目前在用深度学习训练,训练中设置batch size后可以正常跑通,但是在训练一轮save_model时,总出现这个错误,即使我调batch size到1也依旧会报错。
发现是在 调用logger时出现问题。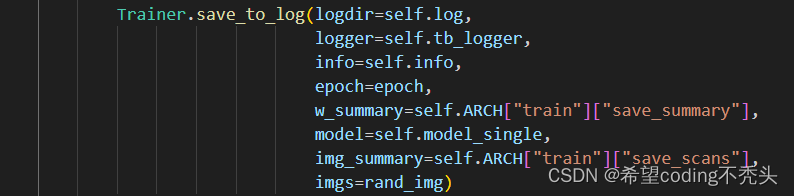
查询后了解到是因为TensorFlow中的eager_execution默认调用最大GPU(但我的GPU显存不足以满足需求,所以报错)。经过查询,再logger.py调用tf处,加入
os.environ["CUDA_VISIBLE_DEVICES"]="1" #选择你使用的GPU
tf.compat.v1.disable_eager_execution() #禁用_eager_execution
config=tf.compat.v1.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.9 #阈值,TensorFlow 会话在执行时最多占用 90% 的 GPU 显存。
sess=tf.compat.v1.Session(config=config) # 创建一个 TensorFlow 会话 sess,并传入配置对象 config。这样会话就会按照指定的配置创建和执行。随后解决问题。