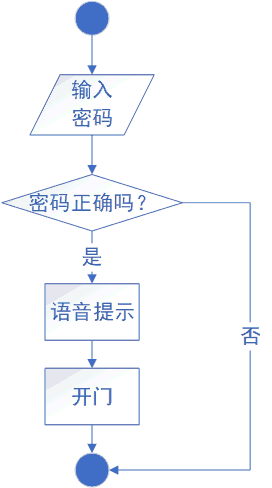
在进行神经网络的训练过程中,会生成不同的特征图信息,这些特征图中包含大量图像信息,如轮廓信息,细节信息等,然而,我们一般只获取最终的输出结果,至于中间的特征图则很少关注。
前两天师弟突然问起了这个问题,但我也没有头绪,后来和师弟研究了一下,大概有了一个思路。
即每个特征提取模块都会输出一个特征图,这些特征图的每个像素实际上就是一些数值,那么只需要将这些数值保存,再以图像的形式展现出来便OK了。
基于这个思路,我们来进行设计。在观测输出的特征图时,我们可以使用推理代码来进行输出,因为推理时所消耗的资源较少且推理时可以很明确我们输入的图像是什么。
至于要想实现的效果:
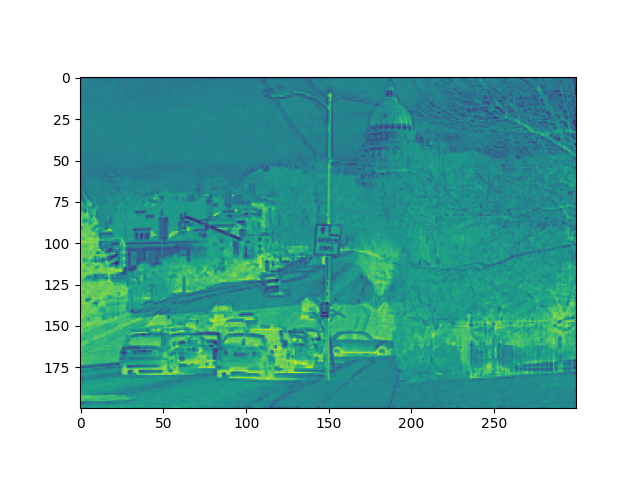
原图:
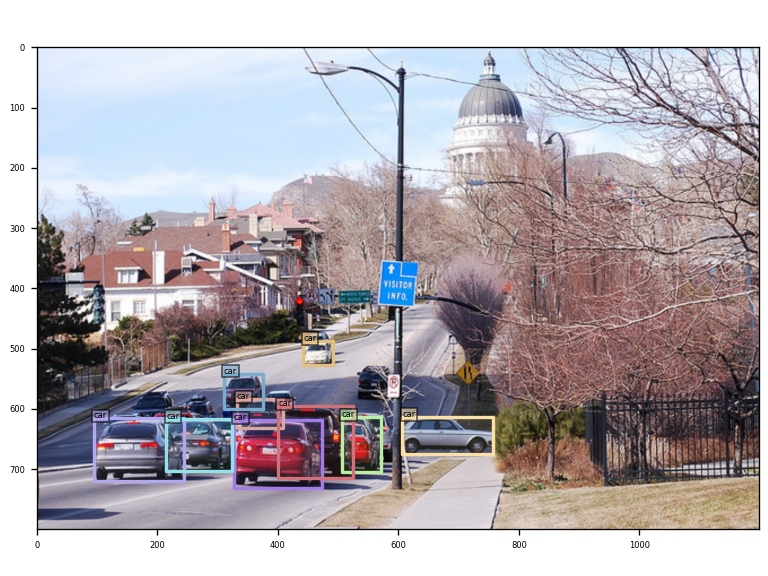
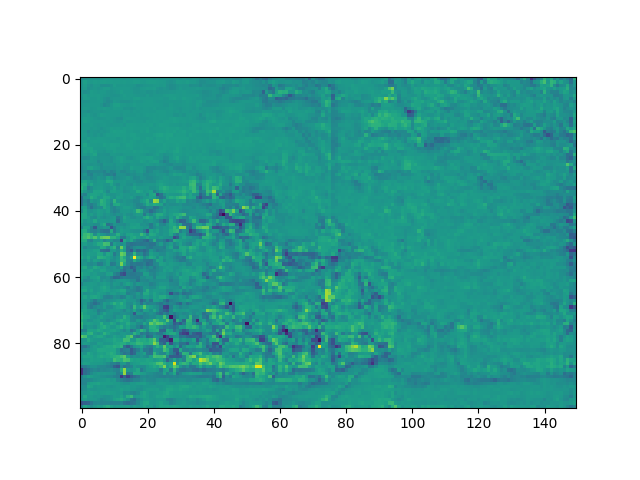
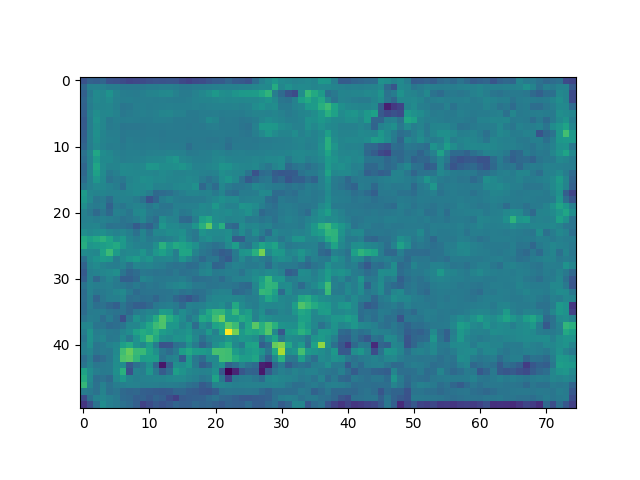
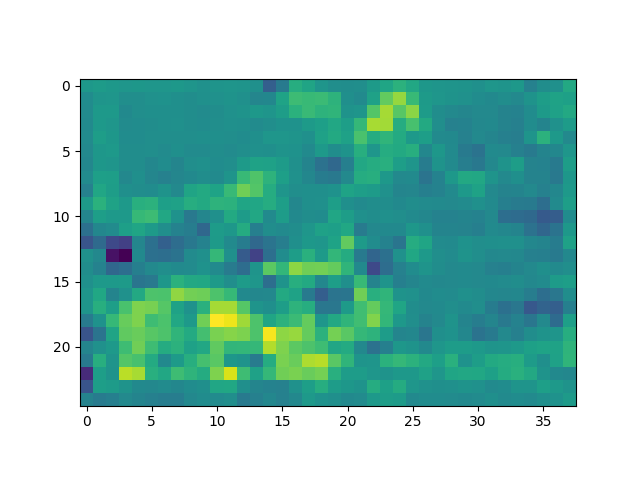
输出的特征图:
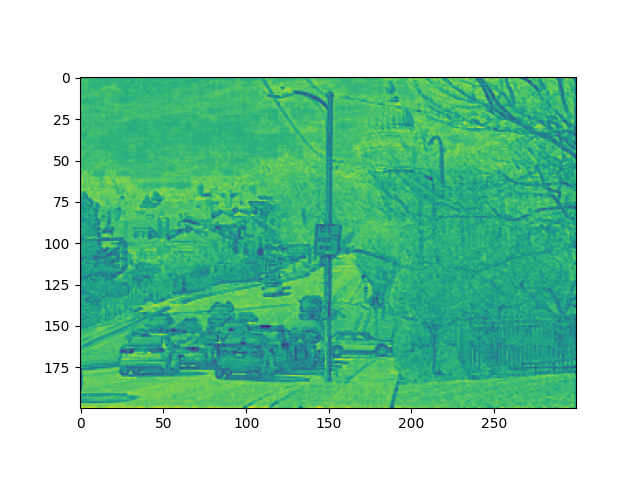
那么该如何进行呢?
首先是要明确你要输出哪个阶段的特征图像,博主分别选择了主干网络四个阶段的输出结果,输出的特征图大小分别为:
x的shape: torch.Size([1, 64, 200, 300])
x的shape: torch.Size([1, 128, 100, 150])
x的shape: torch.Size([1, 320, 50, 75])
x的shape: torch.Size([1, 512, 25, 38])
代码实现
在要输出特征图的模块后面讲特征图保存为numpy的格式:
sb = x.cpu().data.numpy()
np.save('matric'+str(i)+'.npy', sb)#这里的i是对应四个阶段的id
读取numpy格式数据并转换为特征图:
import numpy as np
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
def normalization(data): # NORMALIZE TO [0,1]
_range = np.max(data) - np.min(data)
data = (data - np.min(data)) / _range # [0,1]
return data
def fm_vis(feats, save_dir, save_name):
save_dir = os.path.join(save_dir, save_name)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
feats = normalization(feats[0].cpu().data.numpy())
for idx in range(min(feats.shape[0], 200*300)): # CHANNLE NUMBER
fms = feats[idx, :, :]
plt.imshow(fms)
plt.savefig(os.path.join(save_dir, save_name + '_' + str(idx) + ".png"))
for i in range(0,4):
s_b1 = np.load('matric'+str(i)+'.npy')
print(s_b1)
s_b2 = torch.from_numpy(s_b1)
out_dir = "outputs"
s_b = s_b2.reshape(1, 64, 200, 300)
fm_vis(s_b, out_dir, "s_b_vis"+str(i))
最终结果:输出四个阶段的特征图,博主选了其中几张: