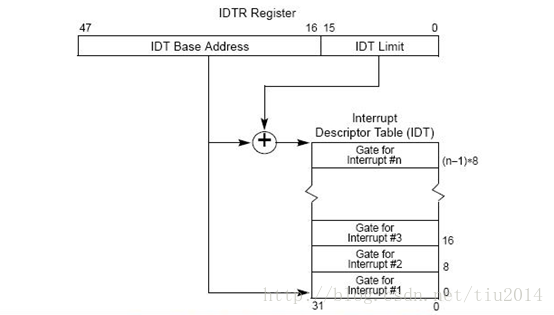
部署你的私有化对话机器人,只需要三步:
克隆 github 中文版 LLaMa repo
下载 HuggingFace 13B 16K 完整模型
启动对话窗口
没错,就是这么简单

我把这份操作指南,做成了一份 Jupyter Notebook 分享给大家,以下是链接:
https://colab.research.google.com/drive/1AQkWnz_dpcnOTHjcZOQBbWZNFak1-N1k?usp=sharing
这份笔记,支持中文 LLaMa 2 ,采用 13B-16K 的大模型,上下文可以达到 16K Token
它可以做哪些事情呢?
第一,声讨日本:


第二,擅长写校园爱情小说
你可以把它当 ChatGPT 的平替,大家发挥脑洞吧
好久不写文了,但其实我一直在写。
每当大趋势来的时候,大家总是很热地在讨论一件事情。但我已经倾向于先弄脏自己的手,即下场干活
当下生成式 AI 大热,写代码在我看来是比写文章,要好玩的多。比如:
我写了个编程小程序,用 ChatGPT 来辅助我学习 SQL 数据库知识:
8 年 SQL 人,撑不过前 6 题 <-- 戳我直达
我写了个视频转录工具,专门收拾那些没有字幕的油管视频
【免费】油管无字幕视频如何转录成文本 <-- 戳我直达
之前,大家也看到”樱木“的表现了,现在它依然在飞书发挥着余热。
接入飞书的 ChatGPT 对话机器人,SAM 来了
但这些,都建立在 ChatGPT/Claude.ai 的基础上,他们都是闭源的系统。对于我们想要进一步挖掘信息,完成智能问答等,都还有一定的难度与成本。
LLaMa 2 出来以后,事情发生了极大的变化。再一次让大众看到了开源的力量。让我们一起 “脏手” 吧