R语言
R语言学习笔记——高级篇:第十四章-主成分分析和因子分析
文章目录
- R语言
- 前言
- 一、R中的主成分和因子分析
- 二、主成分分析
- 2.1、判断主成分的个数
- 2.2、提取主成分
- 2.3、主成分旋转
- 2.4、获取主成分得分
- 三、探索性因子分析
- 3.1、判断需提取的公共因子数
- 3.2、提取公共因子
- 3.3、因子旋转
- 3.4、因子得分
- 3.5、其他于EFA相关的包
前言
数据降维看主成分分析PCA,社会科学的理论研究看探索性因子分析法EFA
一、R中的主成分和因子分析
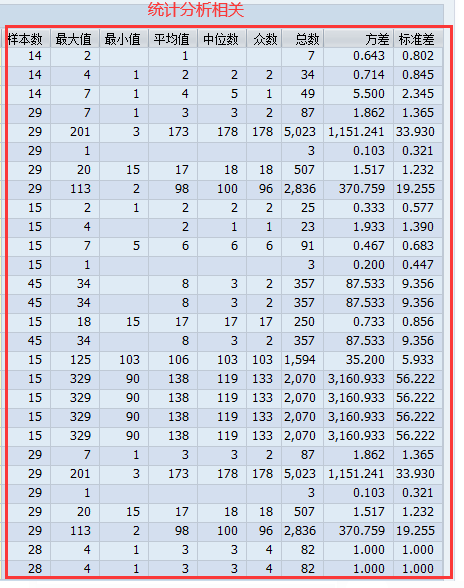
- 前景:大数据中含有多变量,使得信息过度复杂,难以完全探究变量之间的交互关系。主成分分析和探索性因子分析是两种用来探索和简化多变量复杂关系的常用方法。
- 主成分分析(Principal Component Analysis,PCA):一种数据降维技巧,将大量相关变量转化为一组很少的无关变量,这些无关变量被称为主成分(PC1,PC2…)。
- 探索性因子分析法(Exploratory Factor Analysis,EFA):一种发现潜在结构技巧,用于发现一组变量的更小的潜在结构来解释已观测到的显示变量关系。(将多元变量综合为少数几个核心因子)
- 二者差异:
- PCA主要用于数据降维,进而简化分析过程。
- EFA是假设生成工具,帮助理解众多变量间的关系,常用于理解社会科学的理论研究。
- PCA
- PC1/2概念:PC1和PC2是观测变量(X1-X5)的线性组合。
- PC1/2权重:通过最大化个主成分所解释的方差获得,同时保证各主成分间不相关。
- EFA
- 概念:因子(F1和F2)是观测变量的结构基础或“原因”
- 变量方差的误差(e1-e5),因子 (F1和F2)无法被直接观测(⚪表示),F1和F2之间双箭头表示两者可以有关联。
- 二者共性:
- 需要大样本来支撑稳定结果(因子分析需要5~10倍于变量书的样本数,几百个)
- 都用于探索和简化多变量复杂关系
- 基础包中的函数:
- PCA:princomp()
- EFA:factanal()
- psych包:具有更丰富的功能
| 函数 | 功能 |
|---|---|
| principal() | 含多种可选的方差旋转方法的PCA |
| fa() | 可用株洲,最小残差,加权最小平方或最大似然法估计的EFA |
| fa.parallel() | 含平行分析的碎石图 |
| factor.plot() | 绘制PCA或EFA的结果 |
| fa.diagram() | 绘制PCA或EFA的载荷矩阵 |
| scree() | PCA或EFA的碎石图 |
- 常见步骤
- 1.数据预处理:输入原始数据或者相关系数矩阵到principal()或fa()中,数据中不能有缺失值。
- 2.选择因子模型:选择PCA()数据降维或EFA(发现潜在结构),选EFA还要选一种估计因子模型的方法(入最大似然估计)
- 3.判断要选择的主成分/因子数目
- 4.选择主成分/因子
- 5.旋转主成分/因子
- 6.解释结果
- 7.计算主成分/因子得分
二、主成分分析
- 主成分分析(Principal Component Analysis,PCA):一种数据降维技巧,将大量相关变量转化为一组很少的无关变量,这些无关变量被称为主成分(PC1,PC2…)。
- 主成分:观测变量的线性组合。
- 公式(以第一主成分为例):PC1=a1X1+a2X2+…+akXk
- k个观测变量的加权组合
- 第一主成分PC1对初始变量集的方差解释性最大,第二主成分PC2排第二,同时与PC1正交(意义上表现为两者不相关,数值上表现为内积空间中两向量的内积为0,几何上表现为垂直(所以PC1,PC2绘制为图形后表现为x轴y轴))
- 只有两个主成分时,数据就会被降为2维,从而绘制为最常见的二维PCA图,当然后面也可以继续添加主成分,且皆于之前所有主成分正交。理论上可以选取于变量数量相同的主成分。
2.1、判断主成分的个数
- 最常见的办法:基于特征值,每个主成分都与相关系数矩阵的特征值相关联,如第一主成分与最大的特征值先关联,第二主成分与第二大的特征值相关联以此类推。
- 具体方法:三种特征值判别准测
- kaiser-harris准则:保留特征值大于1的主成分。
- Cattell碎石检验:绘制主成分数与特征值相关的碎石图,图形变化最大处之上的主成分都可以保存。
- 平行分析:模拟与初始矩阵相同大小的随机数据矩阵,若基于正式数据的某个特征值大于一组随机数据矩阵相应的平均特征值,则保留该主成分。
- 函数实现:psych包fa.parallel()函数 可以同时对上述三种准则进行评价。(不一定三种标准都符合,视情况决定主成分数,拿不准时,选高的数目可以增加解释度)
- 语法:
fa.parallel(x,n.obs=NULL,fm="minres",fa="both",nfactors=1,
main="Parallel Analysis Scree Plots",
n.iter=20,error.bars=FALSE,se.bars=FALSE,SMC=FALSE,ylabel=NULL,show.legend=TRUE,
sim=TRUE,quant=.95,cor="cor",use="pairwise",plot=TRUE,correct=.5)
- 示例1:
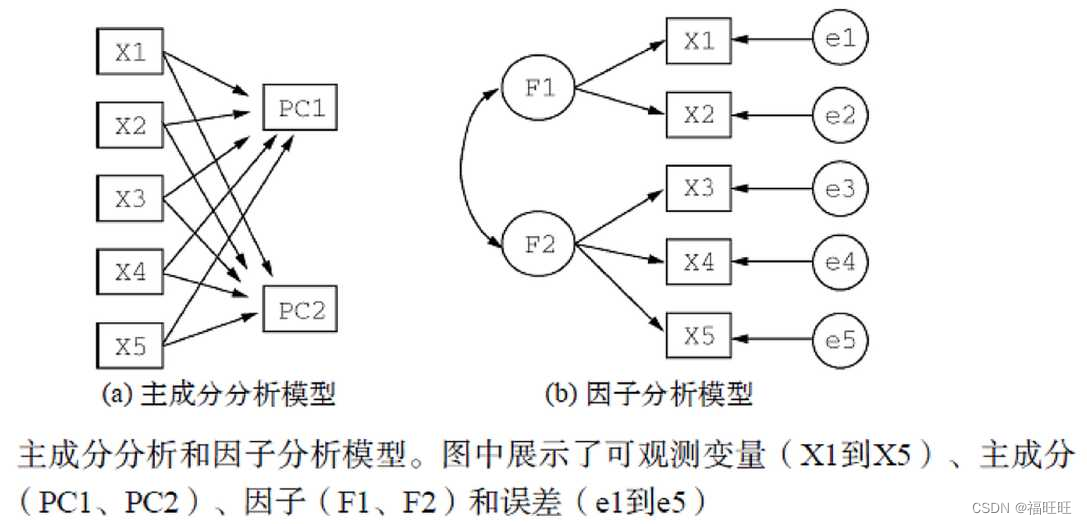
# 以样本数据集USJudgeRatings为例,包含了律师对美国高等法院法官的评分
head(USJudgeRatings)
CONT INTG DMNR DILG CFMG DECI PREP FAMI ORAL WRIT PHYS RTEN
AARONSON,L.H. 5.7 7.9 7.7 7.3 7.1 7.4 7.1 7.1 7.1 7.0 8.3 7.8
ALEXANDER,J.M. 6.8 8.9 8.8 8.5 7.8 8.1 8.0 8.0 7.8 7.9 8.5 8.7
ARMENTANO,A.J. 7.2 8.1 7.8 7.8 7.5 7.6 7.5 7.5 7.3 7.4 7.9 7.8
BERDON,R.I. 6.8 8.8 8.5 8.8 8.3 8.5 8.7 8.7 8.4 8.5 8.8 8.7
BRACKEN,J.J. 7.3 6.4 4.3 6.5 6.0 6.2 5.7 5.7 5.1 5.3 5.5 4.8
BURNS,E.B. 6.2 8.8 8.7 8.5 7.9 8.0 8.1 8.0 8.0 8.0 8.6 8.6
# 去除CONT对剩下11个变量进行评价
library(psych)
fa.parallel(USJudgeRatings[,-1],fa = "pc",n.iter = 100,main = "Scree plot with parallel analysis")
abline(h = 1)
# fa:显示主成分 (fa=“pc”) 或主轴因子分析 (fa=“fa”) 或主成分和主因子(fa=“both”)的特征值
# n.iter:要执行的模拟分析数
- 示例2:
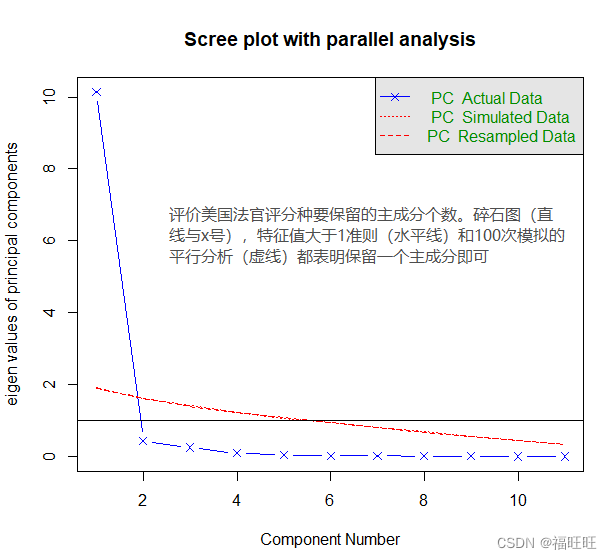
# Harman23.cor数据集内包含305个女孩的8个身体测量指标,Harman23.cor$cov为相关系数矩阵
> head(Harman23.cor$cov)
height arm.span forearm lower.leg weight bitro.diameter chest.girth chest.width
height 1.000 0.846 0.805 0.859 0.473 0.398 0.301 0.382
arm.span 0.846 1.000 0.881 0.826 0.376 0.326 0.277 0.415
forearm 0.805 0.881 1.000 0.801 0.380 0.319 0.237 0.345
lower.leg 0.859 0.826 0.801 1.000 0.436 0.329 0.327 0.365
weight 0.473 0.376 0.380 0.436 1.000 0.762 0.730 0.629
bitro.diameter 0.398 0.326 0.319 0.329 0.762 1.000 0.583 0.577
library(psych)
fa.parallel(Harman23.cor$cov,n.obs = 302,fa = "pc",n.iter = 100,show.legend = F, main = "Scree plot with parallel analysis")
abline(h = 1)
2.2、提取主成分
- 确定主成分数量后就需要提取主成分
- 函数:psych包principal()
- 功能:根据相关系数矩阵或原始数据矩阵进行主成分分析
- 语法:
principal(r,nfactors = ,rotate = ,scores = )
# r是相关系数矩阵或原始数据矩阵
# nfactors设定主成分数(默认为1)
# rotate指定旋转的方法(默认为varimax)
# 具体为"none", "varimax", "quartimax", "promax", "oblimin", "simplimax", and "cluster"
# scores设定为是否需要计算主成分得分(默认为否FALSE)
- 示例1:
> library(psych)
> principal(USJudgeRatings[,-1])
Principal Components Analysis
Call: principal(r = USJudgeRatings[, -1])
Standardized loadings (pattern matrix) based upon correlation matrix
# PCA只对相关系数矩阵进行分析,所以其会对原始数据进行转化
PC1 h2 u2 com
INTG 0.92 0.84 0.1565 1
DMNR 0.91 0.83 0.1663 1
DILG 0.97 0.94 0.0613 1
CFMG 0.96 0.93 0.0720 1
DECI 0.96 0.92 0.0763 1
PREP 0.98 0.97 0.0299 1
FAMI 0.98 0.95 0.0469 1
ORAL 1.00 0.99 0.0091 1
WRIT 0.99 0.98 0.0196 1
PHYS 0.89 0.80 0.2013 1
RTEN 0.99 0.97 0.0275 1
# PC1栏:成分载荷,指观测变量与主成分的相关系数(根据主成分数增加而增加)
# 成分载荷用于解释主成分的含义,其与每个变量高度相关
# h2栏:公因子方差,指主成分对每个变量的方差解释度
# u2栏:成分唯一性,指方差无法被主成分解释的比例(1-h2)
# 示例:PHYS这栏80%的方差都可以用PC1解释(h2=0.8),20%不能(u2=0.2013)。相对其他变量,该变量用PC1表示性最差。
PC1
SS loadings 10.13
Proportion Var 0.92
# SS loadings行包含了与主成分相关联的特征值,指与特定主成分相关联的标准化后的方差值(本例种,PC1的值为10.55)
# Proportion Var行表示每个主成分对整个数据集的解释程度(h2的均值)
Mean item complexity = 1
Test of the hypothesis that 1 component is sufficient.
The root mean square of the residuals (RMSR) is 0.04
with the empirical chi square 6.21 with prob < 1
Fit based upon off diagonal values = 1
- 示例2:
> library(psych)
> principal(Harman23.cor$cov,nfactors = 2,rotate = "none")
Principal Components Analysis
Call: principal(r = Harman23.cor$cov, nfactors = 2, rotate = "none")
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 PC2 h2 u2 com
height 0.86 -0.37 0.88 0.123 1.4
arm.span 0.84 -0.44 0.90 0.097 1.5
forearm 0.81 -0.46 0.87 0.128 1.6
lower.leg 0.84 -0.40 0.86 0.139 1.4
weight 0.76 0.52 0.85 0.150 1.8
bitro.diameter 0.67 0.53 0.74 0.261 1.9
chest.girth 0.62 0.58 0.72 0.283 2.0
chest.width 0.67 0.42 0.62 0.375 1.7
PC1 PC2
SS loadings 4.67 1.77
Proportion Var 0.58 0.22
Cumulative Var 0.58 0.81 # Proportion Var累计值(PCn值之和,这里表示PC1与PC2总共解释了81%的方差)
Proportion Explained 0.73 0.27 # 各个主成分的占比权重
Cumulative Proportion 0.73 1.00 # 占比权重的累计
Mean item complexity = 1.7
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
2.3、主成分旋转
- 概述:一系列将成分载荷变得更容易解释的数学方法,尽可能的对成分去噪。
- 方法:
- 正交旋转:使选择的成分保持不相关
- 最常用的正交旋转:方差极大旋转(varimax),对成分载荷去噪,使每个成分只有一组有限的变量来解释(既载荷阵列每列只有少数几个很大的载荷,其他都很小,详见示例)
- 斜交旋转:使选择的成分变得相关
- 正交旋转:使选择的成分保持不相关
- 函数:psych包principal()
- 参数:rotate指定旋转的方法(默认为varimax)
- 具体方法:“none”, “varimax”, “quartimax”, “promax”, “oblimin”, “simplimax”, and “cluster”
- 示例:
> library(psych)
> principal(Harman23.cor$cov,nfactors = 2)
Principal Components Analysis
Call: principal(r = Harman23.cor$cov, nfactors = 2)
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com # PC1,PC2变成了RC1,RC2,表示成分被旋转
height 0.90 0.25 0.88 0.123 1.2 # RC1表示PC1由前四个变量来解释,RC2表示PC2由后四个变量来解释
arm.span 0.93 0.19 0.90 0.097 1.1
forearm 0.92 0.16 0.87 0.128 1.1
lower.leg 0.90 0.22 0.86 0.139 1.1
weight 0.26 0.88 0.85 0.150 1.2
bitro.diameter 0.19 0.84 0.74 0.261 1.1
chest.girth 0.11 0.84 0.72 0.283 1.0
chest.width 0.26 0.75 0.62 0.375 1.2
RC1 RC2
SS loadings 3.52 2.92
Proportion Var 0.44 0.37 # 各个主成分的方差解释度趋同
Cumulative Var 0.44 0.81 # 累计方差解释性没有改变
Proportion Explained 0.55 0.45
Cumulative Proportion 0.55 1.00
# 由于失去了单个主成分方差最大化性质,此时RC1.RC2已经不能被称为主成分,仅为成分。
Mean item complexity = 1.1
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
2.4、获取主成分得分
- 概述:获取每个对象在该主成分上的的得分。
- 函数:psych包principal()
- 参数:scores设定为是否需要计算主成分得分(默认为否FALSE),存储在函数返回对象的scores元素中,只有输入原始数据才可以获得得分。
- 示例1:
> library(psych)
> pca <- principal(USJudgeRatings[,-1],scores = T)
> head(pca$scores)
PC1
AARONSON,L.H. -0.1857981
ALEXANDER,J.M. 0.7469865
ARMENTANO,A.J. 0.0704772
BERDON,R.I. 1.1358765
BRACKEN,J.J. -2.1586211
BURNS,E.B. 0.7669406
- 示例2:输入为相关系数矩阵,需要利用得分系数(标准的回归权重,存储在返回对象的weights元素中)
library(psych)
rc <- principal(Harman23.cor$cov,nfactors = 2)
round(unclass(rc$weights),2)
RC1 RC2
height 0.28 -0.05
arm.span 0.30 -0.08
forearm 0.30 -0.09
lower.leg 0.28 -0.06
weight -0.06 0.33
bitro.diameter -0.08 0.32
chest.girth -0.10 0.34
chest.width -0.04 0.27
# 通过PC1=0.28*height+0.30*arm.span+...+-0.04*chest.width来获取主成分得分。
# 可以进一步简化,对于PC1可以只看作前四个变量标准化得分的均值,对于PC2为后四个
三、探索性因子分析
- 探索性因子分析法(Exploratory Factor Analysis,EFA):通过挖掘隐藏在数据下的一组较少的更为基本的无法被观测的变量来解释一组可观测的变量的相关性。
- 因子(公共因子):无法被观测的变量,用于解释多个观测变量间共有的方差
- 公式:Xi=a1F1+a2F2+…+apFp+Ui
- Xi为第i个可观测变量(i=1,2…k),Fj是公共因子(j=1,2…p,p<k),Ui是Xi变量独有的部分(无法被公共因子解释的部分),ai每个因子对复合而成的可观测变量的贡献值
- 分析步骤:EFA的步骤与PCA及其相似。
3.1、判断需提取的公共因子数
- 具体方法:特征值判别准测(和PCA的不同之处在于,kaiser-harris准则:保留特征值大于0的主成分。)
- 函数:psych包fa.parallel()函数
- 示例:
library(psych)
# 数据集ability.cov中提供了变量的协方差矩阵,有112个样本
correlations <- cov2cor(ability.cov$cov)
# cov2cor()函数将协方差矩阵转化为相关系数矩阵(无缺失值)
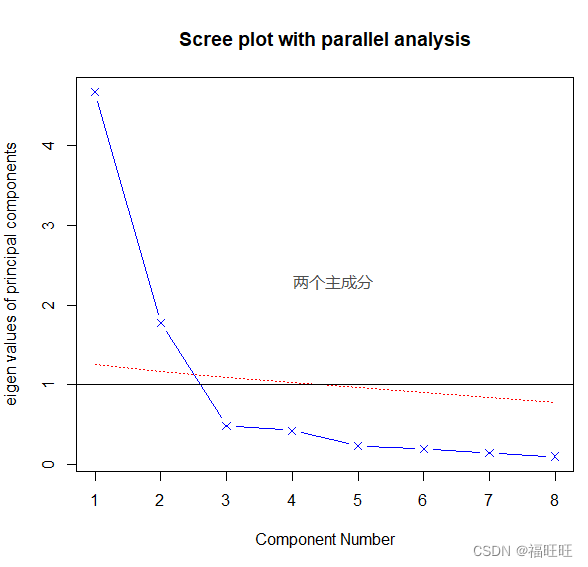
fa.parallel(correlations,fa = "both",n.obs = 112,n.iter = 100,main = "Scree plot with parallel analysis")
abline(h = 0)
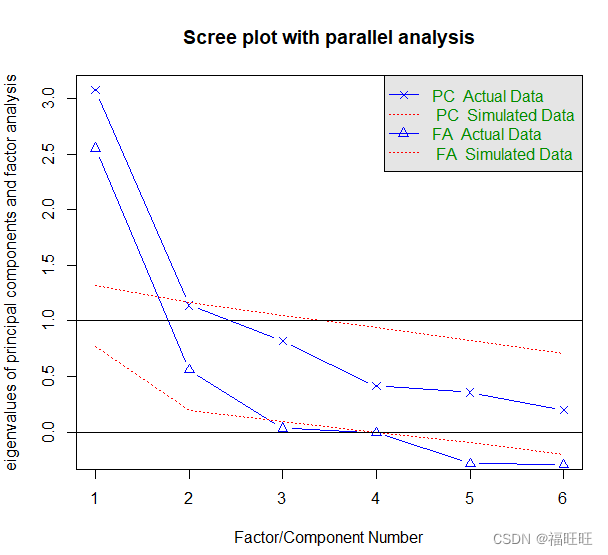
- 图解:参数选择both会同时显示PCA与EFA的碎石图
- PCA的结果看来可能选择一个(Cattell碎石检验,平行分析)或两个主成分(kaiser-harris准则),这时候两个(高估因子)可以更好的解释方差
- EFA的结果显然需要提取两个(特征值大于0)
3.2、提取公共因子
- 函数:psych包fa()
- 功能:根据相关系数矩阵或原始数据矩阵进行主成分分析
- 语法:
fa(r,nfactors = ,rotate = ,scores = ,n.obs = ,fm = )
# r是相关系数矩阵或原始数据矩阵
# nfactors设定因子数(默认为1)
# rotate指定旋转的方法(默认为互变异数最小法)
# 具体为正交:"none", "varimax", "quartimax", "bentlerT", "equamax", "varimin", "geominT" and "bifactor"
# 斜交:"Promax", "promax", "oblimin", "simplimax", "bentlerQ, "geominQ" and "biquartimin" and "cluster"
# scores设定为是否需要计算主成分得分(默认为否FALSE)
# n.obs观测数(输入相关系数矩阵时需要)
# fm设定因子化方法(默认极小残差法)
# 具体为:最大似然法(ml),主轴迭代法(pa),加权最小二乘法(wls),广义甲醛最小乘法(gls)和最小残差法(minres)
#最常用的为最大似然法(ml),当它出现不收敛的情况时使用主轴迭代法(pa)。
- 示例:
> library(psych)
> # 数据集ability.cov中提供了变量的协方差矩阵,有112个样本
> correlations <- cov2cor(ability.cov$cov)
> # 未旋转(none)的主轴迭代法(pa)
> fa(correlations,nfactors = 2,rotate = "none",fm = "pa")
Factor Analysis using method = pa
Call: fa(r = correlations, nfactors = 2, rotate = "none", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 h2 u2 com
general 0.75 0.07 0.57 0.432 1.0
picture 0.52 0.32 0.38 0.623 1.7
blocks 0.75 0.52 0.83 0.166 1.8
maze 0.39 0.22 0.20 0.798 1.6
reading 0.81 -0.51 0.91 0.089 1.7
vocab 0.73 -0.39 0.69 0.313 1.5
PA1 PA2
SS loadings 2.75 0.83
Proportion Var 0.46 0.14
Cumulative Var 0.46 0.60
Proportion Explained 0.77 0.23
Cumulative Proportion 0.77 1.00
Mean item complexity = 1.5
Test of the hypothesis that 2 factors are sufficient.
The degrees of freedom for the null model are 15 and the objective function was 2.48
The degrees of freedom for the model are 4 and the objective function was 0.07
The root mean square of the residuals (RMSR) is 0.03
The df corrected root mean square of the residuals is 0.06
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
PA1 PA2
Correlation of (regression) scores with factors 0.96 0.92
Multiple R square of scores with factors 0.93 0.84
Minimum correlation of possible factor scores 0.86 0.68
3.3、因子旋转
- 概述:一系列将因子载荷变得更容易解释的数学方法,尽可能的对成分去噪。
- 方法:
- 正交旋转:使选择的因子保持不相关
- 最常用的正交旋转:方差极大旋转(varimax),对因子载荷去噪,使每个因子只有一组有限的变量来解释(既载荷阵列每列只有少数几个很大的载荷,其他都很小,详见示例)
- 斜交旋转:使选择的因子变得相关
- 正交旋转:使选择的因子保持不相关
- 函数:psych包fa()
- 参数:rotate指定旋转的方法(默认为varimax)
- 具体方法:
- 正交:“none”(不旋转), “varimax”, “quartimax”, “bentlerT”, “equamax”, “varimin”, “geominT” and “bifactor”
- 斜交:“Promax”, “promax”, “oblimin”, “simplimax”, "bentlerQ, “geominQ” and “biquartimin” and “cluster”
- 具体方法:
- 示例1:正交旋转法提取因子(因子间会不相关)
> fa.varimax <- fa(correlations,nfactors = 2,rotate = "varimax",fm = "pa")
> fa.varimax
Factor Analysis using method = pa
Call: fa(r = correlations, nfactors = 2, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 h2 u2 com
general 0.49 0.57 0.57 0.432 2.0
picture 0.16 0.59 0.38 0.623 1.1
blocks 0.18 0.89 0.83 0.166 1.1
maze 0.13 0.43 0.20 0.798 1.2
reading 0.93 0.20 0.91 0.089 1.1
vocab 0.80 0.23 0.69 0.313 1.2
PA1 PA2
SS loadings 1.83 1.75
Proportion Var 0.30 0.29
Cumulative Var 0.30 0.60
Proportion Explained 0.51 0.49
Cumulative Proportion 0.51 1.00
Mean item complexity = 1.3
Test of the hypothesis that 2 factors are sufficient.
The degrees of freedom for the null model are 15 and the objective function was 2.48
The degrees of freedom for the model are 4 and the objective function was 0.07
The root mean square of the residuals (RMSR) is 0.03
The df corrected root mean square of the residuals is 0.06
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
PA1 PA2
Correlation of (regression) scores with factors 0.96 0.92
Multiple R square of scores with factors 0.91 0.85
Minimum correlation of possible factor scores 0.82 0.71
-
说明:reading和vocab在PA1上载荷较大,picture,blocks和maze在PA2上载荷较大,general(对非语言的普通智力测验)在PA1和PA2上比较平均说明存在一个语言智力因子一个非语言智力因子。
-
示例2:斜交旋转法提取因子(因子间会相关)
> install.packages("GPArotation")
> library(GPArotation)
# GPArotation is required for the Kaiser normalization
> fa.promax <- fa(correlations,nfactors = 2,rotate = "promax",fm = "pa")
> fa.promax
Factor Analysis using method = pa
Call: fa(r = correlations, nfactors = 2, rotate = "promax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 h2 u2 com # PA1 PA2两列构成了因子模式矩阵
general 0.37 0.48 0.57 0.432 1.9
picture -0.03 0.63 0.38 0.623 1.0
blocks -0.10 0.97 0.83 0.166 1.0
maze 0.00 0.45 0.20 0.798 1.0
reading 1.00 -0.09 0.91 0.089 1.0
vocab 0.84 -0.01 0.69 0.313 1.0
PA1 PA2
SS loadings 1.83 1.75
Proportion Var 0.30 0.29
Cumulative Var 0.30 0.60
Proportion Explained 0.51 0.49
Cumulative Proportion 0.51 1.00
With factor correlations of # 因子关联矩阵
PA1 PA2
PA1 1.00 0.55 # 两因子相关系数有0.55,相关性很大
PA2 0.55 1.00 # 如果因子关联很低就要重新使用正交旋转来简化
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
The degrees of freedom for the null model are 15 and the objective function was 2.48
The degrees of freedom for the model are 4 and the objective function was 0.07
The root mean square of the residuals (RMSR) is 0.03
The df corrected root mean square of the residuals is 0.06
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
PA1 PA2
Correlation of (regression) scores with factors 0.97 0.94
Multiple R square of scores with factors 0.93 0.88
Minimum correlation of possible factor scores 0.86 0.77
- 正交斜交旋转二者差异:
- 正交旋转:因子分析的重点在因子结构矩阵(变量与因子的相关系数)
- 斜交旋转:因子分析会考虑因子结构矩阵,因子模式矩阵(标准化的回归矩阵),因子关联矩阵(因子相关系数矩阵)
- 如果因子关联很低就要重新使用正交旋转来简化
- 因子模式矩阵,因子关联矩阵已经在斜交旋转中列出
- 公式:F=P*Phi 获得因子结构矩阵(F为因子载荷阵,P为因子模式矩阵,Phi为因子关联矩阵)
- 示例:
fsm <- function(oblique){
if(class(oblique)[2]=="fa" & is.null(oblique$Phi)){
warning("Object doesn't look like oblique EFA")
}else{
P <- unclass(oblique$loading)
F <- P %*% oblique$Phi
colnames(F) <- c("PA1","PA2")
return(F)
}
}
> fsm(fa.promax) # 因子结构矩阵,变量与因子的相关系数
PA1 PA2 # 因为允许了潜在因子相关,所以载荷阵列的噪音较大(不如正交的差距明显),但更符合实际情况
general 0.6362443 0.6879280
picture 0.3203301 0.6137902
blocks 0.4293252 0.9089946
maze 0.2491789 0.4496446
reading 0.9510795 0.4587468
vocab 0.8287066 0.4476297
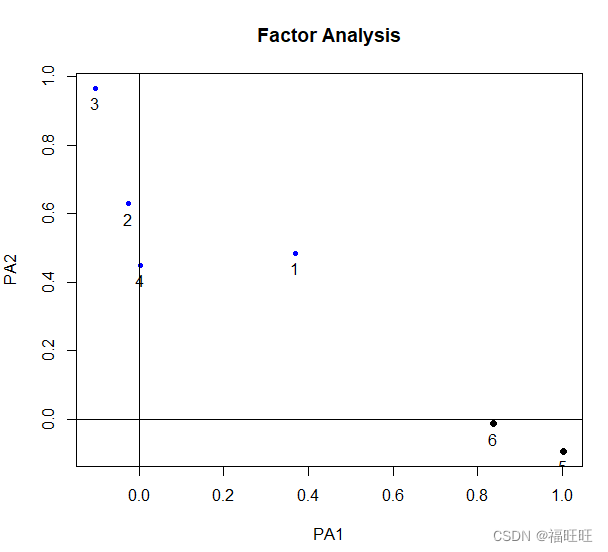
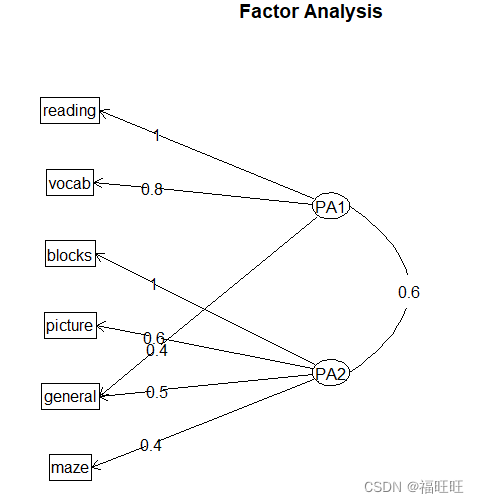
- 绘制旋转后图形函数:fa.diagram()或factor.plot()
- 示例
factor.plot(fa.promax)
fa.diagram(fa.promax,simple = F)
# simple = T(默认)时,仅显示每个因子下最大的载荷,以及因子间的相关系数。
3.4、因子得分
- 差异:相较于PCA,EFA不怎么关注因子得分。主成分分析的得分是精确计算得到的,因子分析的得分是估计得到的。
- 函数:psych包fa()
- 参数:scores设定为是否需要计算主成分得分(默认为否FALSE),得分系数(标准化的回归权重)存放在函数返回对象的weights元素中。
- 示例:
> fa.promax$weights
>
PA1 PA2
general 0.07836571 0.21091463
picture 0.02000694 0.09038071
blocks 0.03662858 0.70209400
maze 0.02700266 0.03453381
reading 0.74276722 0.03012597
vocab 0.17683183 0.03583324
3.5、其他于EFA相关的包
- FactoMineR包:提供了PCA和EFA方法,包含有潜变量模型,可以区分数值型变量与类别行变量
- FAiR包:使用遗传算法来估计因子分析模型,增强了模型参数估计能力,能处理不等式的约束条件。
- GPArotation包:含有许多因子旋转方法
- nFactors包:包含判断因子数目的许多复杂算法
- EFA只是统计中的一种应用广泛的潜变量模型,含有其他的潜变量模型。




![[附源码]Nodejs计算机毕业设计基于疫情防控的超市管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/e80eaa415fdd4d37ba2d52b8ae9a7af7.png)