大致的思路
第一优化你的sql和索引;
第二加缓存,memcached,redis;
第三以上都做了后,还是慢,就做主从复制或主主复制,读写分离,可以在应用层做,效率高,也可以用三方工具
第四如果以上都做了还是慢,不要想着去做切分,mysql自带分区表,先试试这个
第五如果以上都做了,那就先做垂直拆分,其实就是根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统
第六才是水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key,为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
大表优化
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
1. 限定数据的范围
务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
2. 读/写分离
经典的数据库拆分方案,主库负责写,从库负责读;
主库和从库的之间的数据同步是通过binlog东西实现的
大家可以去扩展一下 读写分离具体实现方案以及当主从之间出现大的时差如何处理
3. 垂直分区
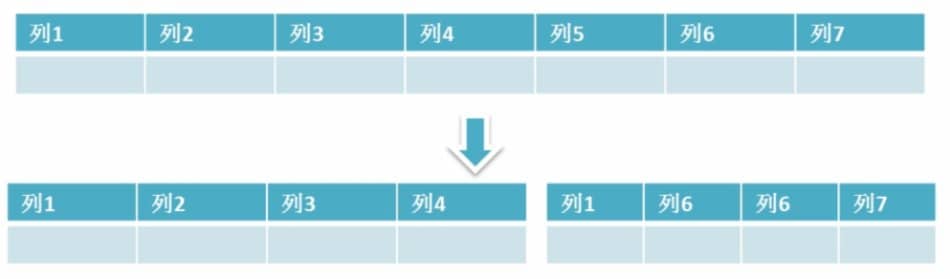
-
垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
-
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
4. 水平分区
保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
分库分表
分库主要解决的是并发量大的问题,(连接池有限)
分表: 那分表其实主要解决的是数据量大的问题。(b加树的深度吧)
水平分 防止热点数据倾斜 甚选字段
垂直分 (订单表分为商品,价格表,库存表等)
单表行数超过 500 万行或者单表容量超过 2GB之后,才需要考虑做分库分表了,小于这个数据量,遇到性能问题先
分库分表之后,id 主键如何处理?
因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
生成全局 id 有下面这几种方式:
-
UUID:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
-
数据库自增 id : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
-
利用 redis 生成 id : 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
-
Twitter的snowflake算法 :Github 地址:GitHub - twitter-archive/snowflake: Snowflake is a network service for generating unique ID numbers at high scale with some simple guarantees.。
-
美团的Leaf分布式ID生成系统 :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:Leaf——美团点评分布式ID生成系统 - 美团技术团队 。