目录
1.join/left join/full join 语句会过滤关联字段 null 的值吗?
(1)join
(2) left join /full join
2.group by 分组语句会进行排序吗?
1.join/left join/full join 语句会过滤关联字段 null 的值吗?
(1)join
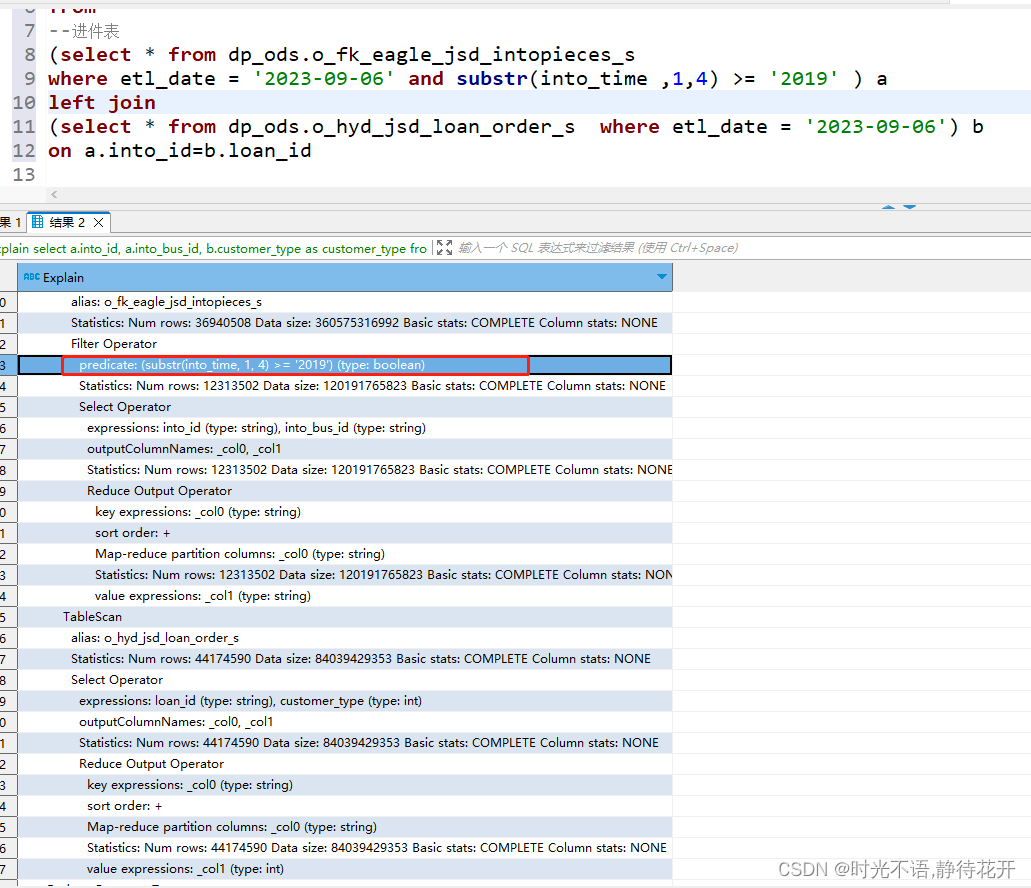
sql:
explain
select
a.into_id,
a.into_bus_id,
b.customer_type as customer_type
from
--进件表
(select * from dp_ods.o_fk_eagle_jsd_intopieces_s
where etl_date = '2023-09-06' and substr(into_time ,1,4) >= '2019' ) a
join
(select * from dp_ods.o_hyd_jsd_loan_order_s where etl_date = '2023-09-06') b
on a.into_id=b.loan_id
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: o_fk_eagle_jsd_intopieces_s
Statistics: Num rows: 36940508 Data size: 360575316992 Basic stats: COMPLETE Column stats: NONE
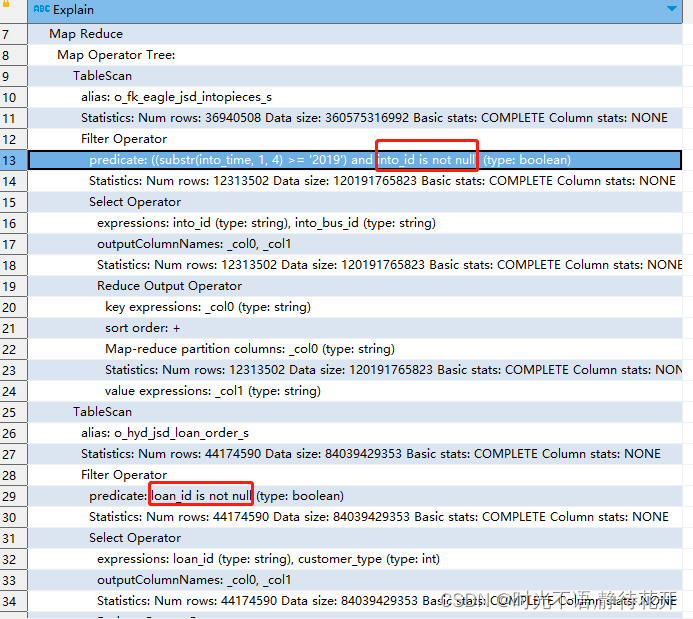
Filter Operator
predicate: ((substr(into_time, 1, 4) >= '2019') and into_id is not null) (type: boolean)
Statistics: Num rows: 12313502 Data size: 120191765823 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: into_id (type: string), into_bus_id (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 12313502 Data size: 120191765823 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 12313502 Data size: 120191765823 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string)
TableScan
alias: o_hyd_jsd_loan_order_s
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: loan_id is not null (type: boolean)
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: loan_id (type: string), customer_type (type: int)
outputColumnNames: _col0, _col1
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: int)
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: string)
1 _col0 (type: string)
outputColumnNames: _col0, _col1, _col3
Statistics: Num rows: 48592050 Data size: 92443374291 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: string), _col3 (type: int)
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 48592050 Data size: 92443374291 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 48592050 Data size: 92443374291 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
可以看到filter 顾虑部分有比原sql多了关联字段不为空的判断
(2) left join /full join
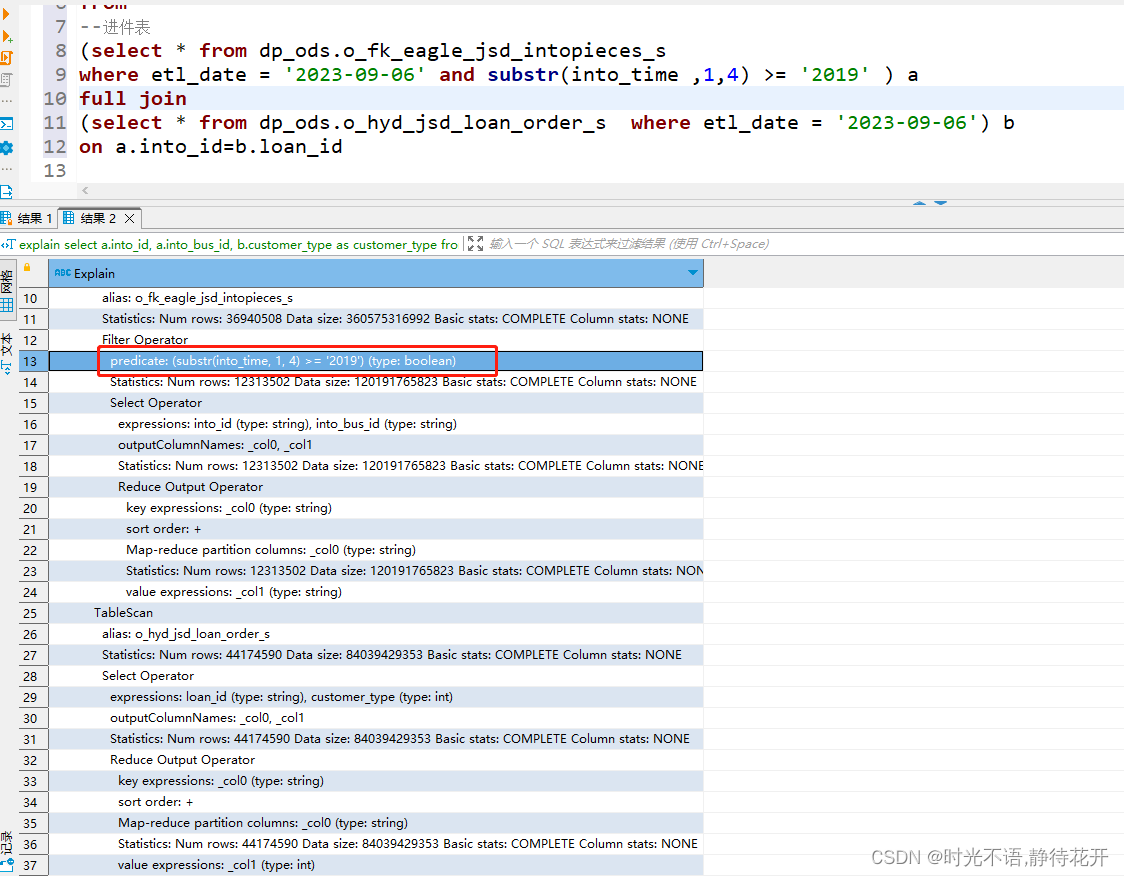
没有相关的过滤空值操作
2.group by 分组语句会进行排序吗?
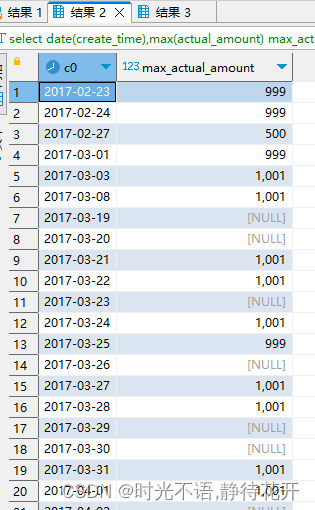
explain
select date(create_time),max(actual_amount) max_actual_amount
from dp_ods.o_hyd_jsd_loan_order_s
where etl_date = '2023-09-06'
group by date(create_time)STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 depends on stages: Stage-2
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: o_hyd_jsd_loan_order_s
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: CAST( create_time AS DATE) (type: date), actual_amount (type: double)
outputColumnNames: _col0, _col1
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: max(_col1)
keys: _col0 (type: date)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: date)
sort order: +
Map-reduce partition columns: rand() (type: double)
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double)
Reduce Operator Tree:
Group By Operator
aggregations: max(VALUE._col0)
keys: KEY._col0 (type: date)
mode: partials
outputColumnNames: _col0, _col1
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-2
Map Reduce
Map Operator Tree:
TableScan
Reduce Output Operator
key expressions: _col0 (type: date)
sort order: +
Map-reduce partition columns: _col0 (type: date)
Statistics: Num rows: 44174590 Data size: 84039429353 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double)
Reduce Operator Tree:
Group By Operator
aggregations: max(VALUE._col0)
keys: KEY._col0 (type: date)
mode: final
outputColumnNames: _col0, _col1
Statistics: Num rows: 22087295 Data size: 42019714676 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 22087295 Data size: 42019714676 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink

可以看到group by 字段是进行了正序排序的,查看sql执行结果也能看到。