一、关于网站上面的那个教程:
适合PyTorch小白的官网教程:Learning PyTorch With Examples - 知乎 (zhihu.com)
这个链接也是一样的,
总的来说,里面讲了这么一件事:
如果没有pytorch的分装好的nn.module用来继承的话,需要设计一个神经网络就真的有很多需要处理的地方,明明可以用模板nn.module来继承得到自己的neural network的对象
然后,我们自己这个network里面设计我们想要实现的东西
[ Pytorch教程 ] 训练分类器 - pytorch中文网 (ptorch.com)
这个网站底部的链接还是有一些东西的
二、训练分类器中的代码-查漏补缺,加油!!
1.CIFAR-10中的图像大小为3x32x32,即尺寸为32x32像素的3通道彩色图像
2.torchvision.utils.make_grid()函数的参数意义和用法:


3.利用plt输出图像,必须是(h,w,channels)的顺序,所以从tensor过来需要permute或者transpose
def imshow(img): #定义这里的局部imshow
img = img / 2 + 0.5 # unnormalize,还是要回去的好吧,img=(img-0.5)/0.5这是均值normlize
npimg = img.numpy() #plt只能绘制numpy_array类型
plt.imshow(np.transpose(npimg, (1, 2, 0))) #好像必须进行permute或者transpose得到(h,w,channels)4.和f.max_pool2d是一个可以调用的函数对象,nn.MaxPool2d是一个模板,需要自己设置:
http://t.csdn.cn/mzqv7

5.torch.max(tensor,1)函数的用法:
http://t.csdn.cn/JMBwW
这篇文章讲得很好,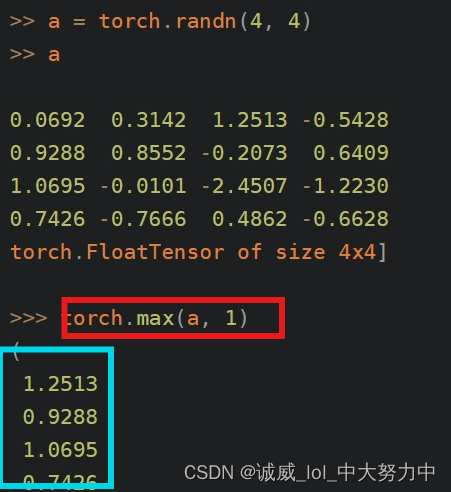
将每一行的最大值组成一个数组
二、代码研读+注释版:
#引入基本的库
import torch
import torchvision
import torchvision.transforms as transforms#利用DataLoader获取train_loader和test_loader
transform = transforms.Compose( #定义ToTensor 和 3个channel上面的(0.5,0.5)正太分布
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#获取trainset,需要经过transform处理
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, #设置train_loader参数:batch_size=4,shuffle
shuffle=True, num_workers=2) #这个num_woekers子进程不知道会不会报错
#同样的处理获取test_loader
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
#定义一个classes数组,其实是用来作为一个map映射使用的
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')#展示一些图像,来点直观的感受
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img): #定义这里的局部imshow
img = img / 2 + 0.5 # unnormalize,还是要回去的好吧,img=(img-0.5)/0.5这是均值normlize
npimg = img.numpy() #plt只能绘制numpy_array类型
plt.imshow(np.transpose(npimg, (1, 2, 0))) #好像必须进行permute或者transpose得到(h,w,channels)
# get some random training images
dataiter = iter(trainloader) #dataiter就是迭代器了
images, labels = next(dataiter) #获取第一个images图像数据 和 labels标签 ,注意iter.next()已经改为了next(iter)
# show images
imshow(torchvision.utils.make_grid(images)) #以网格的方式显示图像
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4))) #输出labels1-4这样的标题#定义neural network的结构
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) #定义输入channel=3,输出channel=5,卷积核5*5,stride(default)=1,padding(default)=0
self.pool = nn.MaxPool2d(2, 2) #定义pooling池化,kernel_size=2*2,stride 右2,且下2
self.conv2 = nn.Conv2d(6, 16, 5) #同上输出channel=16
self.fc1 = nn.Linear(16 * 5 * 5, 120) #下面定义了3个Linear函数
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) #conv1->relu->pooling
x = self.pool(F.relu(self.conv2(x))) #conv2->relu->pooling
x = x.view(-1, 16 * 5 * 5) #调整为第二维数16*5*5的大小的tensor
x = F.relu(self.fc1(x)) #fc1->relu
x = F.relu(self.fc2(x)) #fc2->relu
x = self.fc3(x) #output_linear->得到一个10维度的向量
return x
net = Net() #创建一个net对象#定义loss_func和optimizer优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss() #分类的话,使用nn.CrossEntropyLoss()更好
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) #这里使用初级的SGD#开始train多少个epoch了:
for epoch in range(2): # 0-1总共2个epoch
running_loss = 0.0 #记录loss数值
for i, data in enumerate(trainloader, 0): #利用迭代器获取索引和此次batch数据,0代表从第0个索引的batch开始
# get the inputs
inputs, labels = data #获取inputs图像数据batch 和 labels标签batch
# wrap them in Variable
#inputs, labels = Variable(inputs), Variable(labels) ,在新版的pytorch中这一行代码已经不需要了
# zero the parameter gradients
optimizer.zero_grad() #每次进行backward方向传播计算gradient之前先调用optimizer.zero_grad()清空,防止积累
# forward + backward + optimize ,标准操作:model + criterion + backward + step
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics ,每2000个batch进行对应的输出
#running_loss += loss.data[0] #将这次batch计算的loss加到running_loss厚葬 ,新版的pytorch中tensor.data弃用
#改用tensor.item()了
running_loss = loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000)) #输出:第几个epoch,第几个batch,平均每个batch的loss
running_loss = 0.0 #归零
print('Finished Training')#展示第一批
dataiter = iter(testloader)
images, labels = next(dataiter) #获取一个batch(上面设置了batch_size=4)的images图像数据 和 labels标签
# print images
imshow(torchvision.utils.make_grid(images)) #通过网格形式
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))#使用上述的model对第一批进行预测
outputs = net(Variable(images))
#predicted = outputs.data.max(2,keepdim= True)[1] #这样就获得了一个数组
_, predicted = torch.max(outputs.data, 1)
#注意,classes是一个数组,不过是当作map映射使用的
for j in range(4):
print(classes[predicted[j]])
#正式开始test了
correct = 0 #正确的数目
total = 0 #总共测试数目
for data in testloader: #每次获取testloader中的1个batch
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1) #得到预测的结果数组
total += labels.size(0)
correct += (predicted == labels).sum() #predicted数组和labels数组逐项比较
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total)) #输出正确率
#对这10种不同的物体对象的检测正确率进行分析:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze() #c就是1个1维向量
for i in range(4): #一个batch有4张图
label = labels[i] #label就是0-9中那个类的index
class_correct[label] += c[i] #如果c[i]==True就让class_correct+1
class_total[label] += 1 #改类图的数目+1
for i in range(10): #输出每个类的正确率
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))