.0 NaN
C 2.0 NaN 2.0 NaN 1.0 NaN NaN
D NaN 5.0 NaN 3.0 NaN 5.0 4.0
# first: 寻找与A最相似的其它用户 ; second: 预测A对未接触的物品(即原来评分为NaN的物品,如two)的评分,从而做出是否推荐的判断
# !!!对缺失值的处理要适当(想象一下,如果直接将缺失值填充为0,则会引入负面评价,因为此时0并不是一个中性值,甚至可以说是一个最小的值,直接拉低了评分),所以我们要先对这个矩阵进行去中心化,再将缺失值填充为0
# 去中心化(每一个用户的每一个项目的评分减去均值) , 这样每一个用户的项目的均值就为0了,那么0就是一个中性值,不会引入负面评价
new_data = data.apply(lambda x: x - x.mean(), axis=1)
print(new_data)
one two three four five six seven
A -0.250000 NaN 0.750000 -1.250000 0.750000 NaN NaN
B NaN -0.333333 NaN -0.333333 NaN 0.666667 NaN
C 0.333333 NaN 0.333333 NaN -0.666667 NaN NaN
D NaN 0.750000 NaN -1.250000 NaN 0.750000 -0.25
#计算余弦相似度
"""
from sklearn.metrics.pairwise import cosine_similarity
sim_AB = cosine_similarity(new_data.loc["A", :].fillna(0).values.reshape(1, -1), new_data.loc["B",].fillna(0).values.reshape(1, -1))
print(sim_AB)
sim_AC = cosine_similarity(new_data.loc["A", :].fillna(0).values.reshape(1, -1), new_data.loc["C",].fillna(0).values.reshape(1, -1))
print(sim_AC)
sim_AD = cosine_similarity(new_data.loc["A", :].fillna(0).values.reshape(1, -1), new_data.loc["D",].fillna(0).values.reshape(1, -1))
print(sim_AD)
"""
#这样一个一个计算太麻烦了,可定义一个函数来循环遍历
Result = {}
def yonhu_similar(mubiao,data):
for i in range(data.shape[0]):
bijiao = data.index[i]
sim = cosine_similarity(new_data.loc[mubiao, :].fillna(0).values.reshape(1, -1), new_data.loc[bijiao,].fillna(0).values.reshape(1, -1))
result = f"sim_{mubiao}{bijiao}"
Result[result] = sim
yonhu_similar("A",data= data)
#print(Result)
#根据相似度大小排序(降序排)
sorted_Result = sorted(Result.items(),key= lambda x : x[1],reverse=True)
yonhu_sorted_Result = [i[0] for i in sorted_Result ]
print(sorted_Result)
print(yonhu_sorted_Result)
[('sim_AA', array([[1.]])), ('sim_AD', array([[0.56818182]])), ('sim_AB', array([[0.30772873]])), ('sim_AC', array([[-0.24618298]]))]
['sim_AA', 'sim_AD', 'sim_AB', 'sim_AC']
#可见用户A与用户D最相似(除自身外)
#预测A对two商品的评分,从而做出是否推荐的判断
A_two =(sim_AD*data.loc["D","two"] + sim_AB * data.loc["B",'two']) /(sim_AD + sim_AB)
print(A_two)
[[4.64867562]]
#预测A对six商品的评分,从而做出是否推荐的判断
A_six =(sim_AD*data.loc["D","six"] + sim_AB * data.loc["B",'six']) /(sim_AD + sim_AB)
print(A_six)
[[5.]]
#同理这里也可以写一个循环来遍历,然后将结果存于一个列表中
从结果可看出A用户关于未曾接触的物品two和six的评分都挺高的,也就说明可能适合向用户A推送这两件物品的信息。
(因为评分矩阵太小的缘故,结果得到评分的差异不是非常明显,但是基础的原理是差不多的,可以想象一下当物品与用户数都极多时,在这样大的数据运算下,系统基于相似用户推送给你的物品是从"千军万马“中筛选出来的评分较高的,这过滤掉了绝大多数物品)
二、基于物品的协同过滤
2.1. 原理
该算法基于物品之间的相似性来进行推荐。首先,计算物品之间的相似度,然后,根据用户历史行为中评价高的物品,为用户推荐与这些物品相似的物品。
2.2. 算法步骤
- 准备用户的历史行为数据,包括用户对物品的评分、点击、购买等行为。通常使用评分矩阵,然后去中心化
- 根据用户的历史行为数据,计算物品之间的相似度(可以根据实际,选择合适的相似度计算方法,如余弦相似度)
- 计算得到目标用户对未曾接触过的物品的预测评分
- 根据与用户历史行为中评价高的物品相似的物品,为用户推荐未曾接触过的物品。
2.3. 代码实现
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
data = pd.DataFrame({
"u1":[2,None,1,None,3],
"u2": [None,3,None,4,None],
"u3": [4,None,5,4,None],
"u4": [None,3,None,4,None],
"u5": [5,None,4,None,5]
},index= ["S1","S2","S3","S4","S5"])
print(data)
u1 u2 u3 u4 u5
S1 2.0 NaN 4.0 NaN 5.0
S2 NaN 3.0 NaN 3.0 NaN
S3 1.0 NaN 5.0 NaN 4.0
S4 NaN 4.0 4.0 4.0 NaN
S5 3.0 NaN NaN NaN 5.0
#index 为物品,columns 为用户
#目标: 预测u3 对 S5的评分:
#数据去中心化,消除用户之间的评分偏差,从而提高预测评分的准确性。
data_center = data.apply(lambda x : x- x.mean(),axis= 1)
#print(data_center)
## 计算物品S5与其它物品的相似度
sim = []
for i in range(len(data_center)):
sim_li = cosine_similarity(np.nan_to_num(data_center.iloc[-1].values).reshape(1,-1),
np.nan_to_num(data_center.iloc[i].values).reshape(1,-1)
)
sim.append(sim_li)
print(sim)
[array([[0.98198051]]), array([[0.]]), array([[0.72057669]]), array([[0.]]), array([[1.]])]
# 计算u3 对 S5的预测评分
u3_s5 = (sim[0]*data_center.loc["S1","u3"] + sim[2] * data_center.loc["S3","u3"]) / (sim[0]+sim[2])
print(u3_s5)
[[0.89764267]]
补充:
在协同过滤算法中,使用去中心化后的评分矩阵进行预测时,可以得到更准确的相似度和预测评分,从而提高推荐的准确性。
然而,去中心化操作也可能会导致一些评分变为负值,这可能需要在实际应用中进行处理。
三、比较与总结
-
目标不同:顾名思义,基于用户的协同过滤算法的目标是找到与目标用户兴趣相似的其他用户,并根据这些用户的行为来推荐物品。而基于物品的协同过滤算法的目标是找到与目标物品相似的其他物品,并根据这些物品的评分来推荐给用户。
-
在相似度计算时,基于物品的协同过滤算法要对用户-物品评分矩阵进行转置
-
推荐效果不同:前者在用户数较多时能为新用户提供更好的推荐效果,或者在物品数较多时能提供更好的效果。
四、实例解析
这是一个电影推荐实例
import pandas as pd
import numpy as np
# 读取用户数据
users = pd.read_csv(r"D:\movielens\users.dat", sep="::", header=None,
names=["user_id", "gender", "age", "occupation", "zip"], engine="python")
# 读取评分数据
ratings = pd.read_csv(r"D:\movielens\ratings.dat", sep="::", header=None,
names=["user_id", "movie_id", "rating", "timestamp"], engine="python")
# 读取电影数据
movies = pd.read_csv(r"D:\BaiduNetdiskDownload\movielens\movies.dat", sep="::", header=None,
names=["movie_id", "title", "genres"], engine="python", encoding="ISO-8859-1")
# 数据透视,得到一个评分矩阵
data = pd.pivot_table(ratings, index="user_id", columns="movie_id", values="rating")
print(data.info())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6040 entries, 1 to 6040
Columns: 3706 entries, 1 to 3952
dtypes: float64(3706)
memory usage: 170.8 MB
None
"""
# 假如为user_id 为 1 的用户推荐电影
"""
# 去中心化
new_data = data.apply(lambda x: x - x.mean(), axis=1)
# print(new_data.head())
# 计算每一个用户与user_id 为1的相似度
from sklearn.metrics.pairwise import cosine_similarity
sim_cos = []
for i in range(len(new_data)):
sim = cosine_similarity(new_data.iloc[0].fillna(0).values.reshape(1, -1),
new_data.iloc[i].fillna(0).values.reshape(1, -1))
sim_cos.append(sim)
# print(sim_cos)
sim_cos = [x[0][0] for x in sim_cos]
# print(sim_cos)
data = data.assign(sim = sim_cos)
# print(data)
data = data.sort_values(by= "sim",ascending=False)
# print(data)
data_top5 = data.iloc[1:6].copy()
print(data_top5)
movie_id 1 2 3 4 5 6 ... 3948 3949 3950 3951 3952 sim
user_id ...
1337 NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN 0.189242
379 NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN 0.159893
5404 5.0 NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN 0.155154
49 5.0 NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN 0.148455
2607 NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN 0.148105
[5 rows x 3707 columns]
print("=========================")
#将这五位用户都没看过的电影删除
data_top5.dropna(how ="all",axis = 1,inplace = True )
print(((~data_top5.iloc[:,0].isnull()).astype("int")) * data_top5.sim) #将nan值设置为0,非nan值设置为1
#预测评分
have_pre = data_top5[data_top5.columns[:-1]].apply(lambda x: ((x*data_top5.sim).sum())/(((~x.isnull()).astype("int"))*(data_top5.sim)).sum())
#print(have_pre)
haven_seen = data.columns[~data.iloc[0,:].isnull()][:-1] #得到用户1已经看过电影的ID
#print(haven_seen)
#得到用户一未看过的电影
pre_movie_id = set(have_pre.index) - set(haven_seen)
pre_movie = have_pre[have_pre.index.isin(pre_movie_id)]
#推荐前十个电影
recommend= pre_movie.sort_values(ascending= False)[:10]
#print(recommend.index)
movies_top10 = movies[movies.movie_id.isin(recommend.index)]
print(movies_top10)
movie_id title genres
911 923 Citizen Kane (1941) Drama
920 932 Affair to Remember, An (1957) Romance
1040 1054 Get on the Bus (1996) Drama
1052 1066 Shall We Dance? (1937) Comedy|Musical|Romance
1063 1079 Fish Called Wanda, A (1988) Comedy
1064 1080 Monty Python's Life of Brian (1979) Comedy
1068 1084 Bonnie and Clyde (1967) Crime|Drama
1108 1124 On Golden Pond (1981) Drama
1899 1968 Breakfast Club, The (1985) Comedy|Drama
1928 1997 Exorcist, The (1973) Horror
#看一下该用户已经看过的电影的排名前十
have_see_love = data.sort_values(by= 1,axis= 1,ascending= False).columns[:10]
have_see_love_top10 = movies[movies.movie_id.isin(have_see_love)]
print(have_see_love_top10)
movie_id ... genres
0 1 ... Animation|Children's|Comedy
47 48 ... Animation|Children's|Musical|Romance
1009 1022 ... Animation|Children's|Musical
1250 1270 ... Comedy|Sci-Fi
1768 1836 ... Drama
1892 1961 ... Drama
1959 2028 ... Action|Drama|War
2286 2355 ... Animation|Children's|Comedy
2735 2804 ... Comedy|Drama
3036 3105 ... Drama
[10 rows x 3 columns]
#可以发现推荐给用户的电影大多数是一些Drama和Comedy,这与该用户已看过的电影类型较为相似,(这个推荐系统应该是较为合理的)
总结
本文简单介绍了一下协同过滤算法:基于用户和基于物品的协同过滤算法,然后比较了一下这两个的区别,最后介绍了一个电影推荐实例解析。
故常无欲,以观其妙;常有欲,以观其徼
–2023-9-11 筑基篇