前面两篇博客,介绍了 bufio 包中的缓冲读和写(bufio.go),下面再来介绍一下缓冲扫描(scan.go)。这个扫描的是用来对缓存读的更高级封装,提供了一些更易用的方法。
缓冲扫描
Scanner 提供了一个方便的接口来读取数据,例如使用换行符分隔的文本行文件。它可以很方便的将数据转换成各种各样的 Token。Token 的规范是被类型为 SplitFunc 的 split 函数定义的;默认的 split 函数会把输入转换成以去除行尾的文本行。在这个包内定义的 split 函数被用来将文件扫描成文本行,字节,UTF-8 字符和空格分隔的单词。客户端也可以提供自定义的 split 函数。
如果需要在错误处理或者超大 token 上进行更多控制,或者必须在 reader 上指向顺序扫描的程序,应该使用 bufio.Reader 替代。具体可以了解这篇博客的内容:Golang读取单行超长的文本
// Scanner provides a convenient interface for reading data such as
// a file of newline-delimited lines of text. Successive calls to
// the Scan method will step through the 'tokens' of a file, skipping
// the bytes between the tokens. The specification of a token is
// defined by a split function of type SplitFunc; the default split
// function breaks the input into lines with line termination stripped. Split
// functions are defined in this package for scanning a file into
// lines, bytes, UTF-8-encoded runes, and space-delimited words. The
// client may instead provide a custom split function.
//
// Scanning stops unrecoverably at EOF, the first I/O error, or a token too
// large to fit in the buffer. When a scan stops, the reader may have
// advanced arbitrarily far past the last token. Programs that need more
// control over error handling or large tokens, or must run sequential scans
// on a reader, should use bufio.Reader instead.
type Scanner struct {
r io.Reader // The reader provided by the client.
split SplitFunc // The function to split the tokens.
maxTokenSize int // Maximum size of a token; modified by tests.
token []byte // Last token returned by split.
buf []byte // Buffer used as argument to split.
start int // First non-processed byte in buf.
end int // End of data in buf.
err error // Sticky error.
empties int // Count of successive empty tokens.
scanCalled bool // Scan has been called; buffer is in use.
done bool // Scan has finished.
}
const (
// MaxScanTokenSize is the maximum size used to buffer a token
// unless the user provides an explicit buffer with Scanner.Buffer.
// The actual maximum token size may be smaller as the buffer
// may need to include, for instance, a newline.
MaxScanTokenSize = 64 * 1024
startBufSize = 4096 // Size of initial allocation for buffer.
)
它其实和前面的缓冲 Reader 很像,同样都是对于底层数据源的一种封装。但是它提供了一些更加方便的方法,对于缓冲 Reader 而言,它的方法通常比较低级,真正使用起来不是很方便(例如每次读取一个单词,这样就需要自己去对读取的数据做处理了)。相比之下,Scanner 提供了更为细化的方法,它会对缓冲区的内容进行切分成 token。token 可以是字节,字符,字符串或者单词。
注意:默认的缓冲区大小是 4096,最大的扫描 token 大小为:64*1024,即 64KB。
split 切分函数
我们来看一下这个包内最重要的函数的签名:
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error)
它是用来把输入转换成 token,我们不会直接使用它。只需要在创建 Scanner 时指定使用哪一个函数,然后调用 scan 即可。
bufio 包默认提供的几个 split 函数实现:
ScanBytes返回每个字节作为一个 tokenScanRunes返回每个字符(UTF-8)作为一个 tokenScanLines返回每个文本行(移除行尾标记\r?\n,注意这个正则表示\r\n或者\n)ScanWords返回每个被空格分隔的单词(只返回单词,不包括空格)
创建 Scanner 时,split 默认使用了 ScanLines 函数:
// NewScanner returns a new Scanner to read from r.
// The split function defaults to ScanLines.
func NewScanner(r io.Reader) *Scanner {
return &Scanner{
r: r,
split: ScanLines,
maxTokenSize: MaxScanTokenSize,
}
}
Scan 扫描方法
// Scan advances the Scanner to the next token, which will then be
// available through the Bytes or Text method. It returns false when the
// scan stops, either by reaching the end of the input or an error.
// After Scan returns false, the Err method will return any error that
// occurred during scanning, except that if it was io.EOF, Err
// will return nil.
// Scan panics if the split function returns too many empty
// tokens without advancing the input. This is a common error mode for
// scanners.
func (s *Scanner) Scan() bool
这个函数挺复杂的,这里只介绍一下它的作用。它将前进 Scanner 到下一个 token,可以通过 Bytes 或者 Text 方法获取到这个 Token。当扫描停止时,无论是到达输入的末尾还是出现错误,它都会返回 false。在扫描返回 false 之后,可以通过 Err 方法获取扫描期间发生的错误,除非这个错误是 io.EOF,那么 Err 会返回 nil。
也就是说,正常调用一次 Scan 会获取一个 token,它被存放于 Scanner 中。根据前面 Scanner 结构体中的定义,它是一个字节切片类型。这里提供了两种方式来获取它,一种是返回字节切片,另一种是字符串形式。
// Bytes returns the most recent token generated by a call to Scan.
// The underlying array may point to data that will be overwritten
// by a subsequent call to Scan. It does no allocation.
func (s *Scanner) Bytes() []byte {
return s.token
}
// Text returns the most recent token generated by a call to Scan
// as a newly allocated string holding its bytes.
func (s *Scanner) Text() string {
return string(s.token)
}
代码示例
所以一个普通的扫描文本的代码示例如下:
package main
import (
"bufio"
"fmt"
"strings"
)
func main() {
// 这里不使用字符串存储数据,而是使用字符串
// 这样我可以很方便地使用字符串作为 Reader
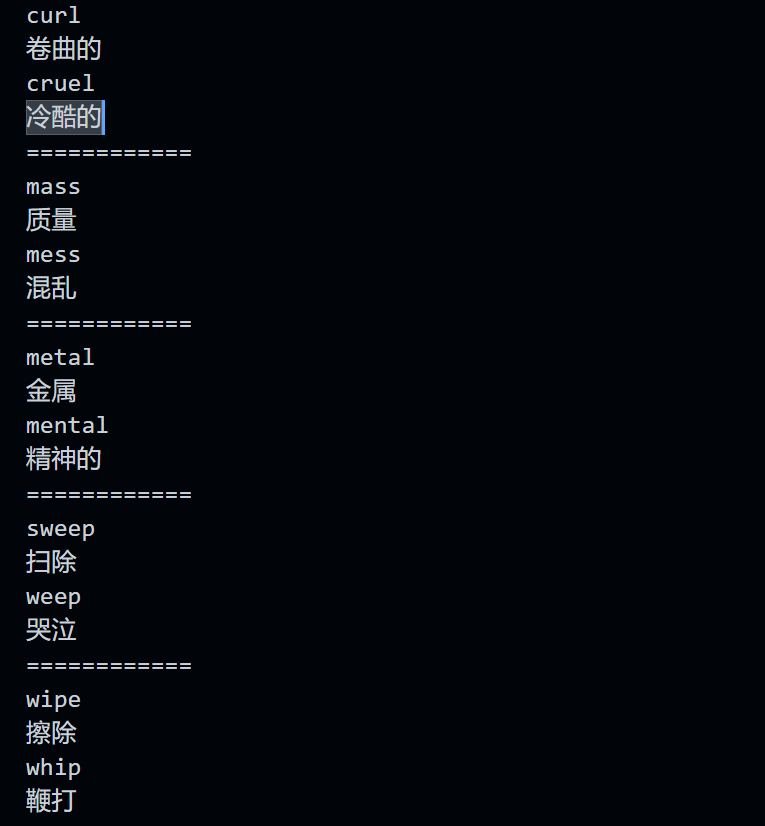
text := "curl 卷曲的\r\ncruel 冷酷的\n============\r\nmass 质量\nmess 混乱\n" +
"============\nmetal 金属\r\nmental 精神的\n============\r\r\nsweep 扫除\nweep 哭泣\n" +
"============\nwipe 擦除\r\r\nwhip 鞭打\n"
reader := strings.NewReader(text)
scanner := bufio.NewScanner(reader)
// bufio.ScanLines 是默认的,所以可以不显式指定
// scanner.Split(bufio.ScanWords)
var line string
for scanner.Scan() {
line = scanner.Text()
fmt.Print(line)
}
}

这里我打印扫描到的字符串 token,但是并不换行。可以看到输出是三行了。因为我在测试数据中加入了 \r\r\n,前面介绍了扫描字符串时,只会处理 \r\n 或者 \n 的情况。那么这种情况下,它输出的就是 字符串本身\r,最后会多一个 \r 字符。使用 fmt.Println() 输出是不行的,因为它默认添加一个 \n,但是 \r\n 和 \n 的显示效果是相同的,我是 Windows 平台
我们来看一下源码中是如何处理的,它有一个去除 \r 的函数。你看它的逻辑很简单,只是看最后一位是不是 \r,如果是的话就返回不包括最后一位的字节切片,否则返回全部字节切片。
// dropCR drops a terminal \r from the data.
func dropCR(data []byte) []byte {
if len(data) > 0 && data[len(data)-1] == '\r' {
return data[0 : len(data)-1]
}
return data
}
如果需要指定其他的分隔方式,可以将上面注释的代码放开,选择自己想要的函数。例如使用扫描单词的函数:scanner.Split(bufio.ScanWords)