目录
一、生产者消费者模型
二、代码实现模型
2.1 BlockQueue.hpp
2.2 MainCP.cc
2.3 执行结果
三、效率优势
一、生产者消费者模型
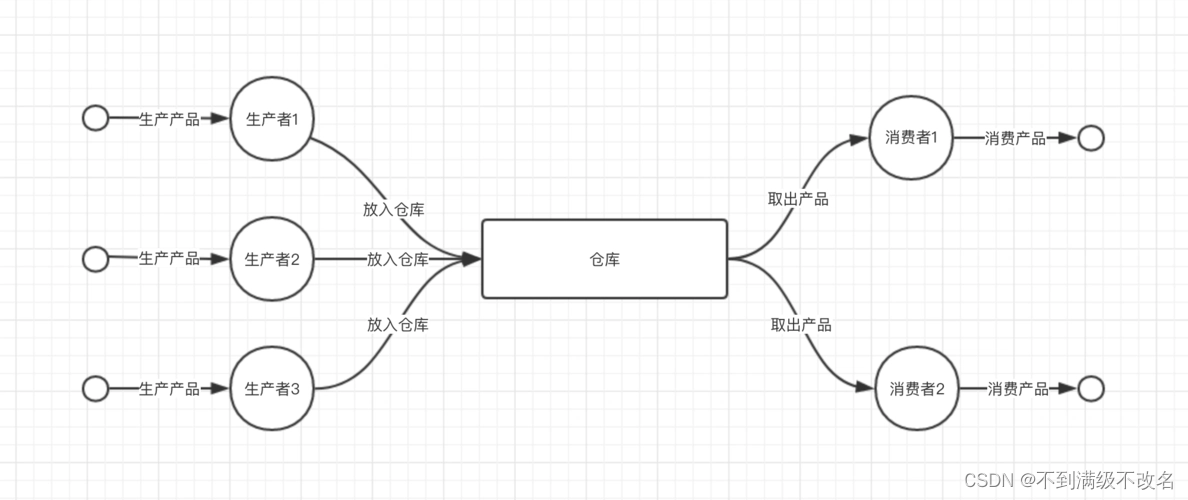
将上述图片逻辑转换成代码逻辑就是,一批线程充当生产者角色,一批线程充当消费者角色,仓库是生产者和消费者获取的公共资源!下面我想用321原则来解释这个模型。
既然是公共资源,那么我们就需要考虑线程安全问题!
3指的是三者之间的关系!当一个生产者向仓库生产资源的时候,消费者不可以进入仓库取资源!同样,当一个生产者向仓库放入资源的时候,其他生产者不能同时也向同一个位置放入资源,也就是说生产者要等上一个生产者走出仓库后进入仓库!同样消费者与消费者也是这样的关系!也就是说生产者与生产者互斥,生产者与消费者互斥,消费者与消费者互斥!
当消费者与生产者完成自己的操作后,会提醒对方前来进行对方的操作!也就是说,生产者与消费者同步!
2指的是2中角色:生产者和消费者
1指的是存储资源的容器(仓库):一段特定结构的缓冲区(队列、栈、链表)
二、代码实现模型
2.1 BlockQueue.hpp
#pragma once
#include<iostream>
#include<pthread.h>
#include<queue>
template <class T>
class BlockQueue
{
public:
static const int gmaxcap = 5;
BlockQueue(const int maxcap = gmaxcap):_capacity(maxcap)
{
//初始化
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_pcond,nullptr);
pthread_cond_init(&_ccond,nullptr);
}
void push(const T& in)
{
//加锁互斥
pthread_mutex_lock(&_mutex);
//细节:为什么这里用while循环判断?
//-->有一种可能性,当生产者很多而消费者只有一个,第一次条件满足进入阻塞后,消费者处理了
// 一个任务
//这样就会同时唤醒一批生产者,如果只是if,他们不会再次判断而是直接“同时!”进行后面push的
//逻辑!这样不是线程安全的
while(is_full())
{
pthread_cond_wait(&_pcond,&_mutex);
}
//进行到这表示一定有空余空间存数据
_q.push(in);
//唤醒消费者
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
void pop(T* out)
{
pthread_mutex_lock(&_mutex);
//和上面逻辑一样
while(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
//到这表示一定有数据
*out = _q.front();
_q.pop();
//唤醒生产者
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_pcond);
pthread_cond_destroy(&_ccond);
}
private:
bool is_empty()
{
return _q.empty();
}
bool is_full()
{
return _q.size() == _capacity;
}
private:
std::queue<T> _q; //存储任务队列
int _capacity;
pthread_mutex_t _mutex; //一把锁 -> 3互斥原则
pthread_cond_t _pcond; //生产者条件变量
pthread_cond_t _ccond; //消费者条件变量
};
2.2 MainCP.cc
#include "BlockQueue.hpp"
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <functional>
// 任务对象
class Task
{
public:
//==typedef
using func_t = std::function<double(int, int, char)>;
Task() {}
Task(func_t callback, int x = 0, int y = 0, char op = '+') : _x(x), _y(y), _op(op), _callback(callback)
{
}
// 仿函数
std::string operator()()
{
double ret = _callback(_x, _y, _op);
char buffer[64];
snprintf(buffer, sizeof buffer, "%d %c %d = %lf", _x, _op, _y, ret);
return buffer;
}
private:
int _x;
int _y;
char _op;
func_t _callback; // 回调函数
};
//处理数据函数
double calculator(int x, int y, char op)
{
double ret = 0.0;
switch (op)
{
case '+':
ret = x + y;
break;
case '-':
ret = x - y;
break;
case '*':
ret = x * y;
break;
case '/':
if (y == 0)
ret = 0;
else
ret = (double)x / y;
break;
case '%':
if (y == 0)
ret = 0;
else
ret = x % y;
break;
default:
break;
}
return ret;
}
// 生产者任务
void *producer(void *args)
{
BlockQueue<Task> *bq = static_cast<BlockQueue<Task> *>(args);
while (true)
{
// 1.获取数据
const char *str = "+-*/%";
int x = rand() % 10 + 1;
int y = rand() % 5 + 1;
char op = str[rand() % 5];
// 2.构建任务对象&传送对于的处理方法
Task t(calculator, x, y, op);
// 3.存入队列
bq->push(t);
std::cout << "生产任务: " << x << " " << op << " " << y << " = ?" << std::endl;
sleep(1);
}
}
// 消费者任务
void *consumer(void *args)
{
BlockQueue<Task> *bq = static_cast<BlockQueue<Task> *>(args);
while (true)
{
Task t;
// 1.获取任务
bq->pop(&t);
// 2.执行仿函数
std::cout << "消费任务: " << t() << std::endl;
}
}
int main()
{
srand((unsigned long)time(nullptr) ^ getpid());
pthread_t c, p;
BlockQueue<Task> *bq = new BlockQueue<Task>();
pthread_create(&c, nullptr, consumer, bq);
pthread_create(&p, nullptr, producer, bq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}2.3 执行结果
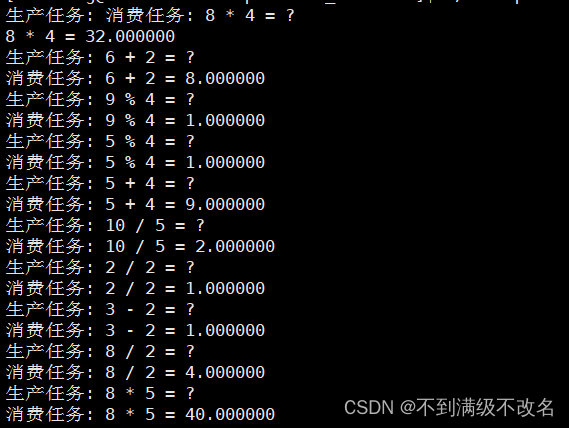
三、效率优势
上面的是单个线程,可以拓展到多生产者多消费者!但是我们疑惑的是这个模型在访问资源的时候,都是互斥的!他们只有一个能进入到临界区,这样怎么是高效的?原来这个模型的高效不是在访问临界资源,而是对于每个线程可以独立的准备数据!我们上述实现的数据来源以及数据处理是简单的,但是后面数据可能来源于网络或者磁盘文件,这个过程每个线程都可以同时在线获取或者处理!这个过程如果串行是低效率的,但是多线程可以大大提高IO效率!这就是生产者消费者模型高效的原因!它可以将IO数据分散给多个线程并行处理,极大地提高了效率!