项目简介
这个项目是实现了一个高效的并发内存池。它的原型的goggle的一个开源项目tcmalloc,即thread-cache malloc(线程缓存的malloc),实现了高效多线程的内存管理,可实现对系统提供的内存分配函数malloc和free的替代。
内存碎片
内存碎片分为外碎片和内碎片。
外碎片是指,未被分配给进程的内存块,由于其太小了,无法满足进程申请的内存大小。
内碎片是指,内存块已经分配给了进程,但是由于各种原因(比如结构体的内存对齐),不会使用内存块的某一部分,一直处于空闲状态,直至释放。
定长内存池设计
所谓定长,就是每次申请出来的内存大小都是一样的。
申请过程:首先在堆上申请一大块内存,按对象的大小从大块内存中截取对应的内存供进程使用。
释放过程:内存池中维护一个freelist_的链表,用来回收释放掉的内存,采用头插的方式挂在freelist_后边。在申请内存过程中,优先查看freelist_后边是否回收的内存块,优先使用freelist_中的内存供进程申请用。达到重复利用的目的。

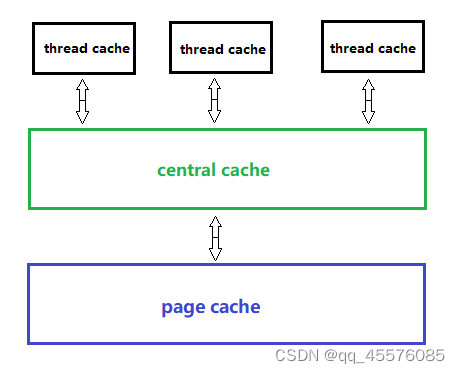
项目框架
该内存池由3部分组成
1. thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内 存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
2. central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对 象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。
3. page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache 会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
内存池实现逻辑
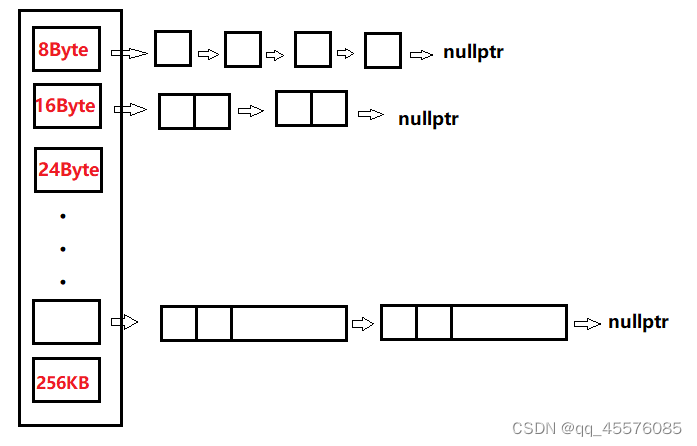
threadcache
threadcache设计称为一个hash结构,申请的大小在其区间按各自的对齐数均匀划分桶。
其中hash的对其规则如下:

1B<= bites<128B,对齐数8B,其划分的桶就有128/8=16个,即8、16 ······ 128
8KB<=bites<64KB,对齐数1KB,其划分的桶就有(64 - 8)/1=56个,即9、10 ······ 64
64K<=bites<256KB,对齐数8K,其互粉的桶就有(256-64)/8=24个,即72、80 ······ 256
ps:这里的排列时不同的桶下应挂的小内存的大小,并不是hash桶的下标。其下标是按其排列顺序由低到高,由0开始的。
关于内碎片浪费的计算:
比如申请的大小为为129B,就会按16B对齐,实际申请128B+16B=144B,就会多出15B的内碎片,内存浪费率就是15B/144B=0.104。
再比如申请的大小为1025B,就会按128B对齐,实际申请1204+128=1332B,多出127B的内碎片,内存浪费率就是127B/1332B=0.095。
对上边内存规则有了一定认识之后,对下边threadcache的结构才会有更深刻的理解。
TLS(Thread Local Storage)线程本地存储技术:普通的全局变量在多线程中是贡献的,一个线程对其进行了修改,所有线程都能看见这个修改,而线程私有的全局变量与普通全局变量不同,线程私有的全局变量是线程的私有财产,每个线程都有自己的一份副本,某个线程对其所做的修改只会影响到自己的副本,并不会修改其他线程的副本。
申请内存
1、每个线程通过TLS无锁获取自己独属的ThreadCache对象
2、如果ThreadCache中对应hash桶下边的freelist_结构不为空,从中取出内存供进程使用
3、如果ThreadCache中对应hash桶下边的freelist_结构为空,向CentralCache中申请内存。
ps:向CentralCache中申请内存过程中,使用类似TCP拥塞控制中的满开始算法。以达到申请内存的多少的合理性(即并不是单个单个内存申请,而是批量申请)。
释放内存
1、将不用的内存,通过内存大小,计算出其在ThreadCache中对应桶的位置,将其插入进去。
2、当ThreadCache中某个桶中挂的链表过长的时候,即链表长度大于一次批量申请的内存时,就将ThreadCache中对应桶中的内存回收给CentralCache.
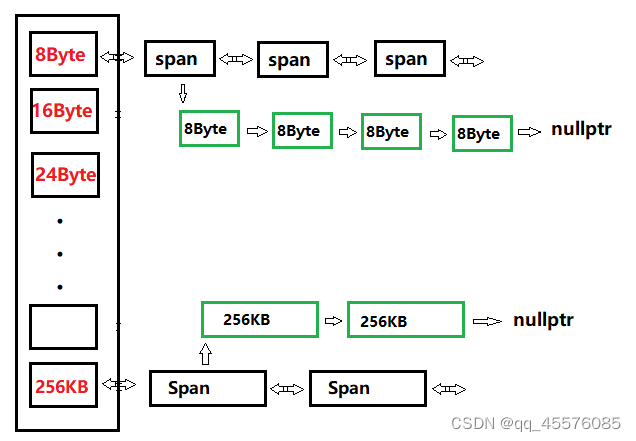
centralcache
centralcache设计也是一个hash结构,也是使用和threadcache的对齐规则。不同的是centralcache的每个hash桶挂着的是span对象,是一个双向链表。每个span中又切分了多个对应其对齐数的小内存对象,是一个单链表结构。
其次,从整个项目框架上看,多个ThreadCache内存不足或者需要释放内存的时候,都需要涉及到centralcache,因此centralcache最好设计称为单例模式,供多个threadcache访问。
申请内存
1、ThreadCache向CentralCache申请内存,首先获得从CentrlCache对应位置的hash桶中获得一个Span(此时需要加桶锁),在该Span中拿出ThreadCache申请的内存数(尽力而为)。
2、如果CentrlCache对应位置没有Span,则向PageCache中申请内存。将向PageCache中刚申请的内存进行切分成freelist_。
释放内存
1、回收ThreadCache中的freelist_链表过长的内存,首先得找到CentralCache中对应的hash位置
2、其次CentralCache得找到这个个回收回来得freelist_链表隶属于CentralCache对应hash位置下的哪一个span。
这里找到对应的span,使用了一个哈希结构,unordered_map<PAGE_ID, Span*>,在PageCache向CentralCache中分配内存的时候,就建立好了对应的映射关系了。
关于PAGE_ID的计算是这样的,(PAGE_ID)ptr >> PAGE_SHIFT,即将内存地址右移PAGE_SHIFT位。这样每一个内存地址都能找到自己的PAGE_ID。再通过映射关系找到自己所属的Span。
3、向对应hash位置下的对应span中依次挂入回收的链表,并且useCount对应减少。
4、当useCount减至0的时候,标志着该span中的所有小块内存都被回收回来了。就应该向PageCache中归还该span的内存了。
pagecache
pagecache的设计也是一个hash结构,采用的是直接定址法法映射。其每个hash桶下挂着的是以页为单位的对应其范围大小的span内存对象,是个双向链表结构。

这里的PageCache也设计称为单例模式。
申请内存
1、首先向满足CentralCache申请对应的桶中查看时候有span。有则交付一个span。
2、满足CentralCache申请对应的桶中没有span,就向后续桶中遍历查找存在内存的桶。
3、后续桶中的span必定比满足CentralCache申请对应的桶中的span大,需要在后续桶中的span切分满足CentralCache申请对应的桶中的大小,span剩下的内存则,按剩余内存大小映射插入到对应的hash桶中。
释放内存
1、回收来自CentralCache返还的span,进行合并页,缓解内碎片的问题。
2、向前合并,(1)前边没有页号了(2)前边的页号正在使用(3)合并后的页数超过128页,无法管理。则不合并。
3、向后合并,(1)前边没有页号了(2)前边的页号正在使用(3)合并后的页数超过128页,无法管理。则不合并。
内存池优化逻辑
大块内存的申请和释放
我们这里内存池的单个线程能申请的最大内存就是256KB,当线程申请的内存大于256KB的时候,便能是为是大块内存。
我们设计PageCache的时候,一页的大小定为的8K,当申请256KB的时候,就需要256KB/8KB=32个span。因此将Page Cache的哈希桶个数多弄几个,比如32*4=128个,即一个128页的span可以满足四个线程去申请256KB大小的内存。
当申请大块内存的时候,我们直接去向PageCache中去申请。
在PageCache中,当申请超过128页的大内存的时候,就直接向堆申请。
释放的过程相反即可。
释放大块内存的时候,直接向PageCache中归还。
在PageCache中,归还超过128页的内存时,直接归还给堆。
替代系统内存分配函数
我们的内存池是能替代系统提供的内存分配函数(malloc、free)的,因此我们不能在里边继续使用系统提供的内存分配函数。定长内存池便能达到使用内存分配的效果。
使用基数树优化
基数树,或称压缩前缀树,是一种更节省空间的Trie(前缀树)。对于基数树的每个节点,如果该节点是确定的子树的话,就和父节点合并。基数树可用来构建关联数组。
为什么要使用基数树优化呢?
在PageCache向CentralCache分配内存的时候,我们需要建立PageId和Span的映射关系,我们使用的是STL中unordered_map,其底层是使用的哈希表。关于哈希表有如下缺点不符我们内存池的使用:
1、哈希表的底层必定使用了系统内存分配相关函数
2、哈希表的底层使用数组实现的,数组大小不好确定,还涉及到扩容的问题(扩容就分为原地扩容和一定扩容)。
接下来就开始介绍基数树了!
单层基数树
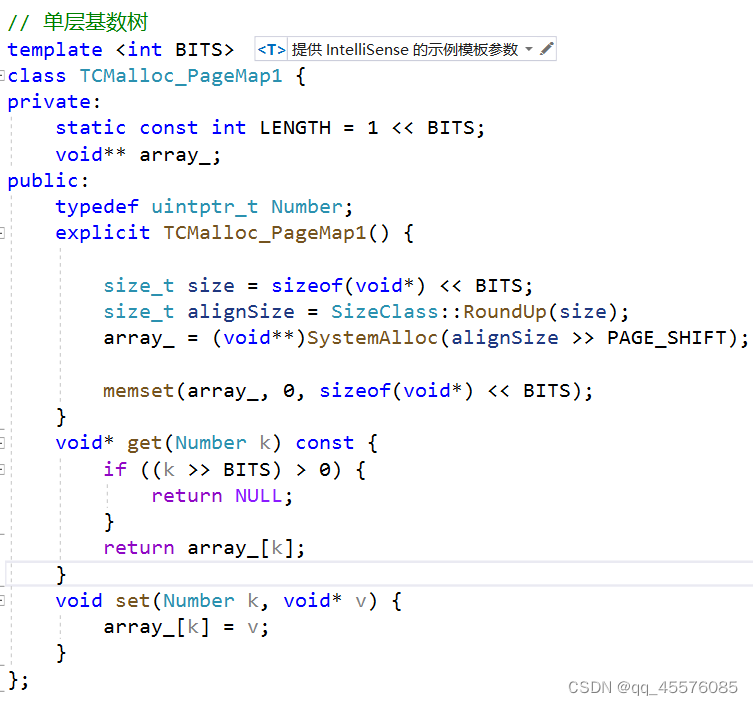
单层基数树就如同hash的直接定址法一样,其中的模板参数表示的是存储页号的位数。在32位环境下是32-PAGE_SHIFT,64位环境下是64-PAGE_SHIFT。我们的PAGE_SHIFT是2^13,也就是说BITES在32位环境下的值就是2^19位。占用的内存就是2^19*4=2^21=2M。
比如页号为多少,就在对应的void**的数组中找对应的位置,其位置存储的就是它Span的信息。

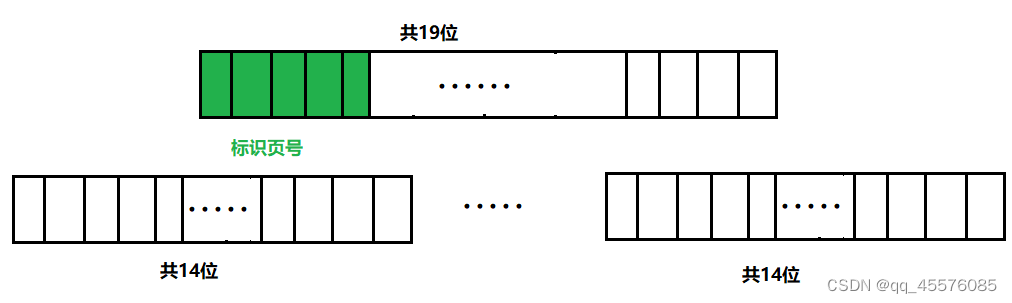
双层基数树

上边的双层基数树的模板参数含义和单层基数树一样,都代表存储页号需要多少位。
这里的双层基数树的前5位用于标识页号,能通过第一层对应位置中的内容找到第二层的数据,第二层的数组标识着Span的属性。32位环境下,二层基数树需要的大小是2^19*4=2^21=2M。
项目反思
项目不足
可能存在内存泄漏。在ThreadCache的回收逻辑里,当哈希桶下挂的freelist_过长的时候,才将freelist_向CentralCache中返还。当freelist_挂的内存不长的时候呢?比如说就只挂了一个小的内存对象,并不满足过长的条件,就不会向CentralCache里返还,就造成了内存泄漏的问题。
项目优势
1、ThreadCache使用了TLS技术,每个线程无锁获得自己独属的ThreadCache对象。
2、ThreadCache内存不足时向CentralCache申请时,并不是需要多少申请多少,而是批量申请,也就是说在向CentralCache申请依次后,Thread Cache就有了一批内存对象供本线程使用。即减少了ThreadCache向CentralCache申请的频次,而CentralCache的访问时会加锁的,这也将使CentralCache中的桶锁不会很激烈。
3、使用基数树优化,既可以代替底层使用new和delete,有可以利用基数树可以根据一个长整型(比如一个长ID)快速查找到其对应的对象指针,比hash映射来的简单和节省空间。