代码生成解决方案
生成项目代码有3大类的解决思路:
1.从底到上的生成,部分代码生成生成一行代码或者一个方法种一小块代码生成,ide插件代码生成基本这种思路
2.大语言模型作为软件工程不同角色agent,用户给出idea每个agent自动分工生成代码
3.抽象出具体项目下代码生成的流程框架,在框架中利用大模型生成模块代码
第1种技术路线是目前to c产品的主流路线,这条技术路线解决的实际上是解决了一个通用语言API复杂、函数方法种类多、通用语言代码量大、非业务逻辑代码一致性强的问题。通用语言总多的方法函数、功能要完全记住是不可能的,代码量也大,如果可以通过输入自己想法把需要的函数、方法、一小段的通用非业务核心逻辑代码直接写出来,这是可以极大的提高程序员开发效率的。这种方式本质其实是把以前查开发手册、参考示例代码、开发问答社区、辅助修改代码这些程序员开发常用环境集成到一个大模型中,可以通过文本问答方式来辅助开发。
第2条技术方案大模型角色扮演的路线,优点人只要给一个点子就能生成一个项目代码;不足随机性较大、可控性较弱、代码不一定符合要求,项目代码验证对错成本较高。这种方案本质就是跳过程序开发这个环节,让机器来完全参照软件工程流程做代码开发。
第3条技术方案路线,是对前面两种方案的中和。在很多企业已经开始推行code less的思路,都会针对自己企业需要设计合适的业务代码;这些业务代码的语法逻辑、功能函数比通用语言简单很多,开发同学大部分是在把业务逻辑转代码,所以第1种技术路线提供的几行、一小段代码生成能力在这种场景不一定适用。生成代码准确率会比较低、业务开发描述问题复杂度和写业务代码实现复杂度相当。所以如果要在业务代码上做辅助就不能按第1种技术方案,必须要做到业务开发少量输入就可以至少输出一个完全可用功能模块、或者直接生成一个代码项目。第2种方案理论讲交付形式是满足业务开发同学预期的,然而这种多角色扮演的方式目前存在稳定性不高、可控性较差、生成代码质量相对较低不符合预期的问题。所以最好的办法就是把2、2种技术做组合,大模型只是充当代码编程人员,整体的代码流程设计、框架架设全部还是人抽象出来,相当于大模型是在有限框架下解决问题,生成代码可控性较好;但也存在流程较死板,抽象、框架假设、代码生成prompt管理复杂任务较繁重问题,当然这些问题都可以通过工程系统自动化配合得到适当解决。
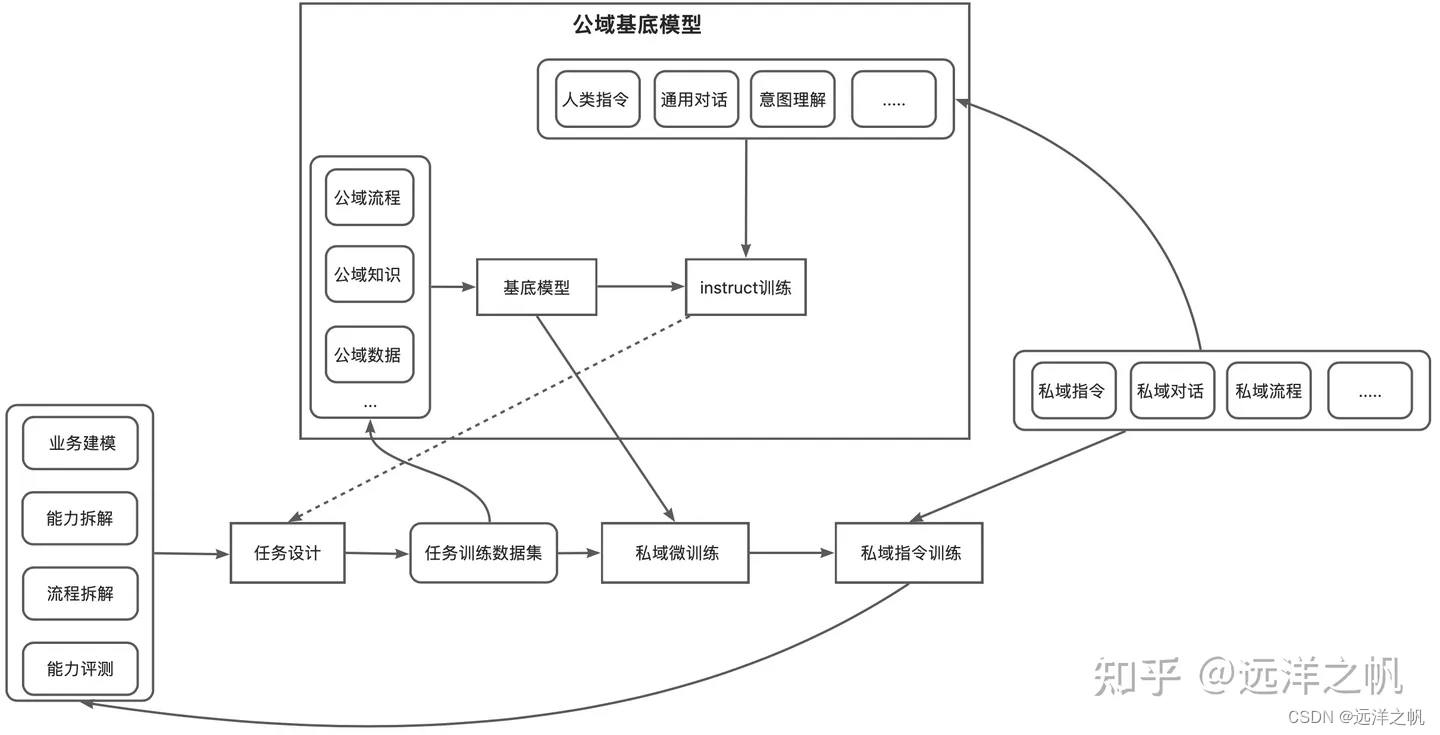
mutli-agnet模式探索
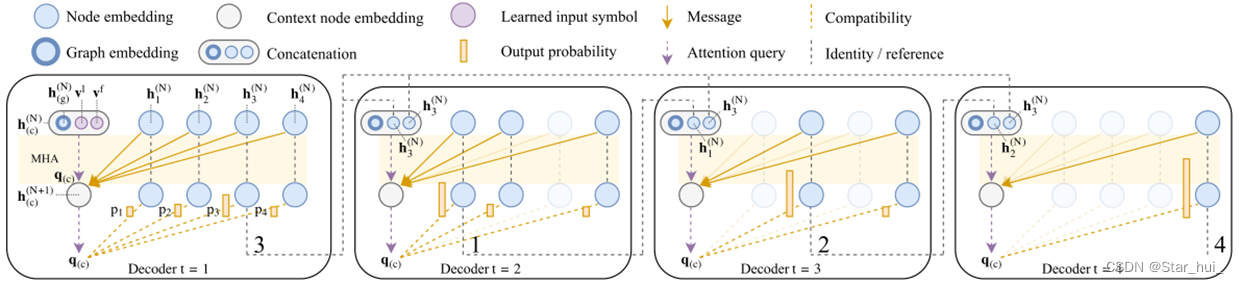
这部分是探索性工作,根据软件工程代码开发流程(瀑布式开发流程)需要的组织结构、事件流程,让llm来扮演不同角色进行软件开发活动模拟;根据用户的输入需求点生成最后的代码程序。
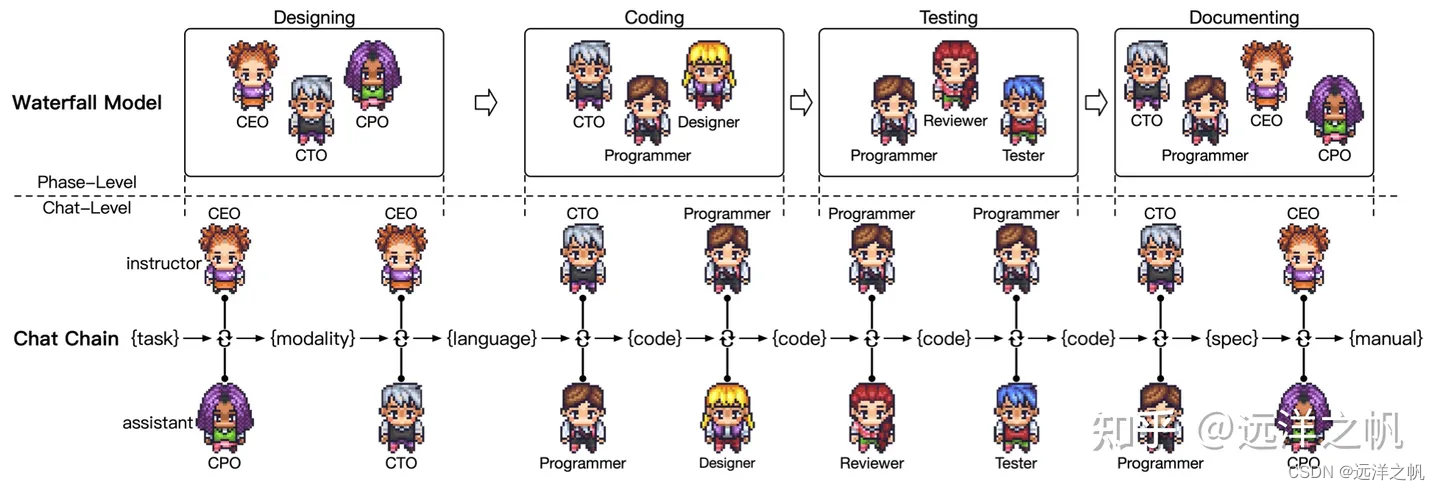
这幅图描述的是瀑布流开发模式下,软件开发流程。并把开发流程变成了对话模式,产出中间产物来约束和保证下游产出代码的可靠性。
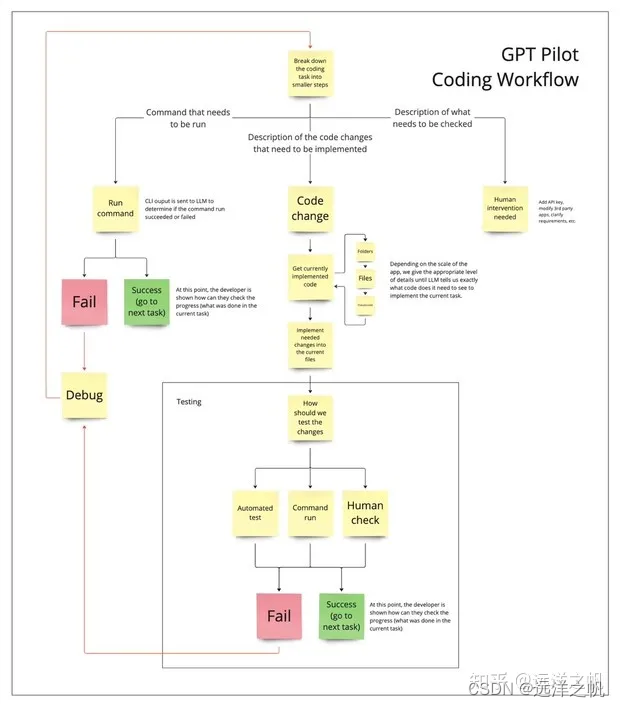
上面一张图描述的是实际的LLM如何执行上面流程生成代码,不停对话尝试知道产出可执行代码位置的流程图。
上面提到了代码生成的3种思路,然后无论是哪一种思路都需要一个强大的基底模型。下面部分会介绍有哪些开源模型可供选择,有哪些训练技术路线可以让模型变强大。
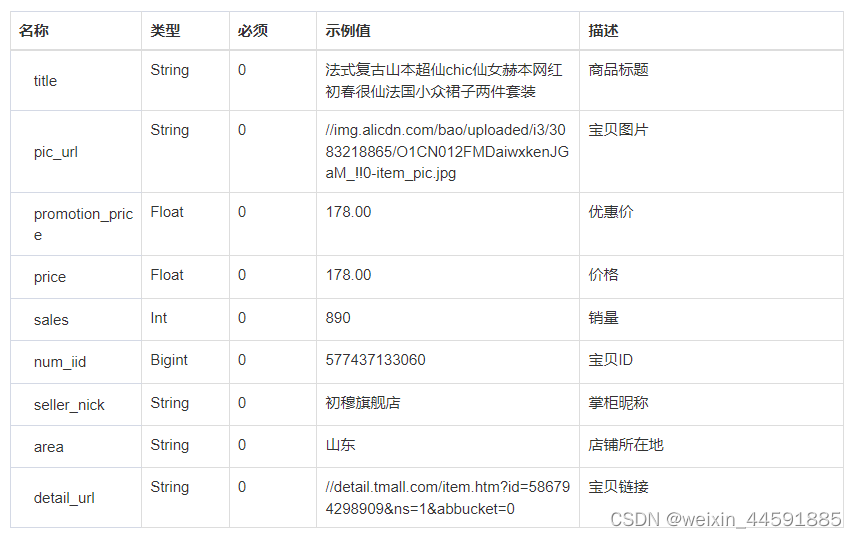
开源代码生成模型参数比较
下图是开源的代码生成模型参数和效果比较数据表
| 模型 | size | 架构 | pass@1 |
| codeT5+ | T5 | ||
| code-davinci-2 | GPT | 59.86% | |
| codegeex2 | 6B | GLM | 35% |
| starcode | 15.5B | decode only | 38.2% |
| codegen16b | 16B | decode only | 29.28% |
| InCoder-6.7B | 6.7B | Fairseq | 15.6% |
| Palm- coder | 540B | 36% | |
| code llama | 34B | decode only | 43% |
codellama是语言模型做大规模语言预训练,让模型具备了根据人类需求生成代码能力;在代码生成、代码补全、代码注释生成、语意理解能力较强,在某些情况超过chatgpt根据人类语言生成代码能力、支持16k甚至更长上下文。
starcoder是代码模型做填空、注释生成,让模型具备了根据人类需求生成代码能力;具备代码生成、代码注释、代码补全、语意理解能力,支持8k上下文token。
starcode
starcode的预训练
用mega-ml来实现
#下载megatron-ml
git clone https://github.com/bigcode-project/Megatron-LM.git
#安装apex
git clone https://github.com/NVIDIA/apex.git
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
#下载wiki_zh数据
******/pleisto___json
#数据预处理
bash preprocess_santacoderpack.sh
#跑预训练模型
bash pretraning_santacoderpack.sh
'''
附件preprocess_santacoderpack.sh脚本
'''
INPUT=****/pleisto___json # merge datasets jsonl from commitpack-subset-cf
NAME=wiki_zh # you want data name
TOKENIZER_FILE=******/starcoderplus/tokenizer.json
VOCAD=******/starcoderplus/vocab.json
# File Path setup
SCRIPT_REPO=******/Megatron-LM
pushd $SCRIPT_REPO
python tools/preprocess_data.py \
--input $INPUT \
--output-prefix $NAME \
--dataset-impl mmap \
--tokenizer-type TokenizerFromFile \
--tokenizer-file $TOKENIZER_FILE \
--json-keys 'completion'\
--workers 30 \
--chunk-size 1000
'''
附件pretraning_santacoderpack.sh脚本
'''
#! /bin/bash
# set -u # stop on unset variables
#export WANDB_API_KEY= # your wandb key
#export WANDB_PROJECT= # your wandb project name
NNODES=1 #$WORLD_SIZE # Adjust
GPUS_PER_NODE=4
RANK=0
export MASTER_ADDR=127.0.0.1
export MASTER_PORT=9001
export CUDA_DEVICE_MAX_CONNECTIONS=1
GPU_NUM=$(($GPUS_PER_NODE*$NNODES))
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
echo "================================================"
echo "GPU_NUM: $GPU_NUM"
echo "================================================"
DISTRIBUTED_ARGS="\
--nproc_per_node $GPUS_PER_NODE \
--nnodes $NNODES \
--node_rank $RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
"
echo $DISTRIBUTED_ARGS
CHECKPOINT_PATH=****/starcoderplus # Adjust: Directory to store the checkpoints
DATA_PATH=******/Megatron-LM/wiki_zh_completion_document # Adjust: Prefix of the preprocessed dataset.
TOKENIZER_FILE=******/starcoderplus/tokenizer.json # Adjust: starcoder-tokenizer/tokenizer.json
GPT_ARGS="\
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
--recompute-activations \
--num-layers 24 \
--hidden-size 2048 \
--num-attention-heads 16 \
--attention-head-type multiquery \
--init-method-std 0.022 \
--seq-length 8192 \
--max-position-embeddings 8192 \
--attention-dropout 0.1 \
--hidden-dropout 0.1 \
--micro-batch-size 2 \
--global-batch-size 64 \
--lr 0.0002 \
--train-iters 250000 \
--lr-decay-iters 600000 \
--lr-decay-style cosine \
--lr-warmup-fraction 0.02 \
--weight-decay .1 \
--adam-beta2 .95 \
--clip-grad 1.0 \
--bf16 \
--log-interval 10 \
--save-interval 1000 \
--eval-interval 500 \
--eval-iters 10 \
--initial-loss-scale 65536 \
"
TENSORBOARD_ARGS="--tensorboard-dir ${CHECKPOINT_PATH}/tensorboard"
torchrun $DISTRIBUTED_ARGS \
pretrain_gpt.py \
$GPT_ARGS \
--tokenizer-type TokenizerFromFile \
--tokenizer-file $TOKENIZER_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS \starcoder 做sft
#代码下载
git clone https://github.com/bigcode-project/octopack.git
#数据准备
有问答的数据对,可以设计数据结构,比如:
{instruction:"",input:"",history:"",respond:""}
#参数设置
/mnt/user/caifu/252256/WizardLM/WizardCoder/configs/deepspeed_config.json
/mnt/user/caifu/252256/WizardLM/WizardCoder/WZsft.sh
#执行脚本
bash WZsft.sh
'''
附件WZsft.sh
'''
deepspeed --num_gpus 8 --master_port=9901 src/train_wizardcoder.py \
--model_name_or_path "/mnt/user/caifu/252256/llm_model/starcode_instruct2/checkpoint-3600" \
--data_path "/mnt/user/caifu/252256/LLaMA-Efficient-Tuning/data/alpaca_data_zh_51k.json" \
--output_dir "/mnt/user/caifu/252256/llm_model/starcode_instruct3" \
--num_train_epochs 3 \
--model_max_length 8192 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 100 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--warmup_steps 30 \
--logging_steps 2 \
--lr_scheduler_type "cosine" \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed configs/deepspeed_config.json \
--fp16 Truestarcoder高效推理
#下载代码
git clone https://github.com/bigcode-project/starcoder.cpp
cd starcoder.cpp
# Convert HF model to ggml
python convert-hf-to-ggml.py bigcode/gpt_bigcode-santacoder
# Build ggml libraries
#只支持cpu推理编译
make
#支持gpu和cpu推理编译
make clean && LLAMA_CUBLAS=1 make -j
# quantize the model
./quantize models/bigcode/gpt_bigcode-santacoder-ggml.bin models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin 3
# run inference
./main -m models/bigcode/gpt_bigcode-santacoder-ggml-q4_1.bin -p "def fibonnaci(" --top_k 0 --top_p 0.95 --temp 0.2codellama
code llama预训练
#下载llama训练代码
git clone https://github.com/hiyouga/LLaMA-Efficient-Tuning.git
#准备预训练数据
wiki_zh
内部代码数据
#下载模型
******/CodeLlama-13b-Instruct-hf
******/CodeLlama-13b-hf
******/CodeLlama-34b-Instruct-hf
******/CodeLlama-34b-hf
#设定参数
******/LLaMA-Efficient-Tuning/ds_zero3_config.json
******/LLaMA-Efficient-Tuning/pretrain_finetune.sh
#执行预训练脚本
bash code_llama_fintune.sh
'''
附件pretrain_finetune.sh
'''
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_zero3_config.json \
--stage pt \
--model_name_or_path ******/CodeLlama-13b-Instruct-hf \
--do_train \
--dataset wiki_zh_pre \
--template default \
--finetuning_type full \
--lora_target q_proj,v_proj \
--output_dir ******/CodeLlama-13b-Instruct-pre1 \
--overwrite_cache \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 5e-5 \
--warmup_steps 30 \
--num_train_epochs 3.0 \
--plot_loss \
--report_to "tensorboard" \
--fp16
'''
附件ds_zero3_config.json
'''
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 0,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 0,
"stage3_max_reuse_distance": 0,
"stage3_gather_16bit_weights_on_model_save": true
},
"fp16": {
"enabled": true,
"auto_cast": false,
"loss_scale": 0,
"initial_scale_power": 32,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 5e-5,
"betas": [
0.9,
0.999
],
"eps": 1e-8,
"weight_decay": 0
}
},
"train_batch_size":256 ,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps":2,
"wall_clock_breakdown": false
}
codellama做sft
#数据准备
数据准备和任务设计是强绑定的
这部分是重点
#执行脚本
bash code_llama_fintune.sh
#如果用lora训练,参数合并
bash export_lora_sft.sh
'''
附件code_llama_fintune.sh
'''
deepspeed --num_gpus 4 --master_port=9901 src/train_bash.py \
--deepspeed ds_zero3_config.json \
--stage sft \
--model_name_or_path ******/CodeLlama-13b-Instruct-hf \
--do_train \
--dataset code_alpaca \
--template default \
--finetuning_type full \
--lora_target q_proj,v_proj \
--output_dir ******/CodeLlama-13b-Instruct-full0 \
--overwrite_cache \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 5e-5 \
--warmup_steps 30 \
--num_train_epochs 3.0 \
--plot_loss \
--report_to "tensorboard" \
--fp16
'''
附件export_lora_sft.sh
'''
python src/export_model.py \
--model_name_or_path ******/CodeLlama-34b-hf \
--template default \
--finetuning_type lora \
--checkpoint_dir ******/CodeLlama-34b-Instruct-sft1 \
--output_dir ******/CodeLlama-34b-Instruct-0llama2 dpo训练
#下载训练代码
git clone https://github.com/shibing624/MedicalGPT.git
#准备数据
{"question": "维胺酯维E乳膏能治理什么疾病?", "response_chosen": "痤疮;暴发性痤疮;寻常痤疮;婴儿痤疮;聚合性痤疮;沙漠疮;背痈;肺风粉刺;职业性痤疮", "response_rejected": "维埃胶可以治疗湿疹、荨麻疹和过敏性鼻炎等皮肤病。"}
******/MedicalGPT/data/reward/test.json
#执行训练脚本
bash run_dpo.sh
'''
附件run_dpo.sh
'''
CUDA_VISIBLE_DEVICES=0,1,2,3 python dpo_training.py \
--model_type llama \
--model_name_or_path ******/CodeLlama-13b-Instruct-hf \
--train_file_dir ./data/reward \
--validation_file_dir ./data/reward \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--do_train \
--do_eval \
--use_peft True \
--max_train_samples 10000 \
--max_eval_samples 10 \
--max_steps 10000 \
--eval_steps 20 \
--save_steps 1000 \
--max_source_length 1024 \
--max_target_length 1024 \
--output_dir ******/CodeLlama-13b-Instruct-dpo1\
--target_modules all \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--torch_dtype float16 \
--fp16 True \
--device_map auto \
--report_to tensorboard \
--remove_unused_columns False \
--gradient_checkpointing True \
--cache_dir ./cachellama高效推理:
1.下载和安装llama.cpp代码项目
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
#只支持cpu推理编译
make
#支持gpu和cpu推理编译
make clean && LLAMA_CUBLAS=1 make -j
2.把模型转成gmml格式,方便后面cpp推理使用
# convert the 7B model to ggml FP16 format
python3 convert.py models/7B/
# [Optional] for models using BPE tokenizers
python convert.py models/7B/ --vocabtype bpe
# quantize the model to 4-bits (using q4_0 method)
./quantize /mnt/qian.lwq/CodeLlama-34b-Instruct-0/ggml-model-f16.gguf /mnt/qian.lwq/CodeLlama-34b-Instruct-0/ggml-model-q4_0.gguf q4_0
3.用转化好的模型推理
#仅用cpu推理
./main -m /mnt/qian.lwq/CodeLlama-34b-Instruct-0/ggml-model-f16.gguf -p "给下面这段代码添加注释 \n def querySymbolInfo = { row, symbolList, fields ->\n def symbolFacadeClient = row.get('symbolFacadeClient') as SymbolFacadeClient \n SymbolRequest req = new SymbolRequest() \t\n req.setSymbols(symbolList as List<String>) \n req.setFields(fields as String) \t\n Result<SymbolDTOWrapper> result = symbolFacadeClient.querySymbolInfo(req) \n AssertUtils.assertTrue(Status.SUCCESS.equals(result.getStatus()), ErrorCodeEnum.REMOTE_UNEXPECTED_RESULT,\t\n result.getStatus().getMessage()) \t\b return result.getData().getDatas() \t\n } \n " -n 512 -ngl 15 -e
#cpu和gpu混合推理
./main --color --interactive --model /mnt/qian.lwq/CodeLlama-34b-Instruct-0/ggml-model-f16.gguf --n-predict 512 --repeat_penalty 1.0 --n-gpu-layers 15 --reverse-prompt "User:" --in-prefix " " -p "Building a website can be done in 10 simple steps:\nStep 1:"后续工作
1、数据梳理
2.cot和多轮对话训练调整
3.投机采样加快推理速度实现
4.多机器人协作代码生成调研
5.starcoder dpo训练
小结
对代码生成的几种商业化可能做了总结梳理,描述了不同模式下适用的场景和可能存在的问题。目前代码生成主要产品形态还是to c产品,相当于是对程序员开发中查询开发手册、社区问答、代码修改、代码示例能力整合到了一个大模型中。然后对于商业价值更大的to b代码生成,准确可控可执行的代码模块、项目代码生成产品在市面还未见。to b代码生成难度往往不在于代码复杂度,而在于能够准确无误的生成实际可用的代码,真实的减少业务开发人员的工作量。这其实是一次软件工程自动化的过程,就是对软件开发做自动化;软工程和自动化本身就是对生产的一次自动化,这次的自动化是对自动化的自动化。
文章也介绍了starcoder、codellama模型增强训练,补强模型能力的技术。