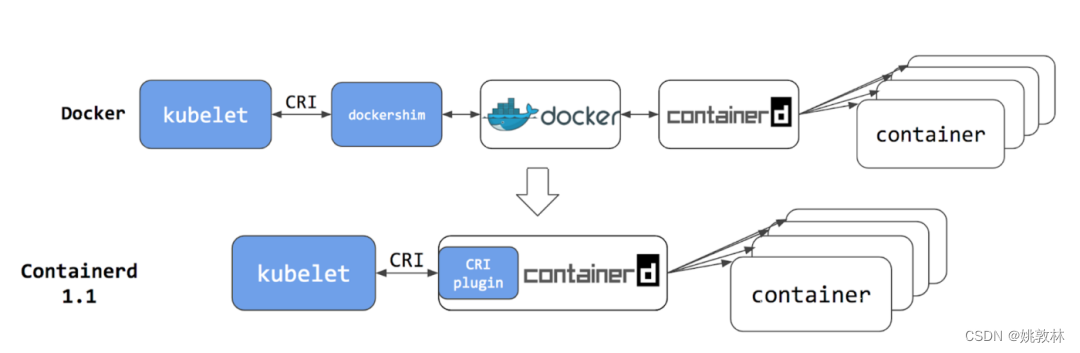
随着大数据和人工智能技术的快速发展,对于大规模数据的处理需求日益增多。NoSQL数据库作为一种新兴的数据存储解决方案,具有高可扩展性、高性能和灵活性数据模型等优势,已经在许多行业得到广泛应用。传统的关系型数据库在处理海量数据时可能会遇到性能瓶颈,而NoSQL数据库则提供了一种可扩展性强、适用于非数据重构的解决方案。本文将介绍如何使用Python将网页数据保存到NoSQL数据库,并提供相应的代码示例。
我们的目标是开发一个简单的Python库,使用户能够轻松地将网页数据保存到NoSQL数据库中。通过提供示例代码和详细的文档,我们希望能够帮助开发人员快速上手并评估实际项目中。
在将网页数据保存到NoSQL数据库的过程中,我们面临以下问题:
- 如何从网页中提取所需的数据?
- 如何与NoSQL数据库建立连接并保存数据?
- 如何使用代理信息以确保数据采集的顺利进行?
为了解决上述问题,我们提出以下方案:
- 使用Python的爬虫库(如BeautifulSoup)来提取网页数据。
- 使用Python的NoSQL数据库驱动程序(如pymongo)来与NoSQL数据库建立连接并保存数据。
- 使用代理服务器来处理代理信息,确保数据采集的顺利进行。
以下是一个示例代码,演示了如何使用Python将网页数据保存到NoSQL数据库中,
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
# 代理参数来自亿牛云代理
proxyHost = "u6205.5.tp.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"
# 设置代理
proxies = {
"http": f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}",
"https": f"https://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"
}
# 网页请求
url = "https://example.com"
response = requests.get(url, proxies=proxies)
# 解析网页数据
soup = BeautifulSoup(response.text, "html.parser")
data = soup.find("div", class_="data").text
# 连接NoSQL数据库
client = MongoClient("mongodb://localhost:27017/")
db = client["mydatabase"]
collection = db["mycollection"]
# 保存数据到NoSQL数据库
document = {"data": data}
collection.insert_one(document)
# 打印保存结果
print("数据保存成功!")
通过以上记录开发,我们可以轻松导入网页数据保存到NoSQL数据库中,并且可以根据实际需求进行修改和扩展,以适应不同的项目要求。该技术可以帮助我们实现数据的持久化存储,并为后续的数据查询和分析提供方便。