1.创建数据源
在前几篇博客中,都是手动创建少量数据充当数据源,这次通过随机生成,让数据量多一些
# 导入所有需要的库
import pandas as pd
import numpy.random as np
import openpyxl
import xlrd
import matplotlib.pyplot as plt
#创建一些测试数据用来分析
# 设置种子
np.seed(111)
# 生成测试数据的函数
def CreateDataSet(Number=1):
Output = []
for i in range(Number):
# 创建一个按周计算的日期范围(每周一起始)
rng = pd.date_range(start='1/1/2019', end='12/31/2022',freq='W-MON') #freq表示日期的频率
# 创建一些随机数
data = np.randint(low=25, high=1000, size=len(rng))
# 状态池
status = [1, 2, 3]
# 创建一个随机的状态列表
random_status = [status[np.randint(low=0, high=len(status))] for i in range(len(rng))]
# 城市的列表
states = ['BJ','bj','SH','SHANGHAI','SZ','TJ','CQ','GZ']
# 创建一个城市的随机列表
random_states = [states[np.randint(low=0, high=len(states))] for i in range(len(rng))]
Output.extend(zip(random_states, random_status, data, rng))
return Output
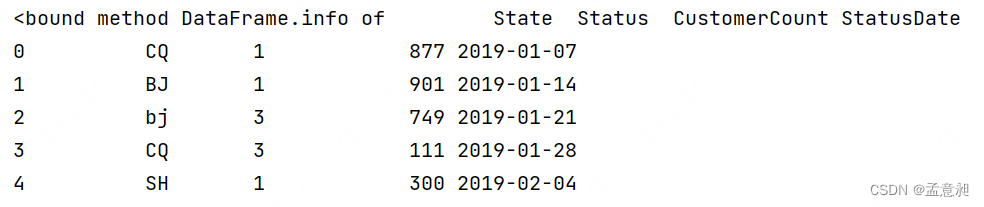
dataset = CreateDataSet(4)
print(dataset)
df = pd.DataFrame(data=dataset, columns=['State','Status','CustomerCount','StatusDate'])
print(df.info)

2.保存至excel
如果不指定保存的文件路径,就会默认保存到当前路径下
# 结果保存到 Excel 中。 需要 openpyxl 包
df.to_excel('Lesson3.xlsx', index=False) #不保存索引,但是保存列名(column header)
3.读取excel
不仅可以将DataFrame对象保存为excel,也可以将excel文件以DataFrame对象形式读取出来
# 文件的位置
Location = r'./Lesson3.xlsx'
# 读取第一个页签(sheet),并指定索引列是 StatusDate
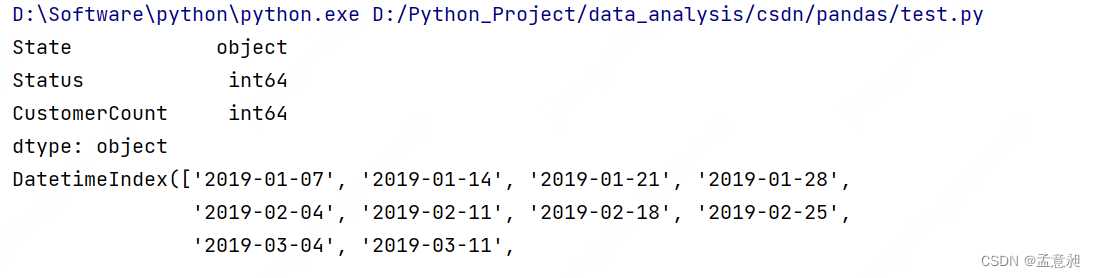
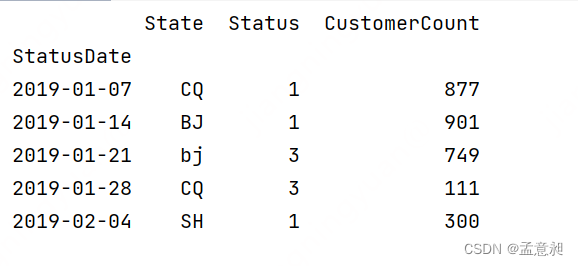
df = pd.read_excel(Location, sheet_name=0, index_col='StatusDate') # 需要 xlrd 包
print(df.dtypes)
print(df.index)
print(df.head())
4.数据清洗
当我们获取了df这份数据之后,我们可以按指定规则对其进行清洗,随便举几个例子
- 确保 state 列都是大写
- 只选择 Status = 1 的那些记录
- 对 State 列中的 SHANGHAI 和 SH,都合并为 SH
4.1 确保 state 列都是大写
可以先查看一下当前数据里State列是否都是大写
# 快速看一下 State 列中的大小写情况
print(df['State'].unique())

根据返回的结果,可以发现存在部分小写的数据,这时候就可以进行处理
# 清洗 State 列,全部转换为大写
df['State'] = df.State.apply(lambda x: x.upper())
print(df['State'].unique())

这时候就会发现都已经变成了大写的数据
4.2 只选择 Status = 1 的那些记录
观察数据可以发现Status的值有多种,我们可以对其进行筛选,只选择为1的内容
# 只保留 Status == 1
mask = df['Status'] == 1
df = df[mask]
print(df['Status'].unique())

4.3 对 State 列中的 SHANGHAI 和 SH,都合并为 SH
因为在设定中,SHANGHAI和SH为同一座城市,所以可以将二者进行统一
# 将 SHANGHAI 转换为 SH
mask = df.State == 'SHANGHAI' #找出 State 列是 SHANGHAI 的所有记录
df['State'][mask] = 'SH' # 对 State 列是 SHANGHAI 的所有记录,将其替换为 SH
print(df['State'].unique())

5.数据可视化
在经历了数据清洗,现在就可以将数据进行可视化展示
plt.figure(figsize=(15, 5))
plt.plot(df['StatusDate'], df['CustomerCount'])
plt.show()

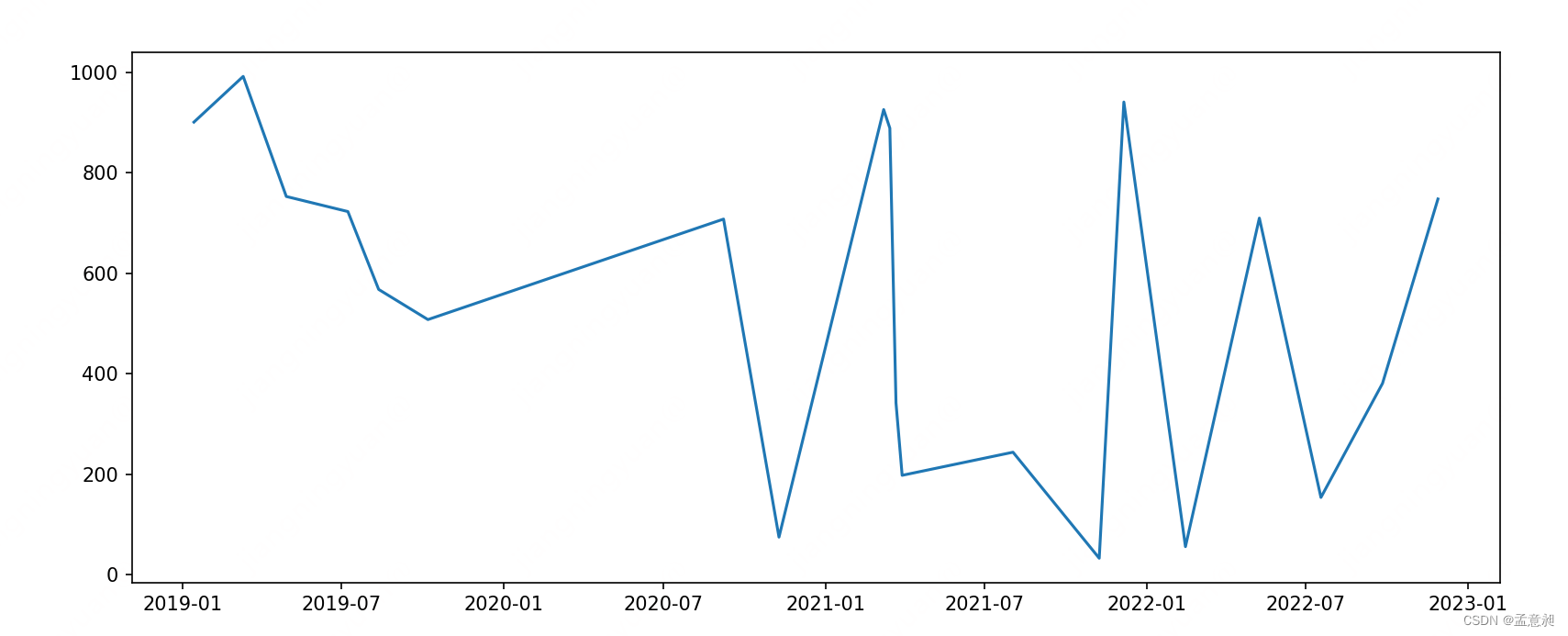
但因为这份数据涉及多个城市,所以可以单独只展示一座城市的数据
#只展示 BJ 数据
sortdf = df[df['State']=='BJ'].sort_index(axis=0)
plt.plot(sortdf['StatusDate'], sortdf['CustomerCount'])
plt.show()
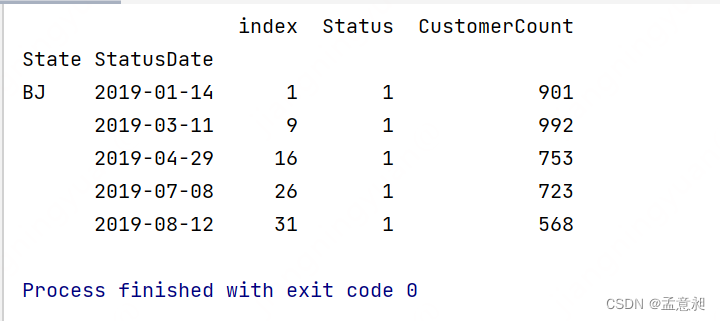
这份数据不仅包含多个城市,还涉及多个时间段,所以可以先按State和StatusDate求和进行数据展示
# 先 reset_index,然后按照 State 和 StatusDate 来做分组 (groupby)
Daily = df.reset_index().groupby(['State','StatusDate']).sum()
print(Daily.head())
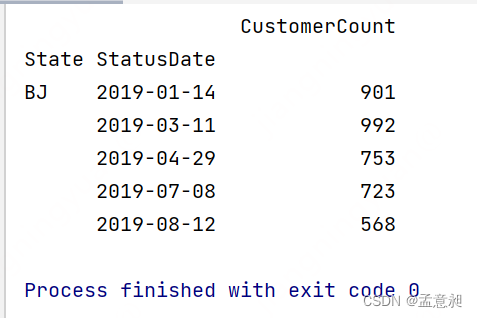
因为index和Status字段在这份数据里并不重要,所以可以对其进行删除
#去掉 Status 和 index
del Daily['index']
del Daily['Status']
print(Daily.head())
此时如果想要展示汇总之后的数据,则需要注意一点,
State和StatusDate现在是索引列,不是常规列,所以没有办法直接当作图表的x轴,不然会报错
#绘制求和后的折线图
Daily.plot(x='StatusDate',y='CustomerCount')
plt.show()
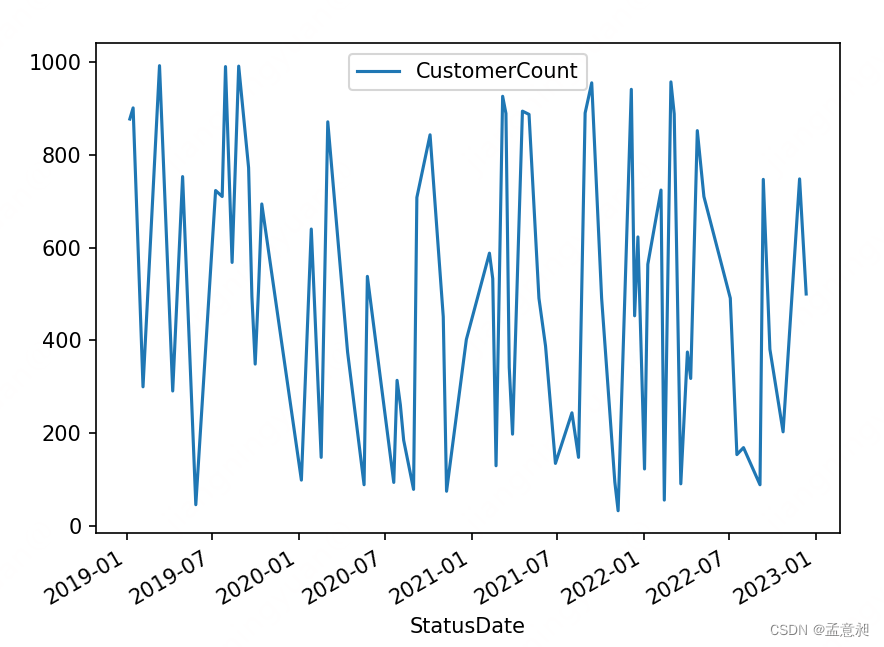
解决方式也很简单,去除索引列就可以了
#绘制求和后的折线图 这里需要先去除索引,不然无法获取 StatusDate 列
Daily.reset_index().plot(x='StatusDate',y='CustomerCount')
plt.show()
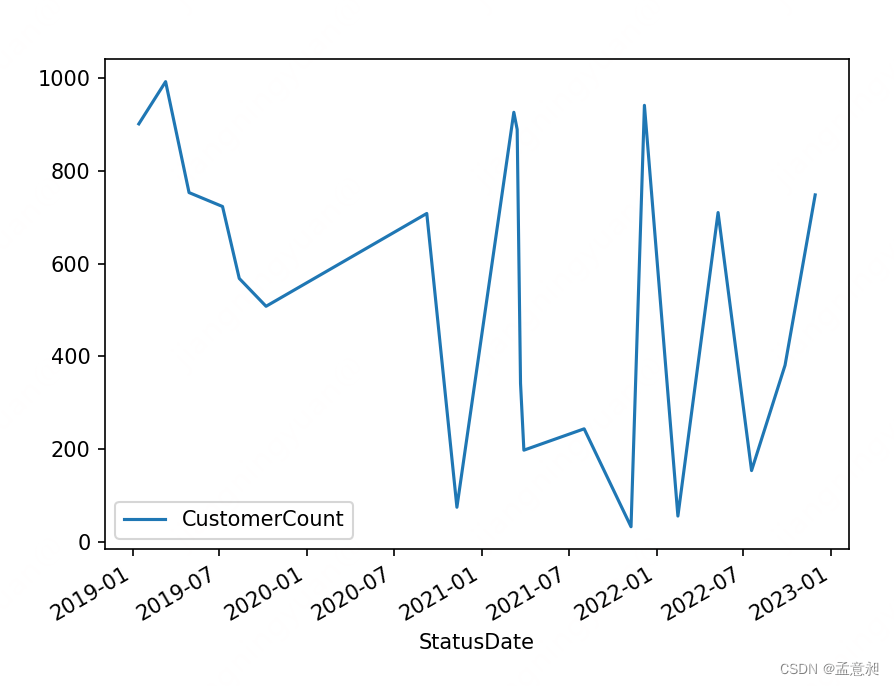
与上面类似,这里也可以指定城市进行数据展示
#绘制 指定城市 BJ 的 折线图 这里需要先去除索引,不然无法获取 StatusDate 列
Daily.loc['BJ'].reset_index().plot(x='StatusDate',y='CustomerCount')
plt.show()







![[附源码]Nodejs计算机毕业设计基于疫情防控的超市管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/e80eaa415fdd4d37ba2d52b8ae9a7af7.png)