视频领域的多模态预训练工作近年来逐渐兴起。多模态模型通常融合了图像、视频、文本等多类特征,性能优于单模态模型。预训练模型通常以自监督的方式在大批量数据集上进行训练,而后服务于下游任务。本文梳理了近年来视频多模态预训练领域的相关工作,首先简单介绍各大多模态预训练数据集,而后阐述了近年来基于不同多模态预训练任务的工作成果并罗列了常见的下游任务,最后本文讨论了当前研究存在的问题,并对未来多模态预训练领域做出展望。
https://zhuanlan.zhihu.com/p/408111890
1.引言
当前主流的视频理解算法包含多个基础领域,例如动作识别、时序动作定位、视频问答、视频检索等。视频相对于纯文本和图像的特点在于其多模态性质,视频包含了大致同步的音频、文字、图像信息,为视频理解分析提供了丰富的信息来源。视觉和语言两种模态的信息可以互相作为指引,提高面向单一模态或跨模态任务的完成效果。
基于视觉语言的任务有很多,不过不同任务之间若分别使用专有数据训练,时间和经济成本较高。使用预训练与微调可以极大降低成本,近年来预训练被逐渐应用于视频理解领域,视频预训练模型首先在大规模通用数据集上做预训练,方式通常以自监督为主,习得通用表征,再在小型专有数据集做微调应用于特定任务。
目前视频多模态预训练依旧存在较大的挑战,难点之一在于数据集的缺乏,尤其是多模态数据集。手动注释麻烦且昂贵,这极大地限制了视频领域的发展,除此之外,目前视频领域数据集的噪声问题也对模型训练造成了困扰,典型的噪声来源中,最主要的一个是视频和语言之间的弱对齐,即当前视频帧与对应语言描述的低相关性。除了数据集之外,另一个难点在于如何对不同模态有效建模,高质量地建立起多模态之间的联系,提升下游任务性能。
对于数据集缺乏和噪声问题,当前的工作通常采取从互联网中获取大量相关叙述性视频、附带字幕的影视剧的方式制作数据集,并引入多实例学习和对比学习、噪声估计等方式降低训练噪声的影响。除此之外,人们还设计 VideoBERT、CBT、HERO、MERLOT 等模型用于预训练和多类下游任务。
本文梳理了近年来视频多模态预训练领域的相关工作,简要介绍当前多模态模型经常使用到的预训练数据集,从多类预训练方法出发论述了自 2019 年至今的主要模型架构,并罗列了常见的下游任务,最后做了对多模态预训练模型的总结与展望。
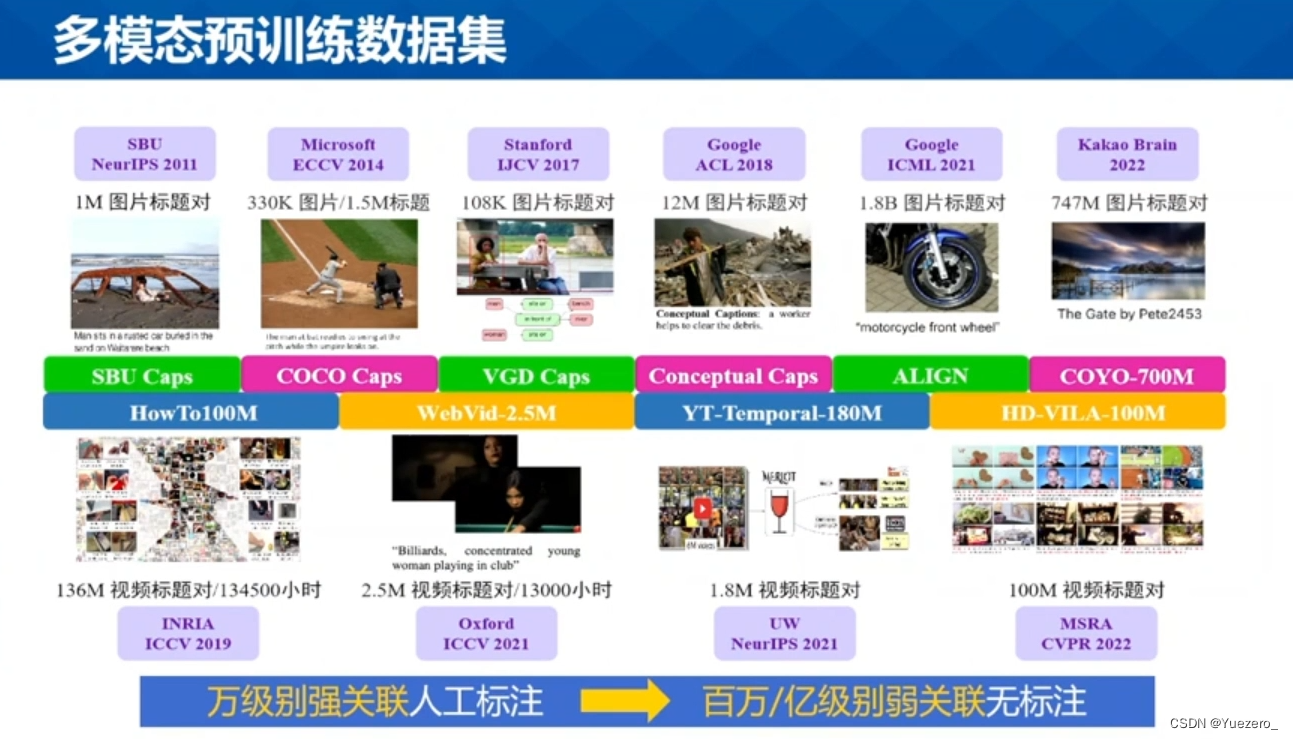
2. 预训练数据集
常用公开的视频文本数据集有 HowTo100M、YT-Temporal-180M、WebVid-2M、VQA 等。
3. 视频-文本多模态预训练模型
2018 年,自然语言推出 BERT 预训练模型,从此各领域预训练大模型研究工作逐渐受到重视,在视频领域近年来也出现了许多基于预训练与多模态的研究成果。下面分别以从多种不同的预训练方式出发介绍历年来的主要模型。
3.1掩蔽(MASK)方法
多模态预训练中常使用掩蔽某一模态或某几个模态部分信息的方式进行训练,常用的预训练方式包括掩蔽语言预测 MLM、掩蔽区域预测 MTM、掩蔽帧预测 MFM 等.
3.1.1 VideoBERT
VideoBERT [15] 由 Sun 等人于 2019.9 月提出,该模型首次将 Transformer 结构扩展到了视频语言多模态预训练中,其可以在无需明确监督的条件下学习到高级特征。VideoBERT受到自然语言模型 BERT 的启发,在其基础上学习了视频数据矢量量化和语音识别后输入的双向联合分布,该工作同时说明了大规模训练数据和跨模态信息对于模型性能的重要性。 VideoBERT 将自然语音处理得到的文本做类 BERT 处理提取文本特征,用 S3D 处理视频段然后做层级 k 聚类提取视频特征,然后将两种特征一起输入到 Transformer 中, 使用掩蔽语言预测 (MLM)、视频文本匹配 (VTM) 以及掩蔽视频预测 (VOM) 三种预训练任务做训练。
3.1.2 ActBERT
ActBERT [19] 引入了全局动作的概念,该模型对输入视频使用了两种编码方式,一种是将视频帧堆叠得到全局堆叠帧,另一种则是对每一帧图像用 Faster-RCNN 提取 RoI 特征。预训练过程中,除了使用已有的视频文本匹配、掩蔽语言预测、和掩蔽区域类别分类以外,该方法还提出了掩蔽动作分类 (mask action classification,MAC),具体而言,是对输入的动作表示向量做随机掩蔽,用以让模型根据其余信息预测动作标签。
3.1.3 HERO
HERO [8] 模型使用了 ResNet 和 Slow-Fast 提取视频帧中的二维和三维视觉特征,而后利用全连接层将特征投影使得其文本编码同一维度,从而与文本编码一样处理,将该视频编码与位置编码相加后做 LN 得到最终帧编码。除此之外,HERO 还引入了时序 Transformer,使用每一帧周围的所有帧作为全局上下文。HERO 针对时序 Transformer 设计了新的预训练任务,即帧序列预测 (frame order modeling,FOM), 该任务意在学习利用视频的序列性,首先随机打乱部分输入帧的顺序,然后再预测每一帧对应的实际位置。
3.1.4 ClipBERT
ClipBERT [7]于 2021.2.11 提出,使用稀疏采样替代了密集采样提取视频帧的方式,减轻了前期模型的计算量。ClipBERT 认为视频中存在大量冗余信息,而整体信息的提取仅需要少量间断的图像,因而在训练过程中采用稀疏采用进行训练。ClipBERT 还将图像-文本预训练模型用作参数的初始化,并使用了 ResNet 结构作为视频编码网络。
3.1.5 UniVL
Luo 等人提出了 UniVL [10] 模型用于下游生成式任务,采用自回归解码器,输入为处理后的文本和视频帧,意在输出原始文本。该工作同时提出了逐阶段预训练和增强视频表示的方法,前者先对输入使用 NCE 做训练,再做所有目标训练;后者以 15% 的概率屏蔽全部文本输入。
3.1.6 MERLOT
Zellers 等人于(2021.6.4)训练了具有时间常识学习能力的模型 MERLOT(multimodal event representation learning over time)[18],该模型使用了比以往提出的模型中用到的更为大量的数据集做训练,即作者团队与 MERLOT 同时发布的 YT-Temporal-180M 数据集。MER-LOT 使用了视觉、语音和链和编码器并使用三个预训练任务进行优化:Contrastive Frame- caption matching(标题帧匹配) 任务,MLM 任务以及 Temporal Reordering 任务。MERLOT模型能够将图像与时间对应的单词进行匹配,还能依据时间变化推理全局上下文事件。
3.1.7 MERLOT Reserve
MERLOT Reserve [16] 于 2022.5.13 提出,在 2021 年 MERLOT 的基础之上进一步融合了视频中的语音信息,对于每一个训练批次的输入,仅选择文本语音中的一个与视频帧一起作为输入,同时掩蔽文本或语音中的一部分。与此同时,作者们提出了对比区域匹配 (Contrastive Span Matching) 这一任务以在多个模态之间学习文本信息.
3.2 对比学习(Contrastive)方法
对比学习方法通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
3.2.1 CBT
由于 VideoBERT 在视频特征提取过程中采用了层级 k 聚类方法,致使丢失了细粒度视觉信息,Sun 等人进一步研究在同年提出了一种双流网络结构取代了 k 聚类方法的特征提取,该结构首先对语音识别的输入使用 BERT 网络做处理得到文本特征,同时将视频帧使用 S3D 提取特征后送入该工作提出的 CBT 模块(对比学习模块)(contrastive bidirectional transformer) [14] 得到视频特征。将文本特征和视频特征一起输入到 cross-modal transformer进行模态结合计算相似度,同时还使用到了噪声估计来学习视频文本对之间的关系。
3.2.2 MIL-NCE
针对当前数据集的视频文本不对齐现象产生的噪音,Miech 等人于 2019.9.27 提出了多实例学习 (multiple instance learning, MIL) 的方法。该方法假设在同一视频中的相邻帧图像语义相似,截取目标视频段的相邻视频文本对作为对比学习的候选正例。同时利用噪声估计优化了视频文本对特征的学习, 得到了 MIL-NCE [12] 方法.
3.2.3 VATT
Akbari 等人于 2021.4.22 提出的 VATT(video-audiotext transformer)[1] 模型探究了视频、文本、音频三个模态之间的对应关系,同时取消了所有特征提取的 backbone, 仅对每个模态做了线性映射,再将得到的三个模态的特征向量输入到 Transformer 编码器中,而后构造了视频文本对和视频语音对的负样本用来做多模态对比学习。
3.3 特征匹配(Matching)方法
3.3.1 MMT
Gabeur 等人提出了 Multi-modal Transformer [5] 模型,使用 transformer 将图像、语音和文字三种特征结合编码,成功在预训练中引入了更多模态信息 (图4)。
3.3.2 Frozen
Bain 等人于 2021.4.1 提出的 Frozen [3] 模型 (图5) 在预训练过程中使用图像与视频一起作为训练输入。视觉编码器的输入为一张图像或者一段由 M 帧图像组成的视频,文本编码器的输入则是传统的文字序列。模型参考 ViT 方法,图像或视频的输入都是 patch 级别,而后做线性变换,与时空位置编码一起输入到 Transformer 中得到视觉特征。
3.3.3 CLIP4CLIP
CLIP4Clip [11] 来源于视觉-文本领域的 CLIP 工作,作者验证了如何基于预训练好的图文 CLIP 模型,通过迁移学习和微调完成视频检索的任务.
3.3.4 M2HF
于 2022.8.16 发布的 M2HF 模型 (multi- multimodal Hybrid Fusion) [9], 通过建立语言对与从视频中提取的图像、音频、运动和文本之间的关系,设计了多层次的框架. 除此之外,作者还设计了一种后期多模态平衡融合方法,通过在各层次中选择最优排序结果进行融合来得到最终的排序结果。
3.4 其他方法
3.4.1 Multiple Choice Questions(MCQ)
模型结构上包含一个 VideoFormer 编码器用来提取视频特征,一个 TextFormer 文本编码器用来提取文本特征。MCQ [6] 通过抹去文本描述中的名词或动词短语从而构造名词或动词
问题。该工作利用对比学习训练 BridgeFormer 通过分析 VideoFormer 提取到的视频特征以从多个选项中选出正确答案,其中的多个选项由所有被抹去的名词和动词短语构成。
4. 预训练模型的常见下游任务
与视频相关的下游任务如今也发展得十分多样。具体而言,如今涉及到多模态的下游任务包括动作分割、视频描述生成、文本-视频检索、视频问答、视频摘要、视频故事讲述等。这里简单介绍几个常见方向。
动作分割,即对一段视频依据某一分割标准进行分段处理,并对每段分配一个预先定义好的动作标签。视频描述生成,即从视频中自动生成针对该视频的描述性文字。文本-视频检索:通过将视频与文字建立联系,给定查询文本,用相似度估计等方法从视频库中检索与该文本相关的视频段。视频问答,根据视频内容回答自然语言问题,是一项新兴的挑战任务。
5. 总结与展望
本文简单梳理了近年来多模态视频预训练领域的工作,对比了多模态预训练常用的数据集,对历年主要的多模态预训练架构做了介绍,并罗列了常见的下游任务。
目前的多模态预训练工作已取得了一定的成果,能够成功应用于多类下游任务,不过多模态预训练在未来仍有很大发展空间,具体而言:
多模态预训练任务仍需更为精细地挖掘不同模态数据间的相关信息,利用到不同模态的内在特点,比如建立名词与视频中物体对象之间的相关性。
视频信息较为冗余,未来预训练模型的视频帧采样可以更多地从密集采样逐渐向稀疏采样过渡,节省算力,同时如何弥补稀疏采样带来的信息上的损失以及如何提取细粒度的信息也是未来可以研究的方向。
目前多模态视频数据集的收集难度仍然较大,手工标注尤其昂贵,尤其是细粒度标注,所以也急需能解决数据集获取以及标注困难问题的方法。如何在短时间低成本提升数据集的质量也是重要课题之一。
预训练数据集和下游目标任务数据集之间可能存在领域之间的差异,数据域的差异会导致模型迁移到下游任务时性能下降,这就需要想办法提高数据集的差异性以及预训练模型的可泛化性。
虽然大模型往往意味着更高的性能,但参数量和数据量的增加也会导致计算量的急剧上升,极大地消耗了计算资源。因此当前领域也需要更少参数更优性能的研究。
现有视频预训练模型通常是利用少数几个下游任务数据集测试性能,而缺少一个能通用地评估预训练模型的评价指标,用以评估模型的效率和可迁移性。一个通用预训练评估指标
尚待被提出。
目前的视频多模态预训练语言多数以英语为主,而中文等其他语言数据集仍十分缺乏,就当今各大视频网站的实际需求而言,应用于中文视频的预训练模型是一个重要的需求也是未来多模态预训练可以发展的方向之一。