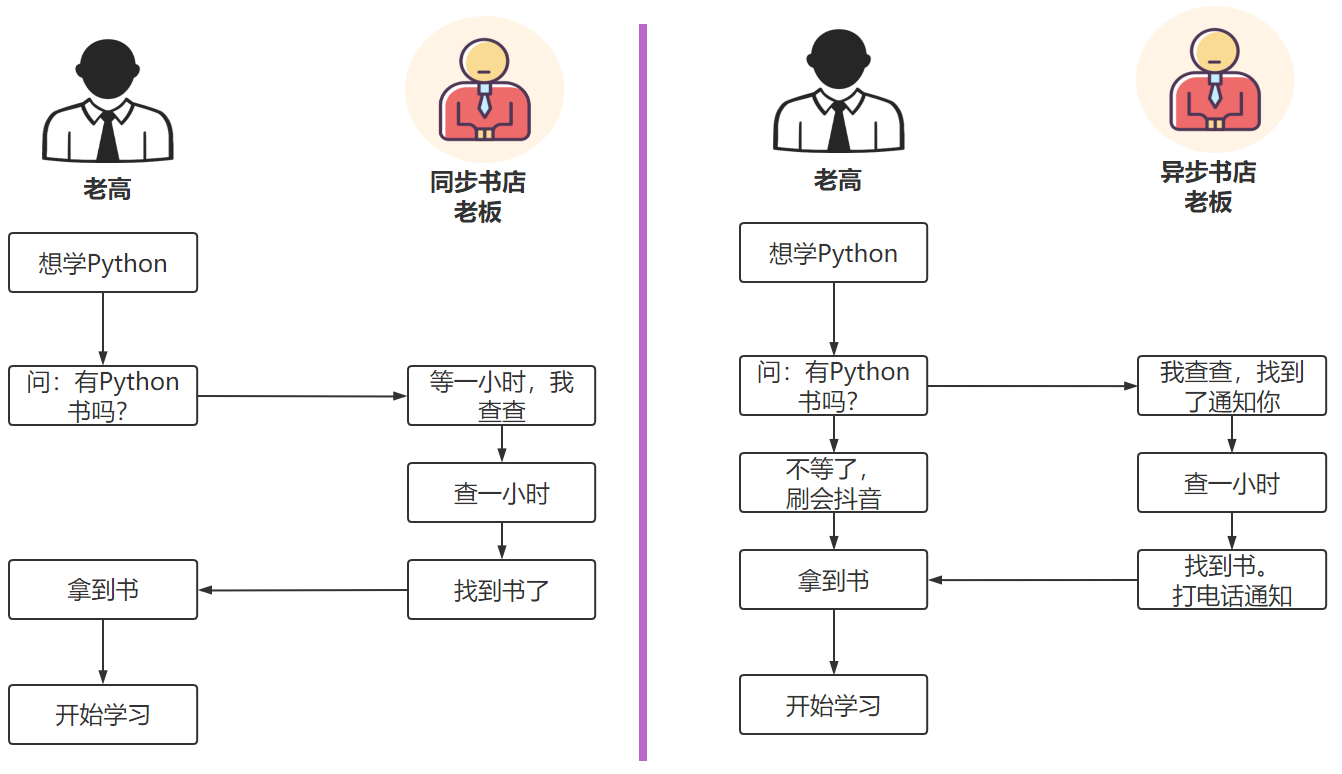
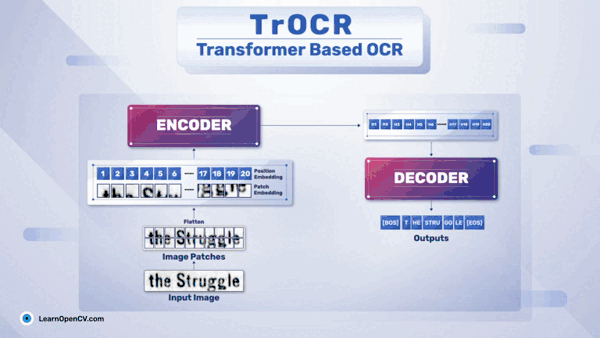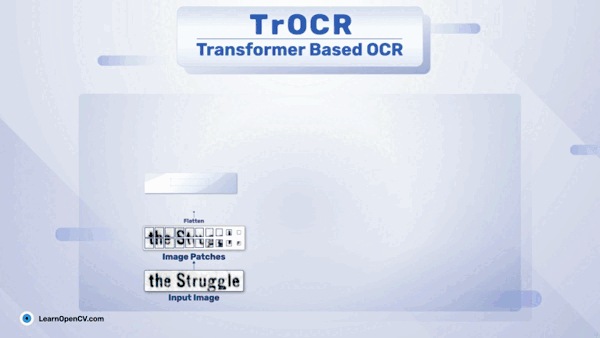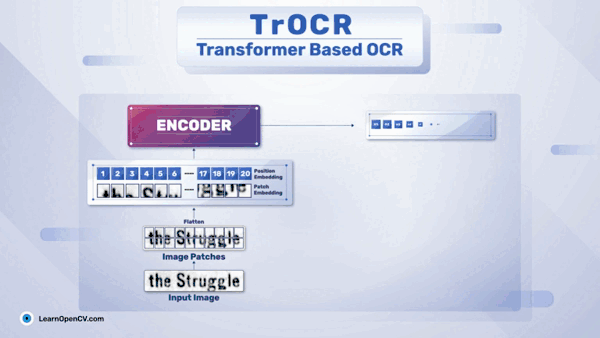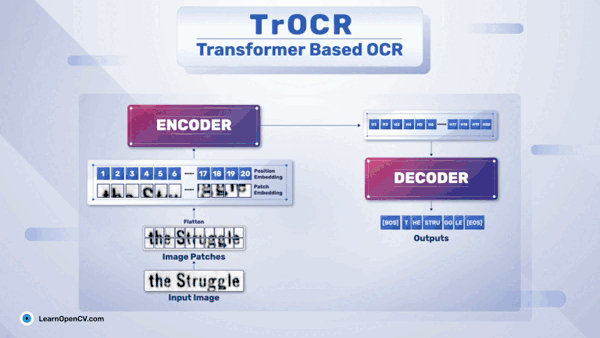
一.需求
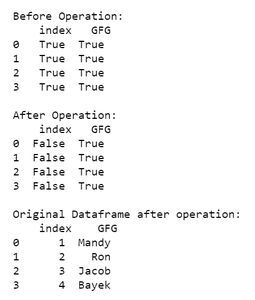
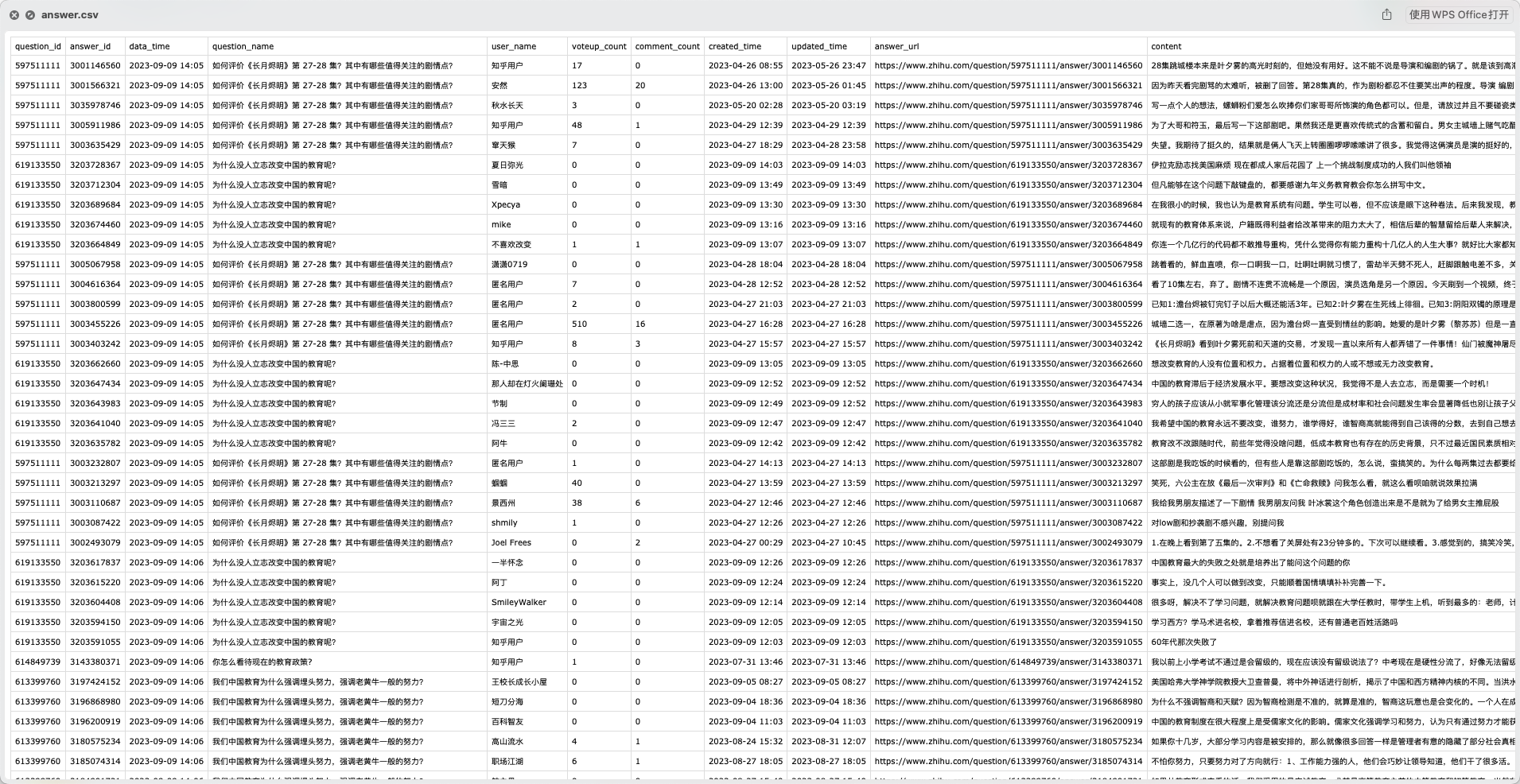
爬取任意问题下的所有回答,如下图:

1.根据问题,批量获取问题下的所有回答、与对应问题的关系到answer.csv文件;
2.保存当前问题基本信息到quesiton_info.csv文件;
二.展示爬取结果

三.讲解步骤
3.1 新建项目
本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤:
1.新建项目
scrapy startproject zhihu
2.新建 spider
scrapy genspider zhihu "zhihu.com"
3.运行 spider
scrapy crawl zhihuSpider
注意:zhihuSpider 是spider中的name
3.2 开发爬虫
F12,打开调试面板,经过调试后发现问题下的前5条回答数据不是通过接口返回的,第一页采用了服务端渲染的技术,第一页的数据在html的js中,如下图:
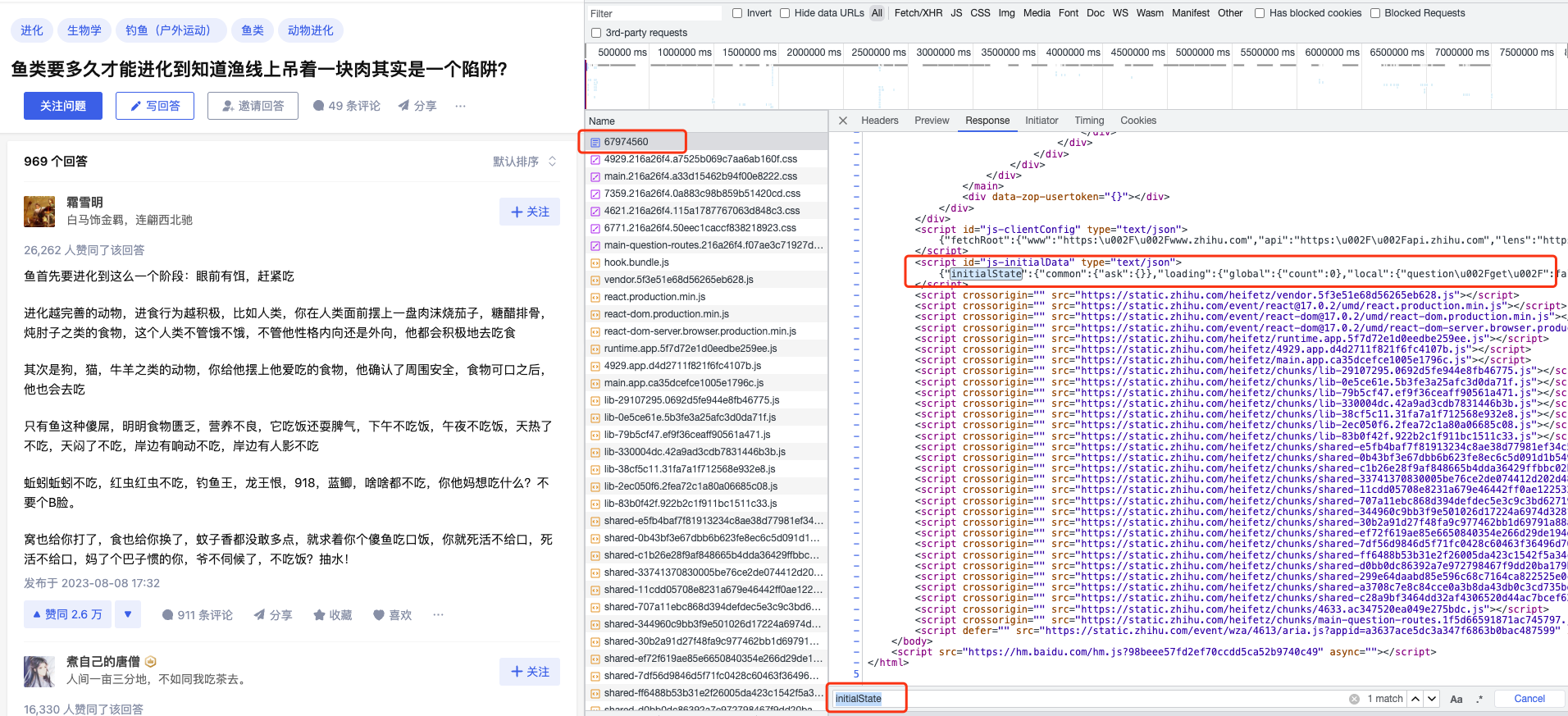
解析html中的内容使用bs4包,如下:
from bs4 import BeautifulSoup as bs
...
soup = bs(html, "html.parser")
# 拿到渲染HTML的json数据
initialData = soup.find("script", {"id": "js-initialData"}).get_text()
jsonData = json.loads(initialData)
# 解析出当前问题的基本信息,比如问题title,总回答数量、浏览量、关注人数、评论量...
current_questions = jsonData.get("initialState").get('entities').get(
'questions')
`
把上面获取到的首页回答的数据整理出来就是第一页的回答内容啦;
编写item:
这里的字段就是要保存到csv文件的字段名称;
```py
class QuestionInfoItem(scrapy.Item):
question_id = scrapy.Field() # 问题ID
question_name = scrapy.Field() # 问题名称
type = scrapy.Field() # 问题类型
question_url = scrapy.Field() # 问题 url
topics = scrapy.Field() # 关键词
follower_count = scrapy.Field() # 关注者数
visit_count = scrapy.Field() # 被浏览数
answer_count = scrapy.Field() # 回答数
comment_count = scrapy.Field() # 评价数
class AnswerItem(scrapy.Item):
question_id = scrapy.Field() # 问题 ID
answer_id = scrapy.Field() # 问题 ID
data_time = scrapy.Field() #数据日期
user_name = scrapy.Field() # 账号昵称
question_name = scrapy.Field() # 问题名称
content = scrapy.Field() # 回答的内容
voteup_count = scrapy.Field() # 赞同数量
comment_count = scrapy.Field() # 评论数量
created_time = scrapy.Field() # 发布日期
updated_time = scrapy.Field() # 编辑日期
answer_url = scrapy.Field() # 回复 url
编写管道:
class QuestionInfoPipeline():
def open_spider(self, spider):
# 问题ID 问题名称 类型 关键词 关注者数 被浏览数 回答数 评价数
self.question_info_line = "question_id,question_name,type,question_url,follower_count,visit_count,evaluate_score,comment_count\n"
data_dir = os.path.join(DATA_URI)
file_path = data_dir + '/question_info.csv'
#判断文件夹存放的位置是否存在,不存在则新建文件夹
if os.path.isfile(file_path):
self.file = open(file_path, 'a+', encoding='utf-8')
else:
if not os.path.exists(data_dir):
os.makedirs(data_dir)
self.file = open(file_path, 'a+', encoding='utf-8')
self.file.write(self.question_info_line)
def close_spider(self, spider): # 在关闭一个spider的时候自动运行
self.file.close()
def process_item(self, item, spider):
try:
if item['key'] == 'question':
info = item.get('info')
question_info_line = '{},{},{},{},{},{},{},{}\n'.format(
info.get('question_id', ''), #问题ID
info.get('question_name', ''), # 问题名称
info.get('type', ''), # 问题类型
info.get('question_url', ''), #问题 URL
info.get('follower_count', 0), # 关注者数
info.get('visit_count', 0), # 被浏览数
info.get('answer_count', 0), # 回答数
info.get('comment_count', 0), # 评价数
)
self.file.write(question_info_line)
except BaseException as e:
print("QuestionInfo错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")
return item
...
编写爬虫解析代码:
def question_parse(self, response):
html = response.text
q_id = response.meta['q_id']
soup = bs(html, "html.parser")
# 拿到渲染HTML的json数据
initialData = soup.find("script", {"id": "js-initialData"}).get_text()
jsonData = json.loads(initialData)
# 解析出当前问题的基本信息,比如问题title,总回答数量、浏览量、关注人数、评论量...
current_questions = jsonData.get("initialState").get('entities').get(
'questions')
question_item = QuestionInfoItem()
question = current_questions.get(q_id)
question_item['question_id'] = q_id
question_item['question_name'] = question['title']
question_item['question_url'] = 'https://www.zhihu.com/question/%s' % (
q_id)
question_item['type'] = 'qeustion'
question_item['follower_count'] = question['followerCount']
question_item['visit_count'] = question['visitCount']
question_item['answer_count'] = question['answerCount']
question_item['comment_count'] = question['commentCount']
yield {"key": 'question', "info": question_item}
initialState = jsonData.get("initialState")
# 解析出首页中回答的map
ansers_map = initialState.get('entities').get('answers')
# 解析出首页中回答出现的顺序
answers = initialState.get('question').get('updatedAnswers')
ansers_list = answers.get(q_id).get('newIds')
# 根据回答顺序+回答map,把他俩组装成feed接口返回的报文格式
first_page_result = tool.format_first_page_data(
ansers_list, ansers_map, q_id)
# 解析出首页中回答出现的顺序
isEnd = initialState.get('commentManage').get('subCommentList').get(
'paging').get('isEnd')
...
3.3 添加延时中间件
注意:多线程爬虫虽然每秒可并发16个请求,但是知乎服务器有反扒,太快会背关小黑屋,因此需要对请求作延时处理。
在中间件middlewares.py文件中添加如下中间件:
class RandomDelayMiddleware(object):
def __init__(self, delay):
self.delay = delay
@classmethod
def from_crawler(cls, crawler):
delay = crawler.spider.settings.get("RANDOM_DELAY", 10)
if not isinstance(delay, int):
raise ValueError("RANDOM_DELAY need a int")
return cls(delay)
def process_request(self, request, spider):
# 随机延时7-12s之间的3位小数结尾的时间,防止封号,务必添加
delay = round(random.uniform(7, 12), 3)
logging.debug("随机延时几秒: %ss" % delay)
time.sleep(delay)
至此,本案例核心逻辑讲解完毕。完整代码包括: 翻页、保存csv、判断数据类型分类归类、x-zse-96加密文件、、、
3.4 完成项目说明手册:

四、获取完整源码
编码不易,请支持原创!
本案例完整源码及csv结果文件,付费后可获取↓
获取后,有任何代码问题,均负责讲解答疑,保证正常运行!
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复**“知乎问答”**即可获取。
源码地址:
https://pan.baidu.com/s/1KoGg0tXE93vI8y4gzWeovg?pwd=****
提取码: ****