MapTR v2论文来了,本文仅介绍v2相较于v1有什么改进之处,如果想了解v1版本的论文细节,可见链接。
相较于maptr,maptr v2改进之处:
- 在分层query机制中引进解耦自注意力机制,有效降低了内存消耗;
- 在训练阶段,额外引进一对多预测分支,增加正样本数量,有效加速模型收敛;
- 在透视图(perspective view)和鸟瞰图(bev)增加密集监督,有效提升模型性能;
- 加入center-line类别,利于下游的规划控制;
- 提供更多关于模型工作的理论分析;
- 将模型框架由2D地图元素结构扩展至3D地图元素预测;
- 额外增加关于Argoverse2数据的实验结果。
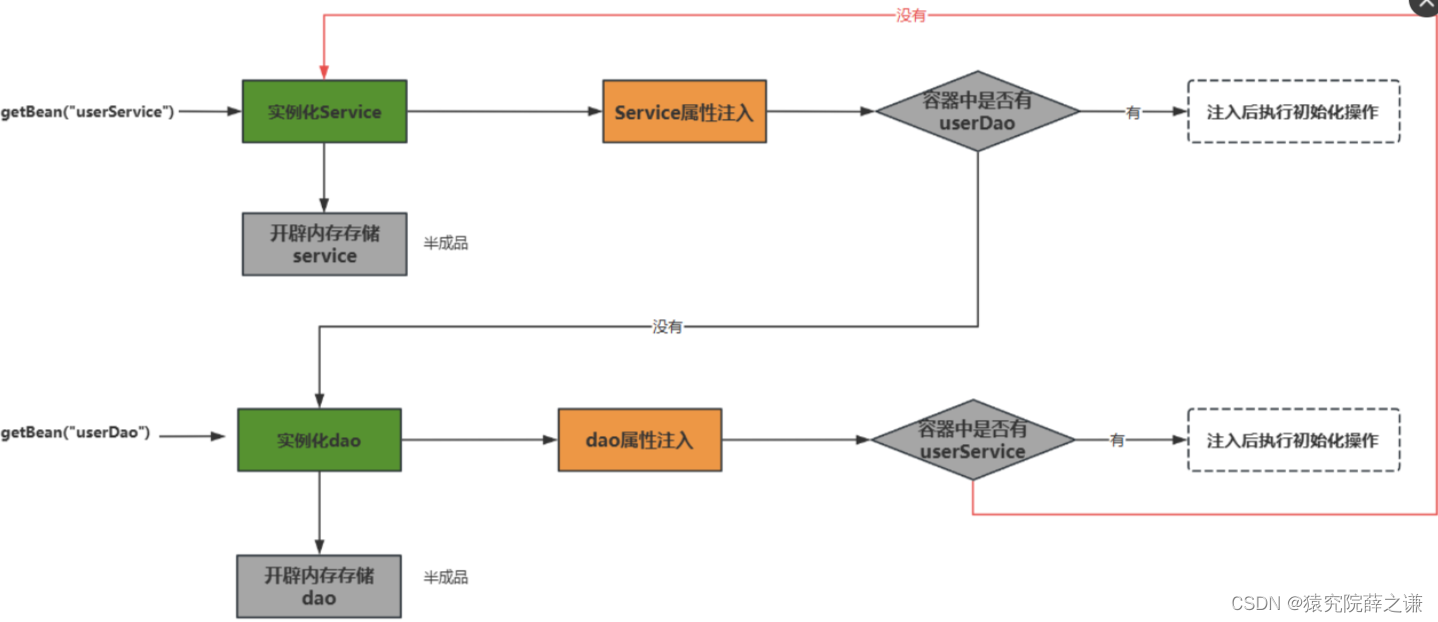
下面依据改进之处展开说一下。首先看一下v2版本的模型整体结构示意图:

Encoder
在encoder阶段,maptr v2支持多种pv转bev方法,如CVT、LSS、Defirmable Attention、GKT和IPM。为了引入深度信息,默认使用基于LSS的BEVPoolv2作为转换方式。
Decoder
在decoder阶段,作者引入新的self-Attention变体和cross-Attention变体。
self-Attention变体
maptr采用一般的自注意力机制来交换queries信息,计算复杂度为 O ( ( N + N v ) 2 ) O((N+N_v)^2) O((N+Nv)2),其中 N N N和 N v N_v Nv分别代表实例queries数量和每个queries点的数量,点的数量是固定的,但随着实例数的增加,其消耗的内存资源也是逐步增加的。在maptr v2中,作者提出使用解耦的自注意力机制代替普通的attention,具体就是分别在实例queries之间和queries内部做self-attention,具体可见上图,计算复杂度为 O ( N 2 + N v 2 ) O(N^2+N_v^2) O(N2+Nv2)。有效的降低了内存消耗,实验表明,这种方式使得模型有更高的性能。
cross-Attention变体
作者在maptr v2文章中提出三种cross-attention方式,分别是基于bev的 cross-attention、基于pv的cross-attention和两者集合的cross-attention。其中,基于bev的 cross-attention和maptr中的一样,这里不在详述;基于pv的cross-attention,得到预测的参考点集后,在特征图上采集各点周围的特征值;两者结合的cross-attention,就是将结合上述两种方式的attention方法。具体可见上图。
loss函数
一对多损失

maptr v2引入一对多损失方法,在训练时额外添加一对多的匹配分支。其中一对一损失即为maptr中定义的损失函数。一对多损失,如上图所示,将真值的地图元素复制k份,地图元素数量增加至
T
T
T,新的真值定义为
Y
′
=
{
y
i
′
}
i
=
0
T
−
1
Y'=\left\{y'_i\right\}_{i=0}^{T-1}
Y′={yi′}i=0T−1。然后同样在Y和Y使用分层的二分匹配,计算损失。对于一对多的匹配分支,一个真值地图元素可以匹配k个预测的地图元素。在训练时增加了正样本数量,使得decoder收敛更快。

辅助的密集预测损失(Dense Prediction Loss)
为了更好的利用语义和几何信息,maptr v2 引入三种辅助的损失函数:

Depth Prediction Loss

BEV Segmentation Loss

PV Segmentation Loss

总的损失函数:

Centerline
在v2,作者根据LaneGAP提出的路径规划模型,在类别中加入一种特殊的地图元素centerline,它可以提供方向信息,在规划控制里很重要。

加入centerline类别后,模型分别在nuscenes和argoverse2数据集上测试结果如上表。
结果
在nuscenes验证集上测试结果

在Argoverse2验证集上测试结果