前言
Python 的 Asyncio 适合异步处理 IO 密集型的事务, 比如 HTTP 请求, 磁盘读写, 数据库操作等场景. 如果使用传统的顺序执行代码, 需要等待每次 IO 事务进行完成后才可以继续后面的代码. 通过在定义函数时添加修饰词 async 可以将其设置为异步函数, 后续配合 Asyncio 可以实现多线程并行提高代码的运行效率.
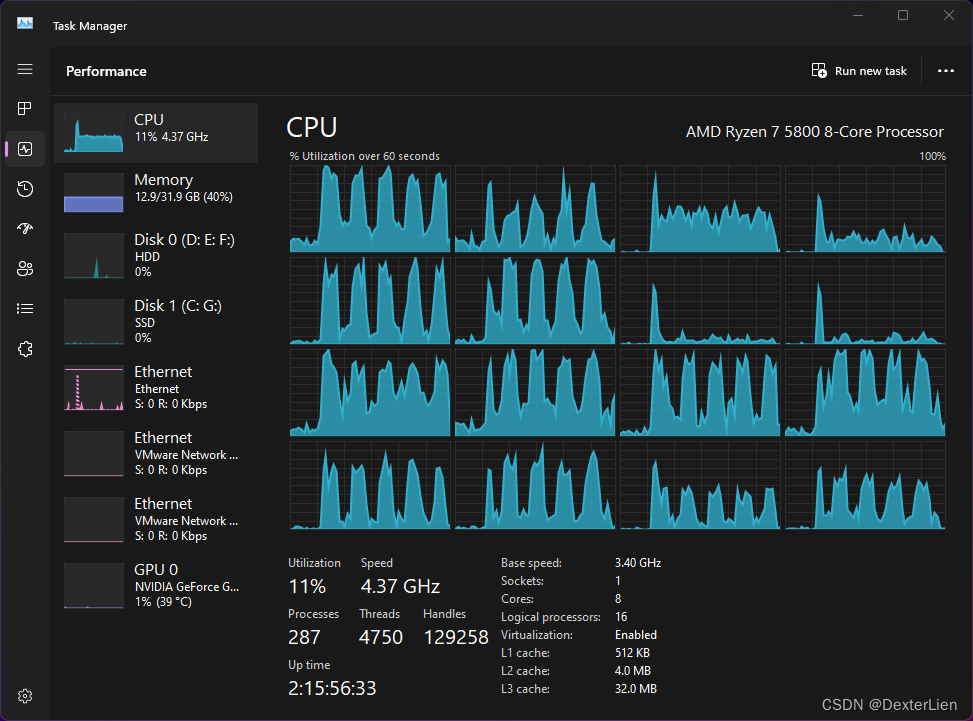
然而在实际应用过程中发现存在一个很明显的性能问题, Asyncio 并行运行过程中观察系统任务管理器可以看到并不是所有的 CPU 内核在工作, 一多半内核都是闲置状态. (资料中描述的是其实只有一个内核会工作)

本文将参考大佬 PENG QIAN 的文章 Harnessing Multi-Core Power with Asyncio in Python 进行学习和讨论.
传统方式
import asyncio
import random
import time
# 模拟 IO 阻塞的函数
async def fake_io_func():
io_delay = round(random.uniform(0.2, 1.0), 2)
await asyncio.sleep(io_delay)
result = 0
for i in range(random.randint(100_000, 500_000)):
result += i
return result
# 异步任务主函数
async def main():
start = time.monotonic()
tasks = [asyncio.create_task(fake_io_func()) for i in range(10000)]
await asyncio.gather(*tasks)
print(f'All tasks completed. And last {time.monotonic() - start:.2f} seconds.')
if __name__ == '__main__':
asyncio.run(main())
执行结果
All tasks completed. And last 188.95 seconds.
期间观察任务管理器
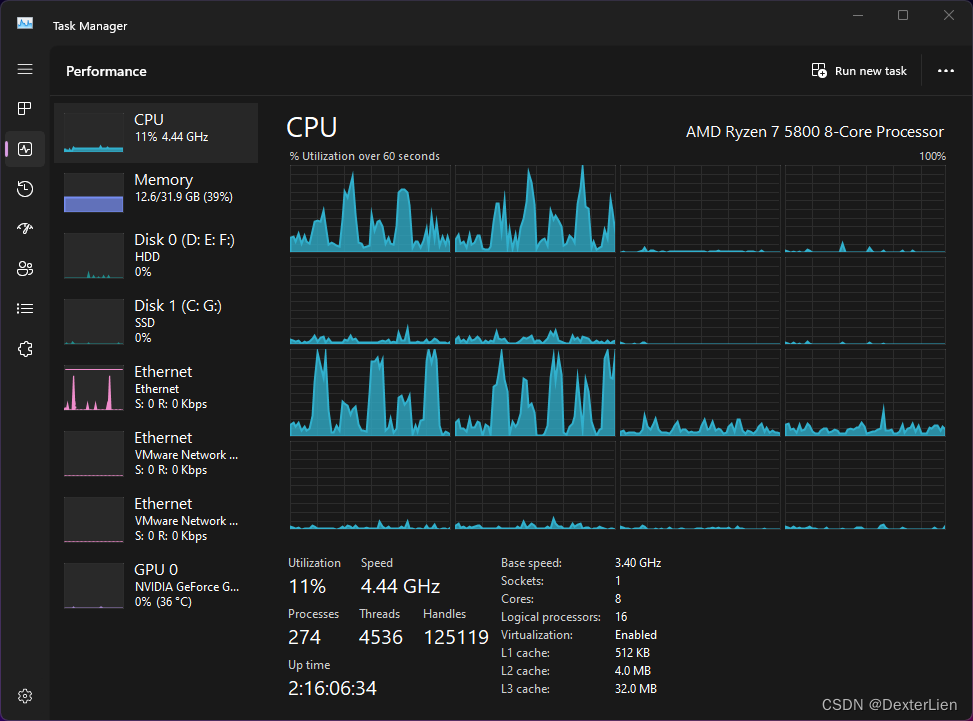
多核模式
import asyncio
import random
import time
from concurrent.futures import ProcessPoolExecutor
# 模拟 IO 阻塞的函数
async def fake_io_func():
io_delay = round(random.uniform(0.2, 1.0), 2)
await asyncio.sleep(io_delay)
result = 0
for i in range(random.randint(100_000, 500_000)):
result += i
return result
# 并行运行特定范围编号的任务
async def query_concurrently(begin_idx: int, end_idx: int):
""" Start concurrent tasks by start and end sequence number """
tasks = []
for _ in range(begin_idx, end_idx, 1):
tasks.append(asyncio.create_task(fake_io_func()))
results = await asyncio.gather(*tasks)
return results
# 在子进程中执行批量任务
def run_batch_tasks(batch_idx: int, step: int):
""" Execute batch tasks in sub processes """
begin = batch_idx * step + 1
end = begin + step
results = [result for result in asyncio.run(query_concurrently(begin, end))]
return results
# 修改后的主函数, 用来分配批量任务在子进程中并行执行
async def main():
""" Distribute tasks in batches to be executed in sub-processes """
start = time.monotonic()
loop = asyncio.get_running_loop()
with ProcessPoolExecutor() as executor:
tasks = [loop.run_in_executor(executor, run_batch_tasks, batch_idx, 2000)
for batch_idx in range(5)]
results = [result for sub_list in await asyncio.gather(*tasks) for result in sub_list]
print(f"We get {len(results)} results. All last {time.monotonic() - start:.2f} second(s)")
if __name__ == '__main__':
asyncio.run(main())
执行结果
We get 10000 results. All last 46.47 second(s)
期间观察任务管理器, 效果挺明显, 虽然还有俩核在摸鱼
Deep dive
下面开始柯南时间 😉
根据文章 Async IO in Python: A Complete Walkthrough 中的描述:
In fact, async IO is a single-threaded, single-process design: it uses cooperative multitasking, a term that you’ll flesh out by the end of this tutorial. It has been said in other words that async IO gives a feeling of concurrency despite using a single thread in a single process. Coroutines (a central feature of async IO) can be scheduled concurrently, but they are not inherently concurrent.
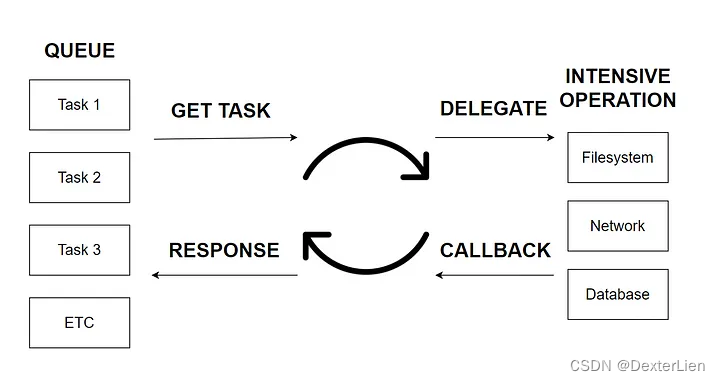
Asyncio 应该就是单线程, 单进程的设计. 其中对于 Asyncio 最重要的一个核心概念 event loop 可以参考下图理解:
Python 官方文档对 event loop 的解释:
The event loop is the core of every asyncio application. Event loops run asynchronous tasks and callbacks, perform network IO operations, and run subprocesses.
Application developers should typically use the high-level asyncio functions, such as asyncio.run(), and should rarely need to reference the loop object or call its methods. This section is intended mostly for authors of lower-level code, libraries, and frameworks, who need finer control over the event loop behavior.
event loop 说白了就是将 IO 密集的事务(函数)抽象成一个任务, 调用后并不会立刻返回结果, 而是扔到后台去执行, 啥时候执行完了啥时候返回结果. 所以如果并发执行多个任务的时候, 可以不用等待所有任务都执行完了再继续其余代码. 官方建议的是直接用高级封装后的 asyncio.run() 调用异步函数, 对于普通场景来说也就足够了, 但是在任务数量特别大的时候, 由于单核的限制, 会造成大量的计算资源的浪费, 并且效率极低.
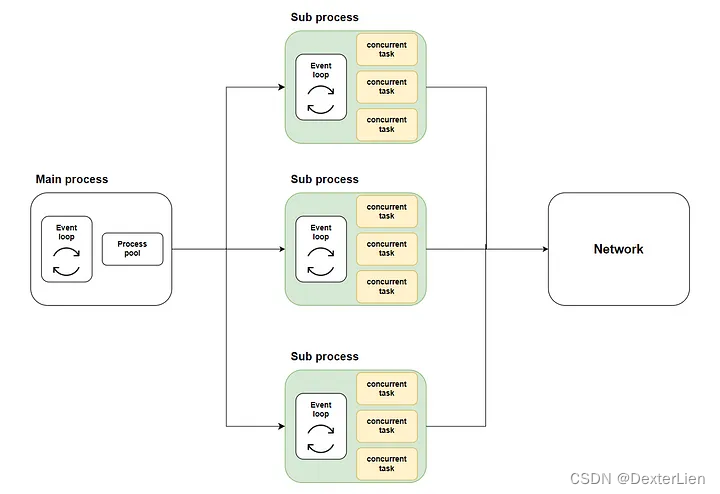
PENG QIAN 的思路是通过将任务切片, 交给多个子进程(Sub process), 每个子进程负责一部分任务并行执行. 由于子进程是可以在多个 CPU 内核上同时运行的, 这样就可以解决 event loop 先天不支持多 CPU 内核的性能问题.
下图中绿色部分表示子进程, 黄色表示 event loop 任务.
下面再来逐个理解改进后的函数.
query_concurrently 异步函数用于并行直接特定范围, 即切片后的任务:
async def query_concurrently(begin_idx: int, end_idx: int):
""" Start concurrent tasks by start and end sequence number """
tasks = []
for _ in range(begin_idx, end_idx, 1):
tasks.append(asyncio.create_task(fake_io_func()))
results = await asyncio.gather(*tasks)
return results
run_batch_tasks 注意这是一个普通非异步的函数, 用来批量调用 asyncio.run() 获取异步结果:
def run_batch_tasks(batch_idx: int, step: int):
""" Execute batch tasks in sub processes """
begin = batch_idx * step + 1
end = begin + step
results = [result for result in asyncio.run(query_concurrently(begin, end))]
return results
最后的异步主函数 main 使用偏底层的 event loop, 通过调用 loop.run_in_executor 将 run_batch_tasks 函数指定在 ProcessPoolExecutor 资源池中执行, loop.run_in_executor() 会返回 asyncio.Future 类型的对象,
async def main():
""" Distribute tasks in batches to be executed in sub-processes """
start = time.monotonic()
loop = asyncio.get_running_loop()
with ProcessPoolExecutor() as executor:
tasks = [loop.run_in_executor(executor, run_batch_tasks, batch_idx, 2000)
for batch_idx in range(5)]
results = [result for sub_list in await asyncio.gather(*tasks) for result in sub_list]
print(f"We get {len(results)} results. All last {time.monotonic() - start:.2f} second(s)")
下面这行代码用了单行嵌套循环的 Python 语法 (Nested loop), 看上去就挺不好读的:
results = [result for sub_list in await asyncio.gather(*tasks) for result in sub_list]
拆开写等价于这样:
results = []
for sublist in await asyncio.gather(*tasks):
for result in sublist:
results.append(result)
# 或者这样
results = [result for result in [sub_list for sub_list in await asyncio.gather(*tasks)]]