本文作者是360奇舞团开发工程师
引言
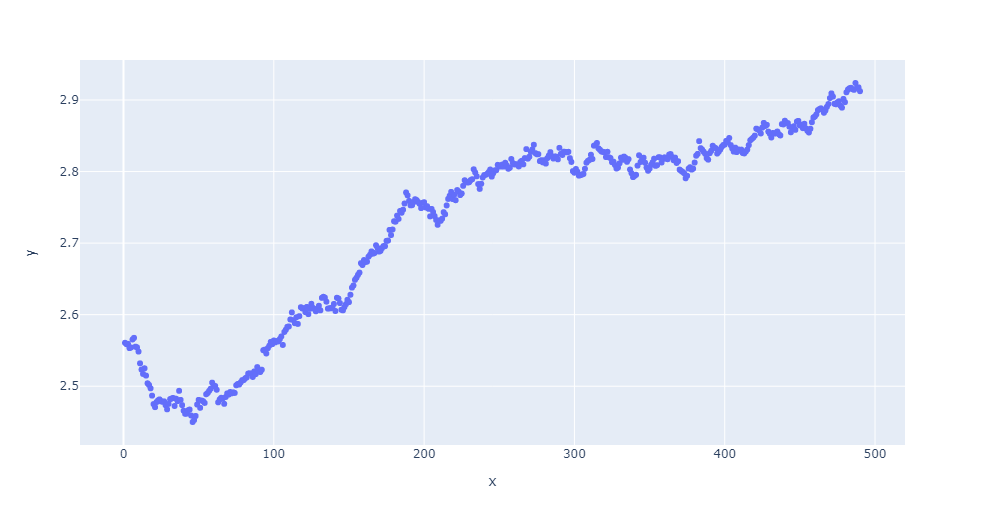
最近在做小程序换肤功能,因为不同主题色的小程序对应了不同图片库,项目内图片引用的方式又是线上URL地址配置形式,新加一套图片时,就要将图片和线上URL链接对比之后,配置到对应的Key上。这么人工操作一遍后发现费时费力。因为不同图片库间主要是颜色差异,想着能不能通过图片相似度对比以后,自动将图片匹配对应的Key。最后研究了下,通过感知哈希实现了我的需求,记录一下。
感知哈希
概念
感知哈希是使用指纹算法生成各种形式的多媒体的片段、哈希或指纹。感知哈希是一种局部敏感哈希,如果多媒体的特征相似,则它是类似的。
在图像应用中,感知图像哈希是一种根据图像的视觉外观创建图像指纹的方法。这种指纹使得比较相似的图像变得更加容易。这种算法常用于以图搜图场景,根据提供图片返回视觉上相似的图片,比如谷歌的图像搜索就基于感知哈希。
感知哈希与加密哈希
与 MD5 和 SHA1 等加密哈希函数相比,感知哈希是一个不同的概念。
对于加密哈希,哈希值是随机的。用于生成哈希的数据就像随机种子一样,因此相同的数据将生成相同的结果,但不同的数据将产生截然不同的结果。相反,感知哈希可以进行比较——得到两个数据集之间的相似性。
比较两个 SHA1 哈希值实际上只能得到两个结论。如果哈希值不同,则数据不同。如果哈希值相同,则数据可能相同。(由于存在哈希冲突的可能性,因此具有相同的哈希值并不能保证相同的数据)。
基于此特性,MD5和SHA1可以用来计算文件的哈希值,再进行对比,来判断是否是重复文件。但是对于图片相似度场景来说,对数据相同判定如此严苛的对比算法就不太适用。因为,对于图片来说,图像格式、元数据等等信息的修改,都会导致像素内容完全相同的情况下却有不同的二进制内容,从而导致哈希截然不同。
除此之外,图片的分辨率、亮度、色度、对比度、模糊度、缩放、旋转、截取、小幅度修改等操作导致的相似图片,使用加密哈希的方式对比,会得到完全不同结果。因此,图片相似度需要的不是简单粗暴的对比文件的二进制内容,而是图片上像素的色彩分布方式。在感知哈希计算相似性的场景下,大致可以理解为,图像颜色直方图中最右侧的白色色阶和最左侧的黑色色阶在图片中的分布情况。
汉明距离
通过感知哈希可以为图片生成一个指纹字符串,通过比较字符串的距离(通常采用汉明距离,Hamming distance)这个距离越小,代表两个图片越相似,一般的,我们有以下规则:
:::tips
Hamming distance = 0 -> particular like
Hamming distance < 5 -> very like
hamming distance > 10 -> different picture
:::
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字符串对应位置的不同字符的数量。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
101100 与 111000 之间的汉明距离是 2。
21438 与 22337 之间的汉明距离是 3。
"toned" 与 "roses" 之间的汉明距离是 3。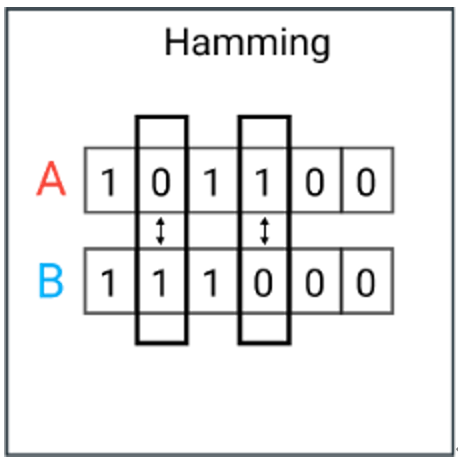
实现过程
感知哈希算法是一类算法的总称,根据色彩分布方式的计算方式不同,常用的感知哈希算法,包括aHash、pHash、dHash。
实现的过程可以简化为:简化图片-获取像素值-计算图像哈希。不同的哈希算法都有相同的基本特性:对于图像的放大或缩小、不同纵横比,较小颜色差异(对比度、亮度、模糊、饱和度等)仍然会匹配为相似图像
平均哈希算法(aHash):
该算法是基于比较灰度图每个像素与平均值来实现。
海湾大桥夜景 – 照片来源:DH Parks ( CC )
下面展示用python计算平均哈希的过程:
第一步是使用PIL或Pillow减小图像的大小和颜色。这样做是为了降低图像的复杂性,从而使比较更加准确。
image = image.resize((8, 8), Image.ANTIALIAS) # Reduce it's size.
image = image.convert("L") # Convert it to grayscale.
接下来我们求图像的平均像素值:
pixels = list(image.getdata())
avg = sum(pixels) / len(pixels)pixels只是一个像素值列表,范围从 0(黑色)到 255(白色),我们只需将它们相加并除以数量即可得到平均值。对于该图像,平均像素值为 61(大约 25% 灰度)。
现在我们可以计算哈希值了。这是通过将图像中的每个像素与平均像素值进行比较来完成的。如果像素值小于平均值,则为 0;如果大于平均值,则为 1。然后我们将其视为一串位并将其转换为十六进制。
bits = "".join(map(lambda pixel: '1' if pixel < avg else '0', pixels)) # '00010100...'
hexadecimal = int(bits, 2).__format__('016x').upper()
转换为黑白图像的位。
这就可以得到一个哈希值 00010E3CE08FFFFE,可用于将该图像的“结构”(looks)与使用相同方式哈希的任何其他图像进行汉明距离比较。距离越接近 0,图像越相似,0 表示基本相同。
感知哈希算法(pHash):
pHash算法即感知哈希算法,原理是通过离散余弦变换(DCT)降低图片频率,在图像频率中,高频代表细节,低频代表结构。通过有损压缩的方式保留大部分图像特征,再对特征值进行比较,即忽略高频保留低频。
DCT:DCT全称为Discrete Cosine Transform,即离散余弦变换。其原则与傅里叶变换相近,都是把目标信号从复杂的时域信号,分解为不同频率强度的频域信号。由傅里叶的原理可知,复杂信号是简单信号的叠加,所以DCT的基本原理就是,通过多个不同强度不同频率的DCT基信号,即可叠加“拼装”为原本的信号,因此实际记录的时候就不再需要记录复杂的原始信号,而是记录DCT的基即可。并且信号转为DCT的频域信号后,左上角表达了其低频信号强度,右下角表达了其高频信号强度,使得信号的频率分量和强度一目了然,没有原始信号的纷繁复杂。
DCT矩阵中从左上角到右下角代表越来越高频率的系数,但是除左上角外,其他部分的系数都为0左右,pHash算法在简化图片时常常将图片缩小为3232,因此只选取DCT矩阵中左上角88的部分即可得到图像的大部分特征。
再将88的部分矩阵的每个值与均值比较,组合得到的同样是一个64位的0/1哈希序列,最终再通过同位对比得到相似度大小。
pHash算法优点是更为稳定,判断效果好,但速度略慢
差异哈希算法(dHash):
dHash算法即差异哈希算法,原理是比较每行相邻元素的大小,如果左边的像素比右边的像素更亮则标记为1,否则为0,最后组合得到哈希序列。
这种算法在简化图片时常常将图片缩小为98,每行9个元素相邻比较可得到8个值,一共8行,结果也是一个64位的0/1哈希序列。
两张图片的哈希序列同样通过同位对比即可得到相似度大小。
dHash算法的优点是速度快,同时判断效果要好于aHash。
上面的三种hash算法可以用opencv实现,网上有很多代码实现,这里就不贴了。也可以直接使用python中的三方库imagehash,都有封装实现,使用也很简单。
总结
图像相似度对比有很多场景,了解感知哈希算法对比图片相似度的原理,才能搞清楚它适用于哪一种。感知哈希提供了一种简单方法,对于图片轻微调色、缩放、甚至有较小细节差异等场景,在多数情况下都有较高的识别率。而像裁剪、旋转、添加局部矫正(边框、水印)这种影响了图像色彩分布结构的场景就会有比较高的识别错误率。
没有完全百分之百正确率的相似度图像算法,因为图像相似度差异可以是千差万别,相似度又是个相对概念,即使是人也会有判断错误的时候。所以,只要根据自己实际的使用场景,采用其它一些辅助识别的算法做兼容,满足自己的需求即可。
参考链接
https://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html
https://web.archive.org/web/20171112054354/https://www.safaribooksonline.com/blog/2013/11/26/image-hashing-with-python/
https://blog.csdn.net/cjzjolly/article/details/123524616
https://zhuanlan.zhihu.com/p/68215900
https://www.yumefx.com/?p=3163
- END -
关于奇舞团
奇舞团是 360 集团最大的大前端团队,代表集团参与 W3C 和 ECMA 会员(TC39)工作。奇舞团非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。