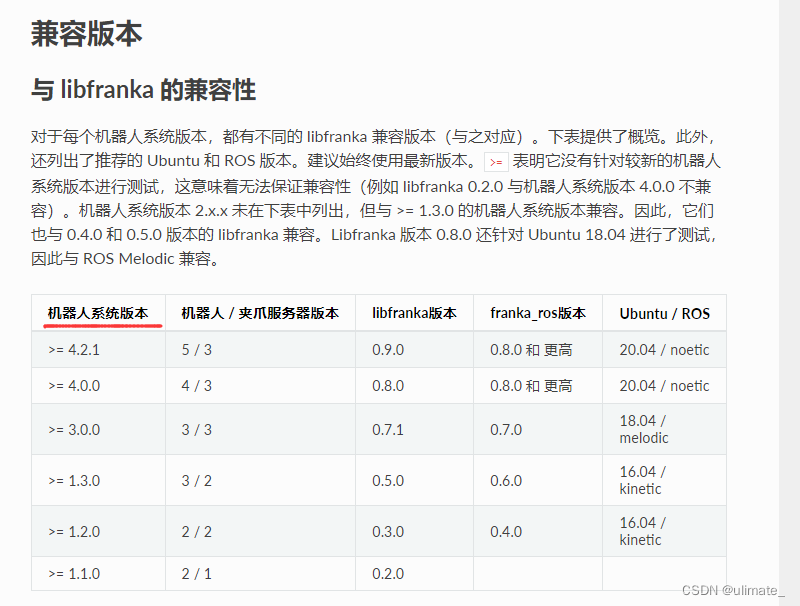
🌈🌈🌈机器学习 实战系列 总目录
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
手撕线性回归1之线性回归类的实现
手撕线性回归2之单特征线性回归
手撕线性回归3之多特征线性回归
手撕线性回归4之非线性回归# 5、数据预处理
5.1 数据读入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from linear_regression import LinearRegression
首先是导包numpy、pandas、matplotlib素质三连,从文件中linear_regression导入类
data = pd.read_csv('../data/world-happiness-report-2017.csv')
train_data = data.sample(frac = 0.8)
test_data = data.drop(train_data.index)
- 读csv文件
- 按80比例分配训练数据
- 按20比例分配训练数据
input_param_name = 'Economy..GDP.per.Capita.'
output_param_name = 'Happiness.Score'
x_train = train_data[[input_param_name]].values
y_train = train_data[[output_param_name]].values
x_test = test_data[input_param_name].values
y_test = test_data[output_param_name].values
- 原始数据中取出一列"索引"作为输入
- 原始数据中取出一列"索引"作为标签
- 按照索引取出训练集数据
- 按照索引取出训练集标签
- 按照索引取出测试集数据
- 按照索引取出测试集标签
plt.scatter(x_train,y_train,label='Train data')
plt.scatter(x_test,y_test,label='test data')
plt.xlabel(input_param_name)
plt.ylabel(output_param_name)
plt.title('Happy')
plt.legend()
plt.show()
- 训练数据散点图
- 测试数据散点图
打印结果:

5.2 训练
num_iterations = 500
learning_rate = 0.01
- 迭代次数,即整个数据集训练次数
- 学习率
linear_regression = LinearRegression(x_train,y_train)
(theta,cost_history) = linear_regression.train(learning_rate,num_iterations)
print ('开始时的损失:',cost_history[0])
print ('训练后的损失:',cost_history[-1])
- 数据传入类中,实例化类得到linear_regression 对象
- linear_regression 对象调用train方法,得到参数和损失
- 打印开始损失
- 打印结束损失
打印结果:
开始时的损失: 14.633306098916812
训练后的损失: 0.2275173194286417
plt.plot(range(num_iterations),cost_history)
plt.xlabel('Iter')
plt.ylabel('cost')
plt.title('GD')
plt.show()
打印结果:

5.3 测试
predictions_num = 100
x_predictions = np.linspace(x_train.min(),x_train.max(),predictions_num).reshape(predictions_num,1)
y_predictions = linear_regression.predict(x_predictions)
- 选用100个数据
- x_predictions:
- x_train.min(),x_train.max(),前面的训练数据中的最小值和最大值
- np.linspace(x_train.min(),x_train.max(),predictions_num),最小值和最大值为范围均匀分成100个数据
- 维度调整为(100,1)
- 使用定义的线性回归将x_predictions预测成y_predictions
plt.scatter(x_train,y_train,label='Train data')
plt.scatter(x_test,y_test,label='test data')
plt.plot(x_predictions,y_predictions,'r',label = 'Prediction')
plt.xlabel(input_param_name)
plt.ylabel(output_param_name)
plt.title('Happy')
plt.legend()
plt.show()
- 训练数据和训练标签的散点图
- 测试数据和测试标签的散点图
- x_predictions和y_predictions 对应的一条直线
- 画图
打印结果:

6、数据预处理
机器学习开发流程中一定有一个数据预处理的重要流程,在很多实际的任务中,数据预处理甚至比网络设计更复杂更重要。
6.1 归一化函数
这部分函数主要为了将原始数据放入到一个合适的范围内,一般是[0,1]的范围或者[-1,1]的范围,人能识别数据,计算机只识别数字,机器学习只能认识特征
def normalize(features):
features_normalized = np.copy(features).astype(float)
features_mean = np.mean(features, 0)
features_deviation = np.std(features, 0)
if features.shape[0] > 1:
features_normalized -= features_mean
features_deviation[features_deviation == 0] = 1
features_normalized /= features_deviation
return features_normalized, features_mean, features_deviation
- 深度复制传进来的原始数据features,转换为float格式
- 返回原始数据的均值
- 返回原始数据的标准差
- 判断features是否只有一个数字
- 原始数据减去均值
- 判断标准差是否为0,如果为0 则改为1(防止分母出现为0的情况)
- 原始数据减去均值的结果再除以标准差
- 返回处理结果、均值、标准差
6.2 数据预处理函数
在此次的数据预处理中只用到了归一化操作
def prepare_for_training(data, polynomial_degree=0, sinusoid_degree=0, normalize_data=True):
num_examples = data.shape[0]
data_processed = np.copy(data)
features_mean = 0
features_deviation = 0
data_normalized = data_processed
if normalize_data:
(data_normalized, features_mean, features_deviation ) = normalize(data_processed)
data_processed = data_normalized
if sinusoid_degree > 0:
sinusoids = generate_sinusoids(data_normalized, sinusoid_degree)
data_processed = np.concatenate((data_processed, sinusoids), axis=1)
if polynomial_degree > 0:
polynomials = generate_polynomials(data_normalized, polynomial_degree, normalize_data)
data_processed = np.concatenate((data_processed, polynomials), axis=1)
data_processed = np.hstack((np.ones((num_examples, 1)), data_processed))
return data_processed, features_mean, features_deviation
- 计算有多少个数
- 深度复制原始数据
- 初始均值0(避免提示报错而已)
- 初始标准差0(避免提示报错而已)
- 定义初始归一化数据(避免提示报错而已)
- 将数据传入初始化函数
- 特征变换sinusoidal
- 特征变换polynomial
- 原始数据拼接了一列1
- 返回数据
7、整体流程解读
单特征线性回归整体流程,从Non-linearRegression.py文件的这行代码开始:
data = pd.read_csv(‘…/data/non-linear-regression-x-y.csv’)
- 读数据
- 选择特征
- 画一下原始数据的散点图(训练数据、测试数据)
- 进入线性回归类
- 在线性回归类进入初始化函数
- 在初始化函数进入数据预处理函数
- 在数据预处理函数中进入归一化操函数后,返回处理结果、均值、标准差,返回初始化函数
- 初始化函数系列赋值操作
- 退出线性回归类,返回线性回归实例化对象
- 线性回归对象调用trian函数
- 在trian函数中调用梯度下降函数
- 在梯度下降函数中多次调用参数更新函数以及损失计算函数
- 线性回归对象的trian函数返回损失,返回最后的参数
- 打印损失
- 画出损失下降过程
- 进行预测
手撕线性回归1之线性回归类的实现
手撕线性回归2之单特征线性回归
手撕线性回归3之多特征线性回归
手撕线性回归4之非线性回归