社区有言Talk is cheep, show me the code,我们尽量低纬度描述技术。
代码和版本:
Qemu-5.0 #热迁移技术的实现者
Kernel-4.19 #提供kvm实现
热迁移的演进
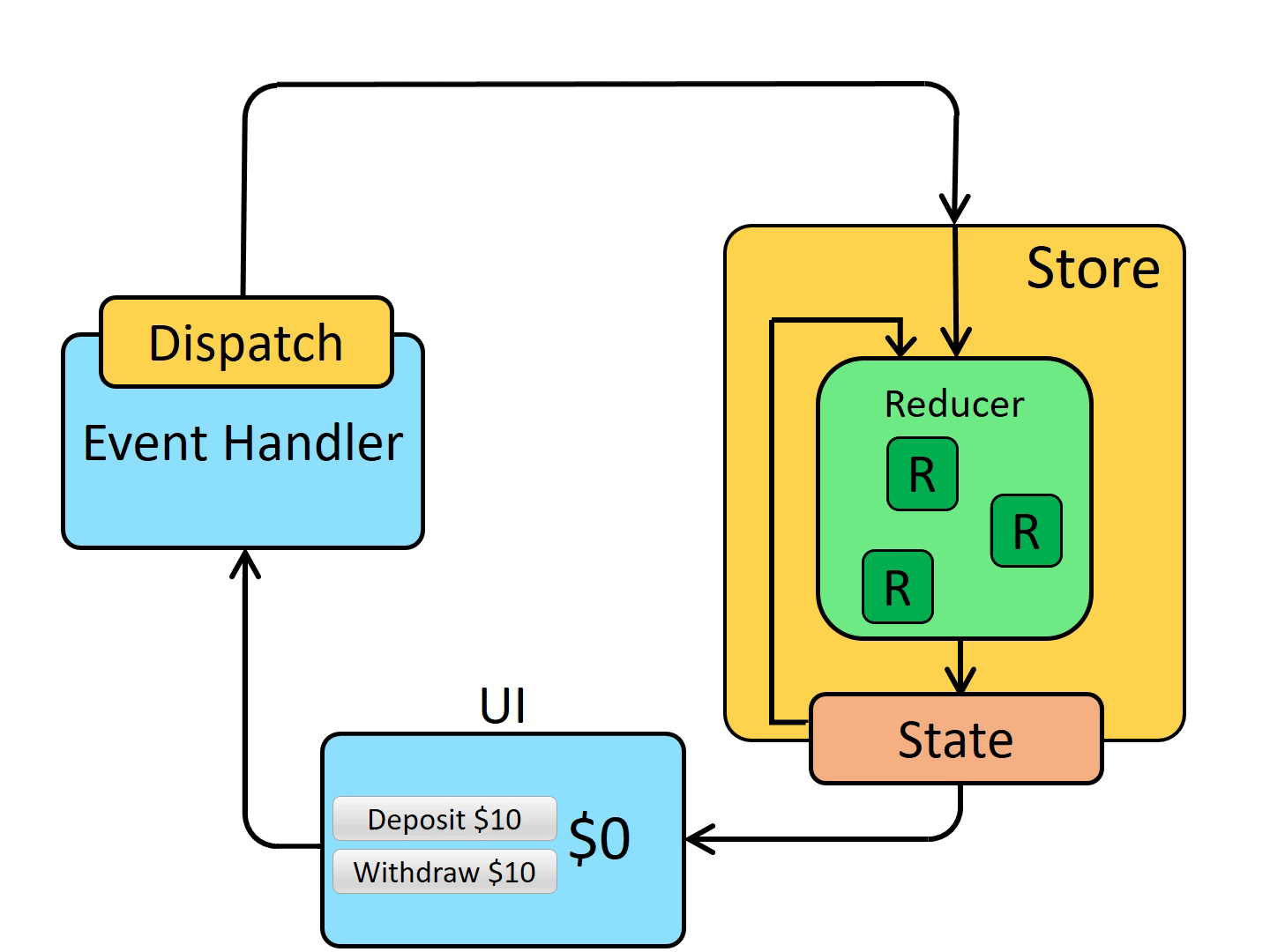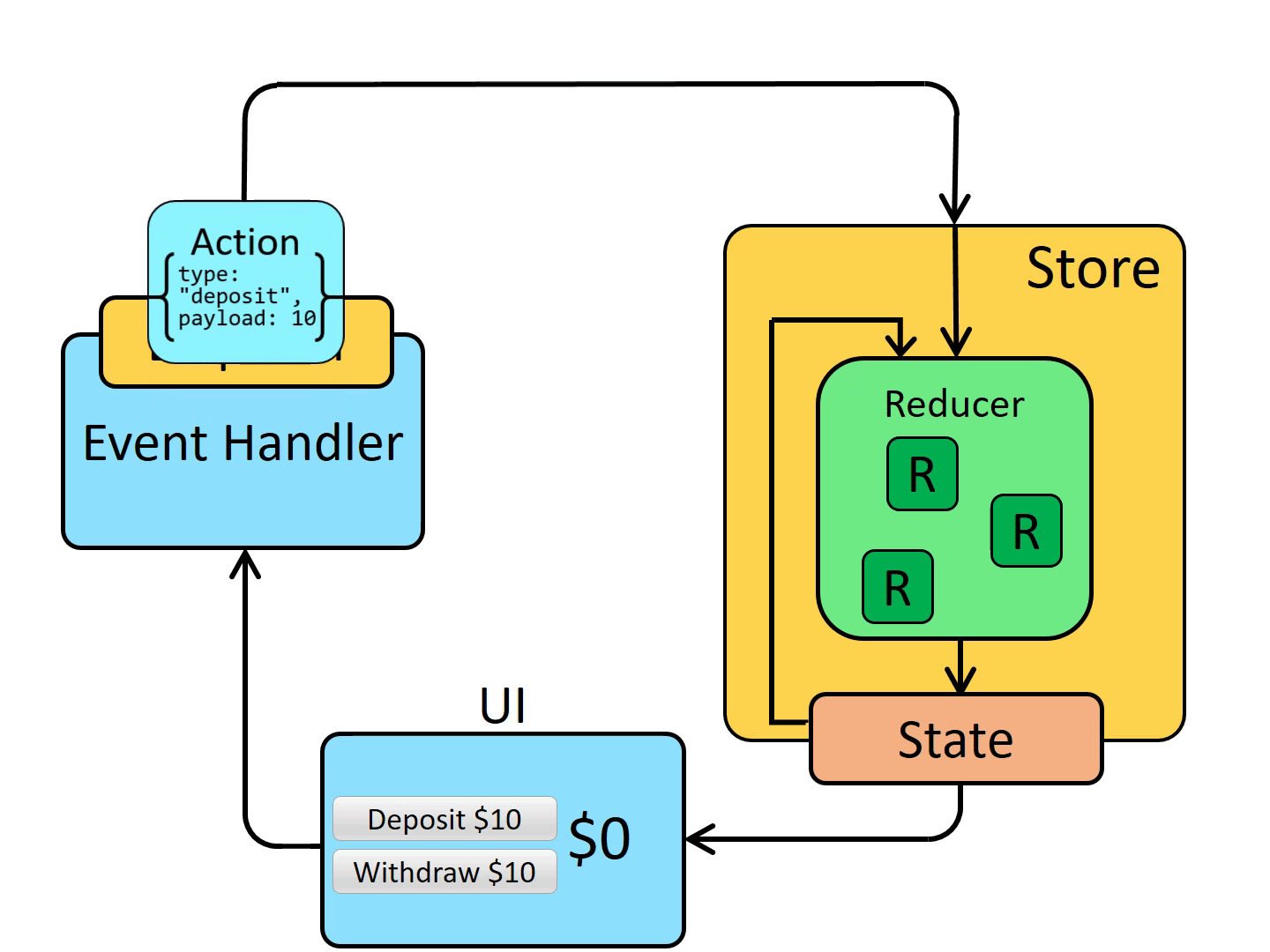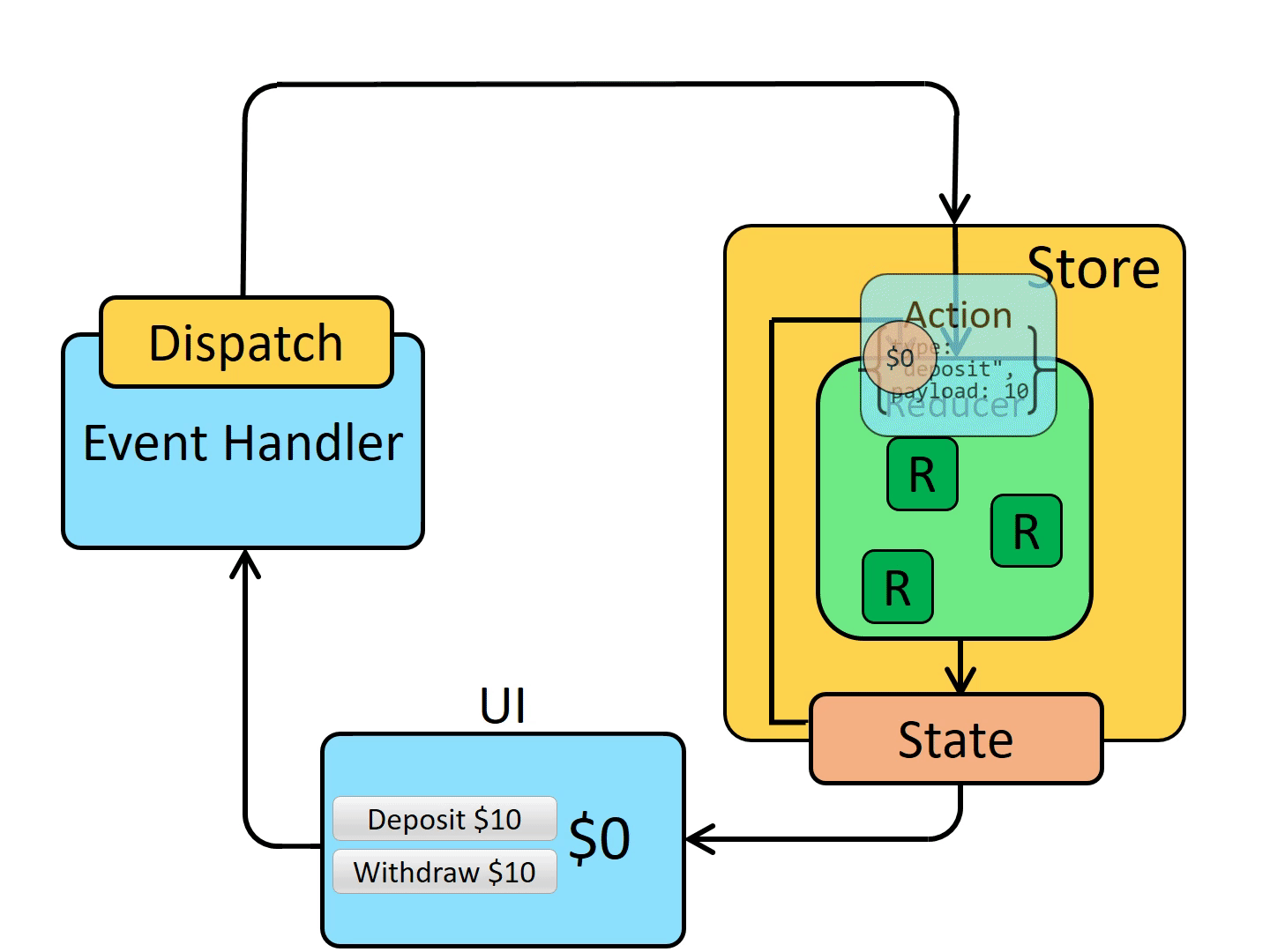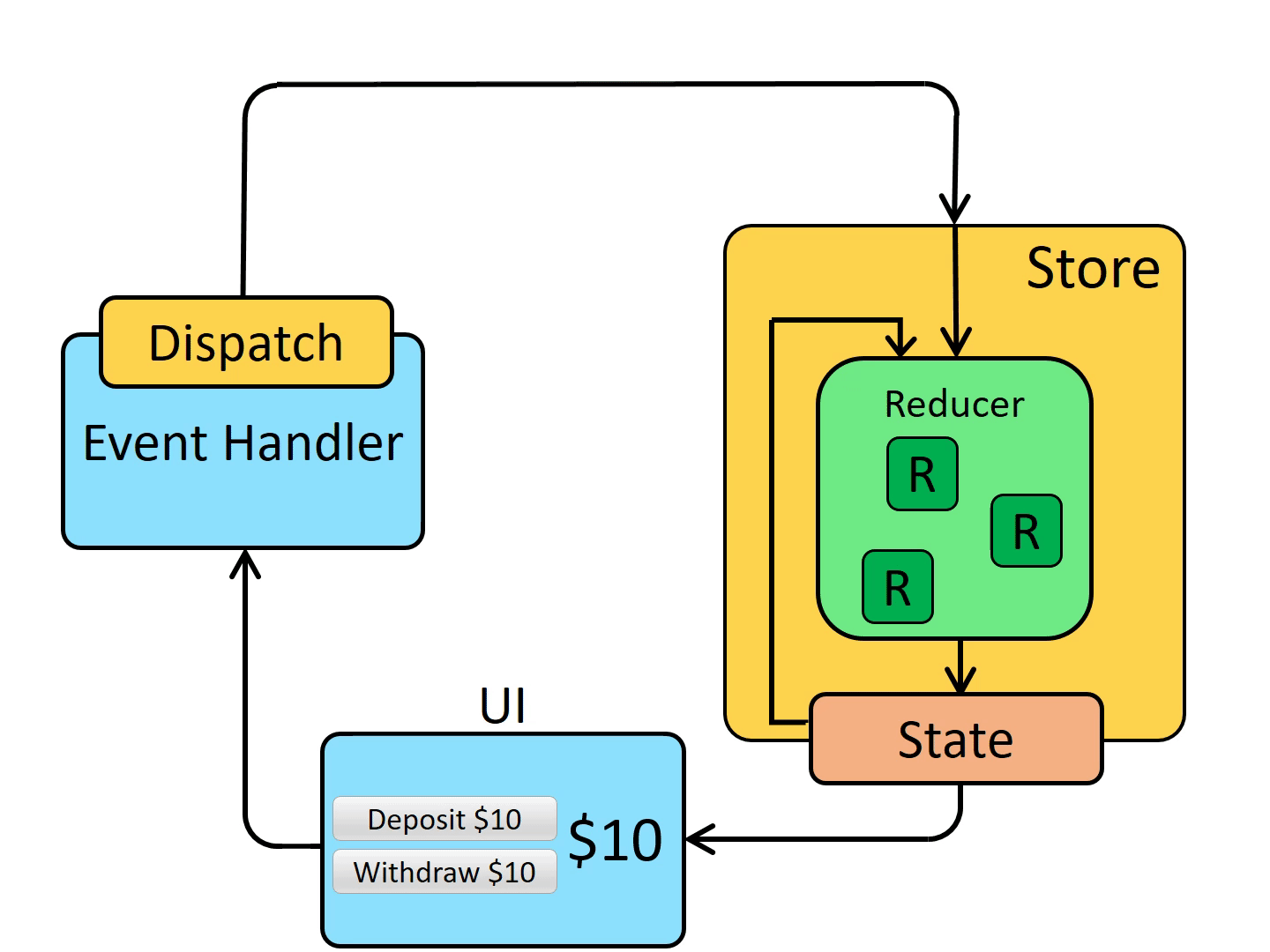
Qemu有加载保存vm的功能,这是两个互补的操作。保存状态就是为每个vm中运行的设备保存状态,恢复vm就是相反的操作。
为了实现这个功能,这个过程qemu用相同的参数启动两次,在一个vm恢复状态,这个vm与保存的设备相同(也可以支持部分不同)。
一旦我们能够保存恢复(快照)vm,新功能也有支持的基础:迁移。Qemu能够在一个物理机迁移到另一台物理机。
接下来就是实时迁移功能。因为vm有很多运行状态(特别是RAM),而且它可能需要一段时间才能把所有状态从一台物理机迁移到另一台物理机。热迁移允许vm在状态迁移时继续运行,直到最后一部分状态传输时停止。Vm无响应的典型时间在几百毫秒以内。Downtime取决于多个因素,如带宽,vm产生脏页的速度,迁移内存水线,硬件性能。
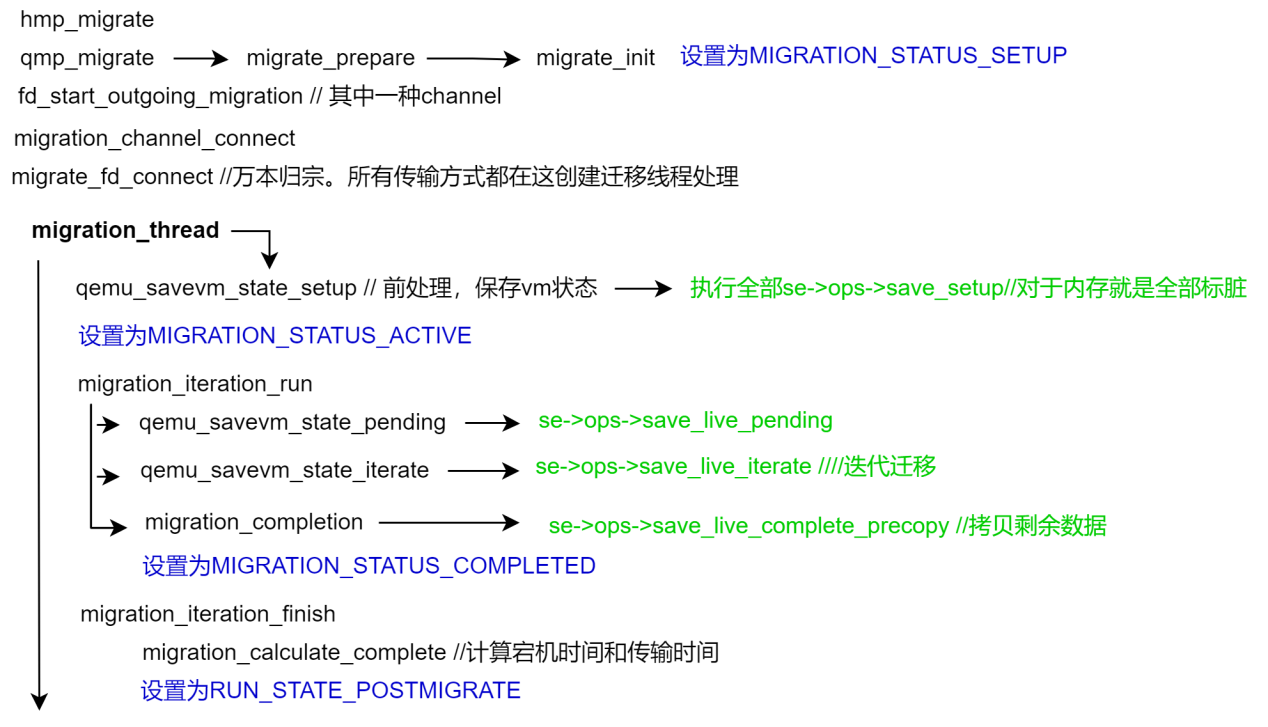
Qemu热迁移模型
- 热迁移过程
Qemu热迁移过程
- 标记所有内存为脏页,首次迁移拷贝所有内存
- 迭代迁移新的脏页,直到降低到一定水线,可以一次性迁移过去。
- 暂停vm,一次性迁移剩余脏页,然后迁移设备状态,启动目的端虚拟机。
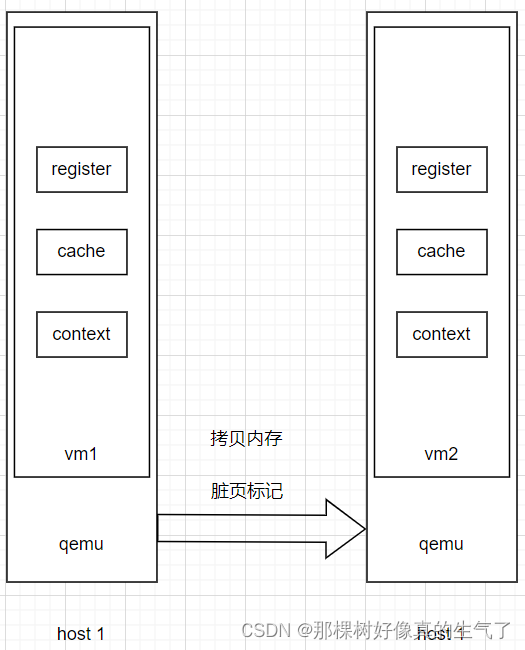
从Qemu monitor或者libvirt的domain unix socket消息触发热迁移,源端进程执行precopy,对vm堆栈、内存进行备份用于异常恢复,创建传输通道,迁移过程中dirty page bitmap(用于标识vm里内存动态变化的部分)通过copy、send、recv、restore,在源和目的qemu进程间交互。
传输channel:
Fd 虚拟文件,进程间通信,Fd常用。
tcp socket网络
Rdma 网络
unix socket 进程间通信
exec stdin|sdout 进程间通信
这些可以承载迁移流的文件被抽象成QEMUFile类型(migration/qemu-file.h),在大多数情况会连接到一个子类型QIOChannel(io/)

一个独立的线程作为迁移的执行者和入口,实现迁移功能
se就是savevm_state的链表节点,
typedef struct SaveStateEntry {
QTAILQ_ENTRY(SaveStateEntry) entry;
char idstr[256];
uint32_t instance_id;
int alias_id;
int version_id;
/* version id read from the stream */
int load_version_id;
int section_id;
/* section id read from the stream */
int load_section_id;
const SaveVMHandlers *ops; ==== 迭代设备必须实现的回调函数
const VMStateDescription *vmsd; === 非迭代设备数据结构
void *opaque;
CompatEntry *compat;
int is_ram;
} SaveStateEntry;
QTAILQ_HEAD_INITIALIZER(savevm_state.handlers)
迁移核心代码是公共设施,各个设备实现自己的数据结构和回调,对于迁移的所有对象我们都描述为设备,要迁移的不同设备,保存在一个链表(savevm_state)。迭代设备注册SaveVMHandlers 类型,非迭代设备注册VMStateDescription。
- 迁移数据结构
VMState 宏(为了方便描述代指---》VMStateDescription数据结构)
hw/input/pckbd.c
static const VMStateDescription vmstate_kbd = {
.name = "pckbd",
.version_id = 3,
.minimum_version_id = 3,
.fields = (VMStateField[]) { ========== 保存设备寄存器值
VMSTATE_UINT8(write_cmd, KBDState),
VMSTATE_UINT8(status, KBDState),
VMSTATE_UINT8(mode, KBDState),
VMSTATE_UINT8(pending, KBDState),
VMSTATE_END_OF_LIST()
}};
vmstate_register(NULL, 0, &vmstate_kbd, s); ===== 设备状态结构注册到链表se
----》 dc->vmsd = &vmstate_kbd_isa; ====== 如果是qdev类型的,可以直接在类里注册
一个设备简单的保持和加载是不够的,我们要保证它的正确性。例如:在保存CPU前,要求KVM把当前状态复制到QEMU,
在加载时,需要一种方法告诉KVM我们要从QEMUFile加载CPU状态。
要执行的操作函数位于vmstate
int (*pre_load)(void *opaque);
int (*post_load)(void *opaque, int version_id);
int (*pre_save)(void *opaque);
int (*post_save)(void *opaque);
VMState宏可以保证设备数据可移植格式化(大端字节序),可以嵌套VMStateDescriptions 子结构
嵌套的子设备状态结构,用于添加新数据。虽然也是一个完整的vmstate结构,特殊性在于可以控制是否发送。
在接收端,如果发现一个解析不了的子VMState,就迁移失败。
static bool ide_drive_pio_state_needed(void *opaque){
IDEState *s = opaque;
return ((s->status & DRQ_STAT) != 0) || (s->bus->error_status & BM_STATUS_PIO_RETRY);}
const VMStateDescription vmstate_ide_drive_pio_state = {
.name = "ide_drive/pio_state",
.version_id = 1,
.minimum_version_id = 1,
.pre_save = ide_drive_pio_pre_save,
.post_load = ide_drive_pio_post_load,
.needed = ide_drive_pio_state_needed,
.fields = (VMStateField[]) {
VMSTATE_INT32(req_nb_sectors, IDEState),
VMSTATE_VARRAY_INT32(io_buffer, IDEState, io_buffer_total_len, 1,
vmstate_info_uint8, uint8_t),
VMSTATE_INT32(cur_io_buffer_offset, IDEState),
VMSTATE_INT32(cur_io_buffer_len, IDEState),
VMSTATE_UINT8(end_transfer_fn_idx, IDEState),
VMSTATE_INT32(elementary_transfer_size, IDEState),
VMSTATE_INT32(packet_transfer_size, IDEState),
VMSTATE_END_OF_LIST()
}};
const VMStateDescription vmstate_ide_drive = {
.name = "ide_drive",
.version_id = 3,
.minimum_version_id = 0,
.post_load = ide_drive_post_load,
.fields = (VMStateField[]) {
.... several fields ....
VMSTATE_END_OF_LIST()
},
.subsections = (const VMStateDescription*[]) {
&vmstate_ide_drive_pio_state,
NULL
}};
例如这个pio的状态sectio,在保存/发送的时候检测DRQ_STAT。如果未启用说明这个子设备状态不需要发送。
有时不需要某个字段,保持兼容的做法是,用添加新的子设备状态或者使用_TEST宏,如 VMSTATE_UINT32 -> VMSTATE_UINT32_TEST
迭代设备迁移一般不用VMState宏,而是用SaveVMHandlers,并用qemu_put_*/qemu_get_*宏把数据读写到IO流。
迭代设备必须提供SaveVMHandlers:
- int (*save_setup)(QEMUFile *f, void *opaque);
- int (*load_setup)(QEMUFile *f, void *opaque);
- void (*save_live_pending)(QEMUFile *f, void *opaque,----》指示还有多少必须保存的数据,用来确定何时停CPU完成迁移
uint64_t threshold_size,
uint64_t *res_precopy_only, //用于在预拷贝阶段或停止状态下必须迁移的数据,即在目标虚拟机启动之前
uint64_t *res_compatible, //用于在任何阶段都可能迁移的数据
uint64_t *res_postcopy_only); //用于在postcopy阶段或停止状态(即源虚拟机停止后)必须迁移的数据
//这三类加起来就是要拷贝的数据总量
- int (*save_live_iterate)(QEMUFile *f, void *opaque); ====迭代迁移函数,在pending调用后调用,每次生成、发送一个数据块。
- int (*save_live_complete_precopy)(QEMUFile *f, void *opaque); //剩余可以一次性迁移的最后一部分数据
- LoadStateHandler *load_state;
- int (*load_cleanup)(void *opaque);
像CPU设备,要支持对vmstate填充正确的值,例如,当使用KVM时,在保存CPU状态之前,要求KVM将它正在使用的状态复制到QEMU,相反,加载恢复时,需要一个方法告诉KVM加载我们刚刚从QEMUfile加载的CPU状态
函数回调定义在vmstate结构中:
Example: hpet.c
当迁移数据和保存的设备数据不一致,用VMSTATE_WITH_TMP 填充到临时结构传输。
如果使用在初始化之外使用内存api更新内存,例如响应vm。在post_load调用回调示例
- memory_region_add_subregion()
- memory_region_del_subregion()
- memory_region_set_readonly()
- memory_region_set_nonvolatile()
- memory_region_set_enabled()
- memory_region_set_address()
- memory_region_set_alias_offset()
///注册迭代设备方法到链表
int register_savevm_live(const char *idstr, // 标识设备
int instance_id, //标识vm
int version_id, //标识设备版本,兼容性控制
SaveVMHandlers *ops, //保存和加载用的函数指针
void *opaque); //函数指针的参数
每个设备必须注册两个函数,一个用于保存,一个用于加载回去。
这个函数在SaveVMHandlers*参数是save_state和load_state功能,load_state根据version_id参数判断接收的什么状态格式,save_state没有version_id,因为它永远使用最新版本。VMstate宏把数据保存为raw格式,这个结构可以用构造数据替换。
根据数据是否变化可以分为两类,一种是数据量大,并且不断变化的数据,例如内存、支持热迁的存储。需要注册SaveVMHandlers。
一种是qemu本身相关,不会变化的设备状态,而且能在迁移最后阶段完成的,如大多数设备。这类模块注册VMStateDescriotion结构并保存在迁移链表SaveStateEntry节点的vmsd成员。
设备加载有时候有依赖关系,比如pci设备必须在pci bus加载后加载,我们需要优先级控制加载顺序,在VMStateDescription 中MigrationPriority枚举结构指示这个level。
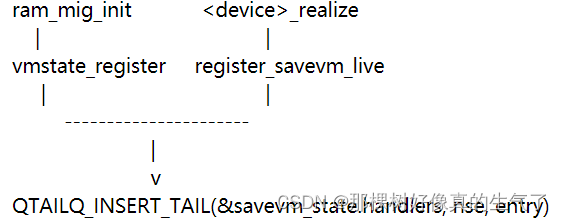
迭代设备和非迭代设备,都会在初始化的时候构造SaveStateEntry添加到 savevm_state.handlers链表上。
传统方式
内存迁移
像内存一样需要迭代迁移的设备必须提供方法:
- ``save_setup``函数初始化数据结构和发送设备的第一个section,对于RAM就是内存块和大小.-->保存
- ``load_setup``初始化目的端
- ``save_live_pending`` 反复调用的函数必须指出需要迭代保存的数据量。迁移的核心代码需要根据它确定什么时候暂停cpu,完成迁移。
- ``save_live_iterate``在 ``save_live_pending``后,仍有重要数据要发送时调用。它应该发送一个数据块,直到流带宽限制告诉它停止。每个调用生成一个section。
- ``save_live_complete_precopy`` 传输包含所有剩余的数据的最后一个section
- ``load_state`` 用于加载所有保存方法生成的sections
- ``cleanup`` 在迁移结束时,用于保存和加载-->恢复
ram_save_setup过程是初始化热迁移相关的数据,计算vm总的内存大小,并写入QEMUFile,然后将ram_list的 所有block发送,用RAM_SAVE_FLAG_EOS作为数据分割标识
热迁移第一阶段初始化,为内存分配脏页标记的bitmap、开启脏页记录、把所有ramblock写入迁移流
ram_save_setup
ram_init_bitmaps--分配一个全局的bitmap标识page是否为脏页
bitmap_set 设置所有页为脏
memory_global_dirty_log_start 设置全局变量global_dirty_tracking标识开始脏页标记
MEMORY_LISTENER_CALL_GLOBAL(log_global_start, Forward) 然后调用回调log_global通知感兴趣的模块开始脏页标记
memory_region_transaction_commit将内存变化告诉KVM,kvm在ioctl(KVM_SET_USER_MEMORY_REGION)中
加上KVM_MEM_LOG_DIRTY_PAGES标记,kvm把vm内存设为写保护或者用硬件PML记录脏页。
热迁移第二阶段迭代迁移
ram_save_pending,同步kvm脏页,确定好当前脏页数量,然后用ram_save_iterate发送脏页,每一轮迭代完migration_rate_limit计算阈值max_size
ram_save_pending(QEMUFile *f, void *opaque, uint64_t max_size, //当前带宽和downtime下的最大发送量
uint64_t *res_precopy_only,
uint64_t *res_compatible,
uint64_t *res_postcopy_only)
migration_bitmap_sync_precopy 如果小于max_size,从KVM同步脏页信息。
*res_precopy_only += remaining_size 如果大于max_size,说明脏页数比较多,计算出脏页数即可
最大发送量在migration_thread中计算出来:
migration_rate_limit
current_bytes = qemu_ftell(s->to_dst_file) + ram_counters.multifd_bytes;
transferred = current_bytes - s->iteration_initial_bytes;
time_spent = current_time - s->iteration_start_time;
bandwidth = (double)transferred / time_spent;
s->threshold_size = bandwidth * s->parameters.downtime_limit;
int qemu_savevm_state_iterate(QEMUFile *f, bool postcopy)
{
SaveStateEntry *se;
QTAILQ_FOREACH(se, &savevm_state.handlers, entry) {
save_section_header(f, se, QEMU_VM_SECTION_PART);设置数据段头标标识
ret = se->ops->save_live_iterate(f, se->opaque); ====》ram_save_iterate
save_section_footer(f, se); 设置数据尾分割标识
}
}
ram_save_iterate 循环发送脏页
pages = ram_find_and_save_block(rs); 找到并发送脏页
find_dirty_block 找到下一个脏页
ram_save_host_page 发送
ram_save_page
qemu_put_buffer
如果执行时间大于MAX_WAIT( == 50ms)退出循环,因为获取时间比较费时,所以迭代64次检查一下
结束时设置RAM_SAVE_FLAG_EOS分割标识
热迁移第三阶段停机迁移,当要迁移量小于阈值,停止虚拟机,进行最后的脏页同步和发送,然后调用各个设备注册的回调发送设备状态
migration_completion
vm_stop_force_state(RUN_STATE_FINISH_MIGRATE)停虚拟机,并改运行状态
qemu_savevm_state_complete_precopy
qemu_savevm_state_complete_precopy_iterable
save_section_header(f, se, QEMU_VM_SECTION_END);
se->ops->save_live_complete_precopy ===》ram_save_complete
save_section_footer(f, se);
qemu_savevm_state_complete_precopy_non_iterable
save_section_header(f, se, QEMU_VM_SECTION_FULL);
vmstate_save(f, se, vmdesc);
vmstate_save_state_v 保存vmstate到json,然后发出去
vmsd->pre_save(opaque)
vmstate_save
vmstate_subsection_save(f, vmsd, opaque, vmdesc)
vmsd->post_save(opaque)
save_section_footer(f, se)
ram_save_complete
migration_bitmap_sync_precopy 获取KVM侧脏页
pages = ram_find_and_save_block(rs); 找到并发送脏页
find_dirty_block 找到下一个脏页
flush_compressed_data 发送
ram_save_page
qemu_put_buffer
结束时设置RAM_SAVE_FLAG_EOS分割标识
迁移结束之后计算时间
migration_iteration_finish
可以通过api获取downtime
脏页同步过程
1、QEMU为所有内存分配脏页位图全部设置为1。ram_list_init_bitmaps,保存在RAMBlock->bmap
2、QEMU通过ioctl(KVM_SET_USER_MEMORY_REGION)与新虚拟机的内存布局,将内存flags加上KVM_MEM_LOG_DIRTY_PAGES标识,KVM据此可以记录虚拟机内存的写访问
3、热迁移开始,热迁移线程从RAMBlock的bmap成员中选择脏页发送到目的端,虚拟机可以自由访问内存,其中的写内存会被KVM记录下来。
4、QEMU记录的脏页数据已经发送到只剩最后的max_size的时候,调用migration_bitmap_sync进行脏页同步,该函数最终会调用到
ioctl(KVM_GET_DIRTY_LOG)将KVM的脏页记录获取保存到ram_list.dirty_memory中(通过函数kvm_log_sync完成),然后将
ram_list.dirty_memory的脏页信息复制到RAMBlock的bmap成
员中。
5、如果脏页数据大于max_size,则进入第3)步开始迭代发送的过程
全局变量ram_list的dirty_memory成员用来记录虚拟机的内存脏页,由于可能有多个地方使用这个脏页,所以这个成员是一个数组,可以记
录DIRTY_MEMORY_VGA、DIRTY_MEMORY_CODE、DIRTY_MEMORY_MIGRATION三种脏页,其中
DIRTY_MEMORY_CODE用于tcg,DIRTY_MEMORY_MIGRATION用于热迁移。
typedef struct {
struct rcu_head rcu;
unsigned long *blocks[];
} DirtyMemoryBlocks;
typedef struct RAMList {
QemuMutex mutex;
RAMBlock *mru_block;
/* RCU-enabled, writes protected by the ramlist lock. */
QLIST_HEAD(, RAMBlock) blocks;
DirtyMemoryBlocks *dirty_memory[DIRTY_MEMORY_NUM];
uint32_t version;
QLIST_HEAD(, RAMBlockNotifier) ramblock_notifiers;
} RAMList;
extern RAMList ram_list;
分配空间
static void dirty_memory_extend(ram_addr_t old_ram_size,
ram_addr_t new_ram_size)
{
ram_addr_t old_num_blocks = DIV_ROUND_UP(old_ram_size,
DIRTY_MEMORY_BLOCK_SIZE);
ram_addr_t new_num_blocks = DIV_ROUND_UP(new_ram_size,
DIRTY_MEMORY_BLOCK_SIZE);
int i;
/* Only need to extend if block count increased */
if (new_num_blocks <= old_num_blocks) {
return;
}
for (i = 0; i < DIRTY_MEMORY_NUM; i++) {
DirtyMemoryBlocks *old_blocks;
DirtyMemoryBlocks *new_blocks;
int j;
old_blocks = qatomic_rcu_read(&ram_list.dirty_memory[i]);
new_blocks = g_malloc(sizeof(*new_blocks) +
sizeof(new_blocks->blocks[0]) * new_num_blocks);
if (old_num_blocks) {
memcpy(new_blocks->blocks, old_blocks->blocks,
old_num_blocks * sizeof(old_blocks->blocks[0]));
}
for (j = old_num_blocks; j < new_num_blocks; j++) {
new_blocks->blocks[j] = bitmap_new(DIRTY_MEMORY_BLOCK_SIZE);
}
qatomic_rcu_set(&ram_list.dirty_memory[i], new_blocks);
if (old_blocks) {
g_free_rcu(old_blocks, rcu);
}
}
}
dirty_memory_extend函数首先计算总共需要多少个block,block个 数为RAM的大小除以DIRTY_MEMORY_BLOCK_SIZE,如果本次内存 小于等于上次,说明不需要扩展,直接返回,否则需要扩展。 接着为3种脏页记录类型分配空间,i表示当前处理的类型。在替换 老的DirtyMemoryBlocks时使用了RCU机制,首先获取 ram_list.dirty_memory[i],分配新的DirtyMemoryBlocks空间,并将老的 脏页数据复制到新分配的空间中,然后分配新DirtyMemoryBlocks的 blocks数组,每一个block大小为DIRTY_MEMORY_BLOCK_SIZE,最 后将ram_list.dirty_memory[i]替换成新分配的,并删掉老的 DirtyMemoryBlocks。
析KVM的脏页是如何同步到ram_list.memory[i]中的脏页位图?
migration_bitmap_sync
memory_global_dirty_log_sync
memory_region_sync_dirty_bitmap
listener->log_sync_global(listener) === 》kvm_log_sync==》将KVM的脏页记录获取保存到 ram_list.dirty_memory
ramblock_sync_dirty_bitmap
cpu_physical_memory_sync_dirty_bitmap===》 ram_list.dirty_memory[DIRTY_MEMORY_MIGRATION]->blocks中的脏页信息是复制到热迁移的迁移位图migration_bitmap_rcu->bmap中
kvm_log_sync
kvm_physical_sync_dirty_bitmap
kvm_slot_get_dirty_log
kvm_vm_ioctl(s, KVM_GET_DIRTY_LOG, &d) === 获取KVM脏页
kvm_slot_sync_dirty_pages
cpu_physical_memory_set_dirty_lebitmap(slot->dirty_bmap, start, pages)
static inline void cpu_physical_memory_set_dirty_lebitmap(unsigned long *bitmap,
ram_addr_t start,
ram_addr_t pages)
{
unsigned long i, j;
unsigned long page_number, c;
hwaddr addr;
ram_addr_t ram_addr;
unsigned long len = (pages + HOST_LONG_BITS - 1) / HOST_LONG_BITS;
unsigned long hpratio = qemu_real_host_page_size() / TARGET_PAGE_SIZE;
unsigned long page = BIT_WORD(start >> TARGET_PAGE_BITS);
/* start address is aligned at the start of a word? */
if ((((page * BITS_PER_LONG) << TARGET_PAGE_BITS) == start) &&
(hpratio == 1)) {
unsigned long **blocks[DIRTY_MEMORY_NUM];
unsigned long idx;
unsigned long offset;
long k;
long nr = BITS_TO_LONGS(pages);
idx = (start >> TARGET_PAGE_BITS) / DIRTY_MEMORY_BLOCK_SIZE;
offset = BIT_WORD((start >> TARGET_PAGE_BITS) %
DIRTY_MEMORY_BLOCK_SIZE);
WITH_RCU_READ_LOCK_GUARD() {
for (i = 0; i < DIRTY_MEMORY_NUM; i++) {
blocks[i] =
qatomic_rcu_read(&ram_list.dirty_memory[i])->blocks;
}
for (k = 0; k < nr; k++) {
if (bitmap[k]) {
unsigned long temp = leul_to_cpu(bitmap[k]);
qatomic_or(&blocks[DIRTY_MEMORY_VGA][idx][offset], temp);
if (global_dirty_tracking) {
qatomic_or(
&blocks[DIRTY_MEMORY_MIGRATION][idx][offset],
temp);
if (unlikely(
global_dirty_tracking & GLOBAL_DIRTY_DIRTY_RATE)) {
total_dirty_pages += ctpopl(temp);
}
}
if (tcg_enabled()) {
qatomic_or(&blocks[DIRTY_MEMORY_CODE][idx][offset],
temp);
}
}
if (++offset >= BITS_TO_LONGS(DIRTY_MEMORY_BLOCK_SIZE)) {
offset = 0;
idx++;
}
}
}
xen_hvm_modified_memory(start, pages << TARGET_PAGE_BITS);
} else {
}
}
流结构
迁移数据流结构与关键字和字节序无关。
- Header
- Magic
- Version
- VM configuration section
- Machine type
- Target page bits
- Sections列表,每个sectio包含一个设备或者一个设备保存的迭代
- section type
- section id
- ID string (First section of each device)
- instance id (First section of each device)
- version id (First section of each device)
- <device data>
- Footer mark
- EOF mark
- VMDescription 有分析的描述信息的Json
对于不迭代的设备有一个section,迭代设备有初始化、最后一部分、一组介于两者之间的section。通用代码的完整性检查很少,主要依赖设备自己,当接收的数据比预期的多或者少时,提供一点保护。
例如:一个场景中,错误码指示迁移检查遇到IO错误,排查后发现原因是存储网通道有丢包现象。

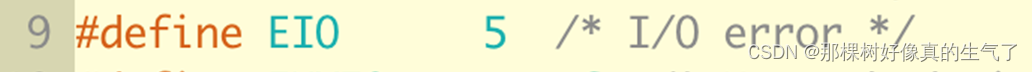
后复制拷贝方式
正常迁移只需要单向流,需要双向流向时可以创建返回路径,主要用于postcopy,也用于迁移结束时返回给源端成功标识。
qemu_file_get_return_path(QEMUFile* fwdpath) 返回QEMUFIle*的指针
源端
Forward path - written by migration thread Return path - opened by main thread, read by return-path thread
目的端
Forward path - read by main thread Return path - opened by main thread, written by main thread AND postcopy thread (protected by rp_mutex)
当虚拟机内存变化大,始终降不到水线下,内存脏页无法收敛或者需要很久收敛,迁移无法完成。Qemu提出postcopy迁移模式,传统迁移称为precopy。区别是postcopy的脏页拷贝在启动之后还会继续,迁移流量和时间有限的,但是任何一端失败或者网络故障之后无法恢复vm。
Postcopy过程:
- 迁移设备状态
- 标脏所有内存,拷贝所有内存到目的端,启动vm
- 当目的端vm访问到内存脏页时,发生缺页异常,qemu从源端拷贝脏页对应内存。
Monitor开启postcopy方法:
migrate_set_capability postcopy-ram on
migrate_start_postcopy
- 命令行执行示例,
两边都放一个qcow2磁盘或者使用共享存储
B:/usr/libexec/qemu-kvm -m 2G --enable-kvm -cpu host -incoming tcp:192.168.180.130:6666
A:/usr/libexec/qemu-kvm -m 2G --enable-kvm -cpu host -monitor stdio
A: migrate tcp:192.168.180.130:6666
migrate_set_speed 1g
- 主要Api
| Monitor cmd (Qmp/Hmp) | info migrate info migrate_capabilities info migrate_parameters | 获取迁移信息 |
| migrate | 迁移到对端 | |
| migrate_cancel | ||
| Migrate_continue | 从paused恢复迁移 | |
| Migrate_incoming | 开始传入迁移,使用-incoming启动qemu | |
| Migrate_recover | 迁移恢复 | |
| Migrate_pause | 仅支持postcopy迁移模式 | |
| migrate_set_capability | ||
| migrate_set_parameter | ||
| migrate_start_postcopy |
| Event | MIGRATION | 迁移发送status |
| MIGRATION_PASS | 迁移同步时,从源端发送 | |
| UNPLUG_PRIMARY | Vm未插入设备 |
调试
调试工具:scripts/analyze-migration.py
示例:
$ qemu-system-x86_64 -display none -monitor stdio
(qemu) migrate "exec:cat > mig"
(qemu) q
$ ./scripts/analyze-migration.py -f mig
{ "ram (3)": {
"section sizes": {
"pc.ram": "0x0000000008000000",
...