如果你曾经搭建过自己的网站,那么你一定对网络爬虫感到无比的烦恼。这些爬虫每天都在大量的访问你的网站,频繁且毫无节制地消耗你的服务器资源。那么,今天我们就来探讨一下,如何“干死”这些爬虫的服务器。
注意:本文所讨论的内容仅供技术交流,不涉及任何违法行为。
首先,我们需要明确一点:如果一个爬虫每天都在访问你的网站,那么你一定有一些方法来识别出这个爬虫。最常见的方法就是通过分析请求的来源IP或者User Agent。一旦你能够确定一个请求是来自爬虫,你就可以开始给你的爬虫上一课了。
我们知道,很多网络爬虫都是使用Python的Requests库来发送网络请求的。如果你仔细阅读过Requests的文档,那么你可能已经注意到,Requests会自动处理gzip和deflate等传输编码的解码。
当你的网站使用gzip对一些较大的资源进行压缩后传输时,客户端(如浏览器或Requests库)在接收到返回的数据后会自动进行解压缩。这个过程对用户来说是透明的,不需要他们手动进行解压缩。
这个功能原本是为了方便开发者而设计的,但我们可以反过来利用这个特性来“玩弄”那些爬虫。以下是如何在Python中使用这个方法来测试返回gzip压缩数据的方法:
在HTTP响应中使用gzip压缩数据时,要确保在响应头中包含正确的Content-Encoding头。在这种情况下,我们故意将Content-Encoding设置为gzip,但实际上我们并不真正对数据进行压缩。这样做的目的是为了让爬虫误以为我们返回的数据是经过gzip压缩的。
当爬虫收到这个响应后,它会自动对数据进行解压缩。然而,因为实际上数据并没有被压缩,所以解压缩操作将无法正常进行。这样,爬虫最终得到的数据将是一片混乱,毫无用处。
通过这种方式,我们可以让爬虫浪费大量的CPU资源去尝试解压根本就没有被压缩的数据。如果这个方法被大规模地实施,那么爬虫的服务器将会被大量的无效解压缩操作拖垮,最终达到“干死”它们服务器的目的。
当然了,在实际操作中,我们还需要考虑一些其他的因素,例如如何防止误伤非爬虫的客户端、如何在实施这种策略的同时不影响正常用户的访问体验等。但是,这个方法至少可以作为一个起点,帮助我们更好地对抗那些无良的网络爬虫。
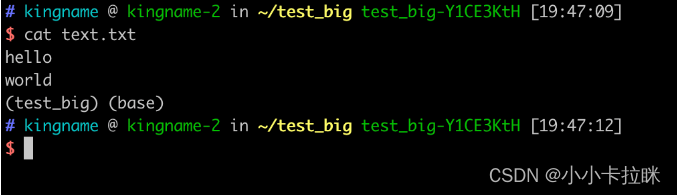
我首先在硬盘上创建一个文本文件text.txt,里面有两行内容,如下图所示:
然后,我是用gzip命令把它压缩成一个.gz文件:
cat text.txt | gzip > data.gz
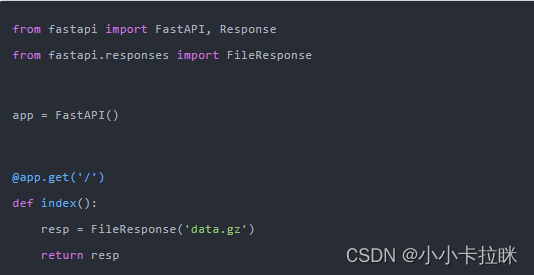
接下来,我们使用FastAPI写一个HTTP服务器server.py:
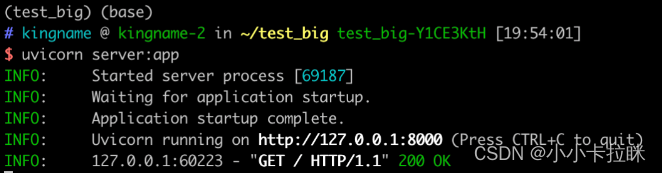
然后使用命令uvicorn server:app启动这个服务。
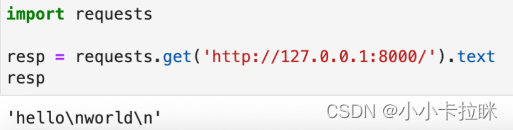
接下来,我们使用requests来请求这个接口,会发现返回的数据是乱码,如下图所示:

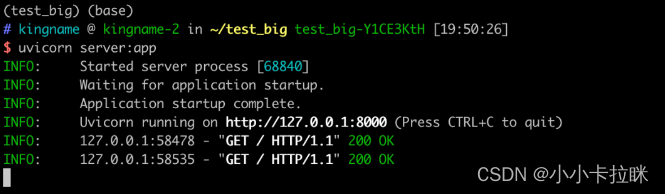
返回的数据是乱码,这是因为服务器没有告诉客户端,这个数据是gzip压缩的,因此客户端只有原样展示。由于压缩后的数据是二进制内容,强行转成字符串就会变成乱码。
现在,我们稍微修改一下server.py的代码,通过Headers告诉客户端,这个数据是经过gzip压缩的:
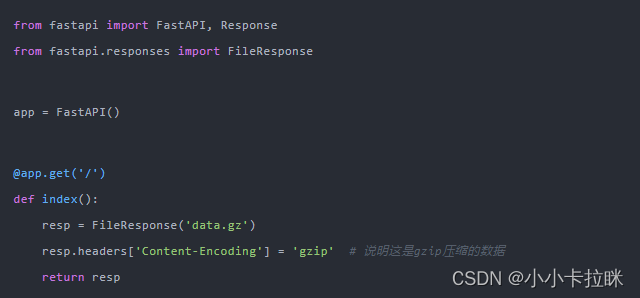
修改以后,重新启动服务器,再次使用requests请求,发现已经可以正常显示数据了:
这段代码的演示已经让我们领略了服务器如何告知客户端返回数据是经过gzip压缩的。那么,我们如何利用好这个功能呢?这就需要深入理解一下压缩文件的原理。
你知道吗?文件之所以可以被压缩,其实是因为它们里面有很多重复的元素。而压缩算法,就是通过一种巧妙的方式来找出并简化这些重复,从而使文件变得更小。当然,不同的压缩算法有不同的实现方式和效果。但我们可以用一个简单的小例子来形象地说明它是如何工作的。

咱们来想象一下,假如有一串192个字符的文本,里面全是“1”,这时我们用5个字符来表示它:“192个1”。哈哈,是不是超级省空间,压缩率高达惊人的97.4%!
再想象一下,如果有一个1GB的文件,我们把它压缩成1MB,那是不是意味着服务器只需要返回1MB的二进制数据就行了?这对服务器来说当然毫无压力。但问题是,当客户端或爬虫拿到这个1MB的数据后,它会在内存中解压成原来的大小,也就是1GB。结果就是,爬虫占用的内存瞬间增加了1GB!要是原始数据再大点,搞不好就直接把爬虫所在服务器的内存给榨干了。可不是闹着玩的,轻则服务器直接干掉爬虫进程,重则直接死机!
你可能会想,这个压缩比会不会太不靠谱了?告诉你,其实要生成这种压缩文件,我们只需要简单输入一行命令就行,真的有这么神奇!
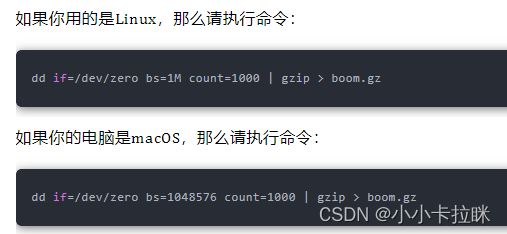
执行结果如下

生成的这个boom.gz文件只有995KB。但是如果我们使用gzip -d boom.gz对这个文件解压缩,就会发现生成了一个1GB的boom文件,如下图所示:
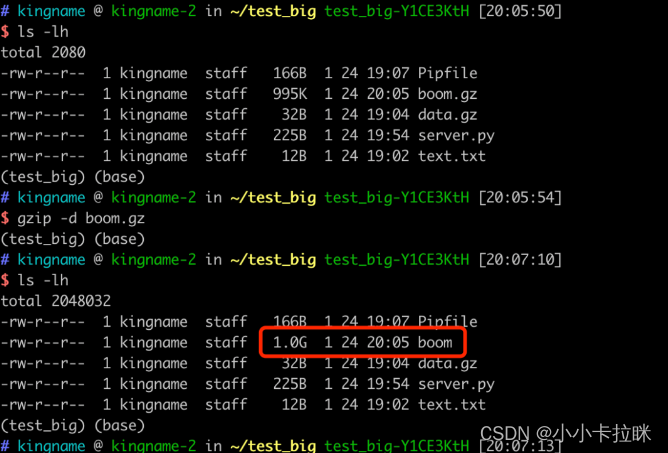
只要大家把命令里面的count=1000改成一个更大的数字,就能得到更大的文件。
我现在把count改成10,给大家做一个演示(不敢用1GB的数据来做测试,害怕我的Jupyter崩溃)。生成的boom.gz文件只有10KB:

服务器返回一个10KB的二进制数据,没有任何问题。
现在我们用requests去请求这个接口,然后查看一下resp这个对象占用的内存大小:.
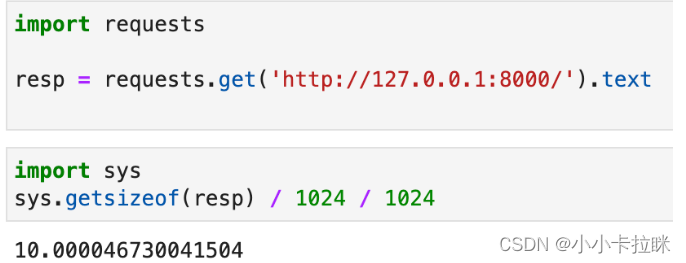
可以看出,由于requests库会自动对返回数据进行解压缩,所以最终得到的resp对象竟然有10MB之多!
大家在使用这种方法时,一定要先确定请求确实是爬虫发出的,再使用哦。否则,不慎把真实用户误认为是爬虫,那就麻烦了。