一、什么是数据清洗
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
——百度百科
二、为什么要数据清洗
- 现实生活中,数据并非完美的, 需要进行清洗才能进行后面的数据分析
- 数据清洗是整个数据分析项目最消耗时间的一步
- 数据的质量最终决定了数据分析的准确性
- 数据清洗是唯一可以提高数据质量的方法,使得数据分析的结果也变得更加可靠
三、清洗的步骤(处理工具以python为例)

预处理
一是将数据导入处理工具。通常来说,建议使用数据库,单机跑数搭建MySQL环境即可。如果数据量大(千万级以上),可以使用文本文件存储+Python操作的方式。
二是看数据。这里包含两个部分:一是看元数据,包括字段解释、数据来源、代码表等等一切描述数据的信息;二是抽取一部分数据,使用人工查看方式,对数据本身有一个直观的了解,并且初步发现一些问题,为之后的处理做准备。
导入包和数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
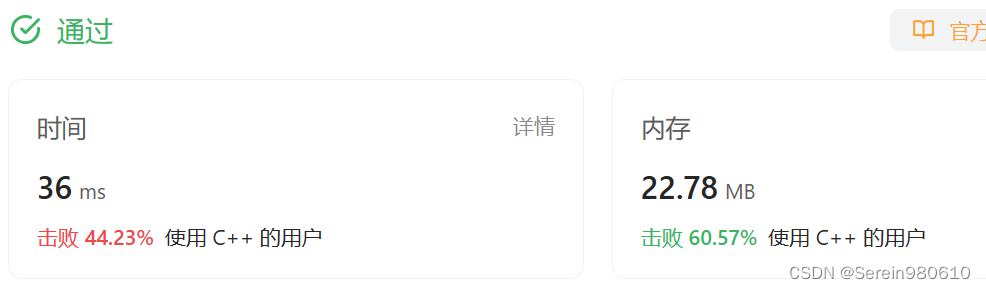
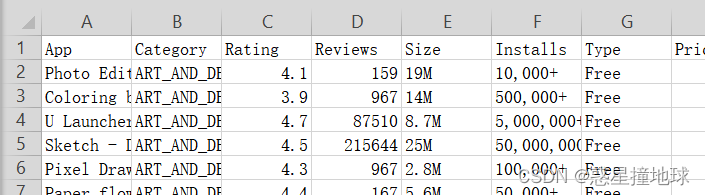
df = pd.read_csv("./dataset/googleplaystore.csv",usecols = (0,1,2,3,4,5,6))print(df.head(1))#浏览表的结构App Category Rating \ 0 Photo Editor & Candy Camera & Grid & ScrapBook ART_AND_DESIGN 4.1 Reviews Size Installs Type 0 159 19M 10,000+ Free
print(df.shape)#行列数量(10841, 7)
print(df.count())#各个列的非空数据量App 10841
Category 10841
Rating 9367
Reviews 10841
Size 10841
Installs 10841
Type 10840
dtype: int64
print(df.describe())#数据统计分析(数据的范围、大小、波动趋势)Rating
count 9367.000000
mean 4.193338
std 0.537431
min 1.000000
25% 4.000000
50% 4.300000
75% 4.500000
max 19.000000
阶段一:去除/补全有缺失的数据
1、确定缺失值范围:对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略确定。
2、去除不需要的字段:这一步很简单,直接删掉即可。
3、填充缺失内容:某些缺失值可以进行填充,Pandas方法通常有以下几种:
-
填充具体数值,通常是0
-
填充某个统计值,比如均值、中位数、众数等
-
填充前后项的值
-
基于SimpleImputer类的填充
-
基于KNN算法的填充
阶段二:去除/修改格式和内容错误的数据
1、时间、日期、数值、全半角等显示格式不一致
#时间转换
import datetime
date_str = '2023-09-11'
date_obj = datetime.datetime.strptime(date_str, '%Y-%m-%d')
formatted_date_str = date_obj.strftime('%m/%d/%Y')
print("转换结果:" + formatted_date_str)转换结果:09/11/2023字符
num_str = '123.4567'
num_float = float(num_str)
formatted_num_str = "{:.2f}".format(num_float)
print("转换结果:"+formatted_num_str)转换结果:123.46
2、内容与该字段应有内容不符
原始数据填写错误,并不能简单的以删除来处理,因为成因有可能是人工填写错误,也有可能是前端没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型。
阶段三:去除/修改逻辑错误的数据
1、去重
有的分析师喜欢把去重放在第一步,但我强烈建议把去重放在格式内容清洗之后,原因已经说过了(多个空格导致工具认为“陈丹奕”和“陈 丹奕”不是一个人,去重失败)。而且,并不是所有的重复都能这么简单的去掉……
我曾经做过电话销售相关的数据分析,发现销售们为了抢单简直无所不用其极……举例,一家公司叫做“ABC管家有限公司“,在销售A手里,然后销售B为了抢这个客户,在系统里录入一个”ABC官家有限公司“。你看,不仔细看你都看不出两者的区别,而且就算看出来了,你能保证没有”ABC官家有限公司“这种东西的存在么……这种时候,要么去抱RD大腿要求人家给你写模糊匹配算法,要么肉眼看吧。
当然,如果数据不是人工录入的,那么简单去重即可。
2、去除不合理值
一句话就能说清楚:有人填表时候瞎填,年龄200岁,年收入100000万(估计是没看见”万“字),这种的就要么删掉,要么按缺失值处理。这种值如何发现?提示:可用但不限于箱形图(Box-plot).
3、修正矛盾内容
有些字段是可以互相验证的,举例:身份证号是1101031980XXXXXXXX,然后年龄填18岁,我们虽然理解人家永远18岁的想法,但得知真实年龄可以给用户提供更好的服务啊(又瞎扯……)。在这种时候,需要根据字段的数据来源,来判定哪个字段提供的信息更为可靠,去除或重构不可靠的字段。
逻辑错误除了以上列举的情况,还有很多未列举的情况,在实际操作中要酌情处理。另外,这一步骤在之后的数据分析建模过程中有可能重复,因为即使问题很简单,也并非所有问题都能够一次找出,我们能做的是使用工具和方法,尽量减少问题出现的可能性,使分析过程更为高效。
阶段四:去除不需要的数据
这一步说起来非常简单:把不要的字段删了。
但实际操作起来,有很多问题,例如:
把看上去不需要但实际上对业务很重要的字段删了;
某个字段觉得有用,但又没想好怎么用,不知道是否该删;
一时看走眼,删错字段了。
前两种情况我给的建议是:如果数据量没有大到不删字段就没办法处理的程度,那么能不删的字段尽量不删。第三种情况,请勤备份数据……
阶段五:关联性验证
如果你的数据有多个来源,那么有必要进行关联性验证。
例如,你有汽车的线下购买信息,也有电话客服问卷信息,两者通过姓名和手机号关联,那么要看一下,同一个人线下登记的车辆信息和线上问卷问出来的车辆信息是不是同一辆,如果不是(别笑,业务流程设计不好是有可能出现这种问题的!),那么需要调整或去除数据。