iterator 优先于 const_iterator, reverse_iterator, const_reverse_iterator
STL中所有标准容器都提供了标题提到的四种迭代器类型。对于容器container<T>而言,iterator类型相当于T*,const_iterator类型相当于const T*,剩下两个是反向迭代器的普通类型和const类型。
对于vector<T>容器中的insert和erase来说,insert和erase的函数原型如下
iterator insert(iterator position, const T& x);
iterator erase(iterator position);
iterator erase(iterator rangeBegin, iterator rangeEnd);
每个标准容器都有类似的函数,只不过返回值类型可能有所不同。但是这些函数都只接收iterator类型的参数。
四种迭代器的关系如下图所示

从图中看出,从iterator到const_iterator,和从reverse_iterator到const_reverse_iterator均可以通过隐式类型转换得到;而从reverse_iterator到iterator,和从const_reverse_iterator均可以通过调用base成员函数得到。
当在iterator和const_iterator中选择时,优先选择iterator,不仅仅因为iterator可以用于更多的成员函数,还因为iterator和const_iterator混用时会产生一些问题:
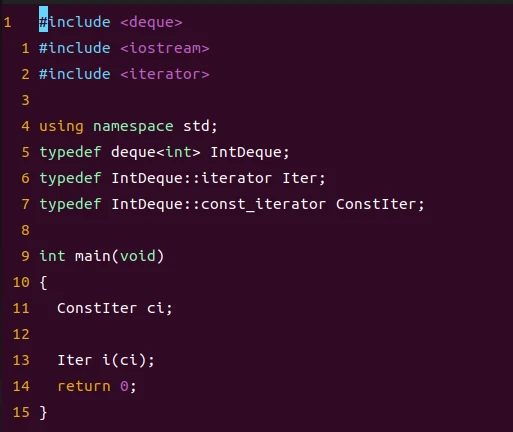
typedef deque<int> IntDeque;
typedef IntDeque::iterator Iter;
typedef IntDeque::const_iterator ConstIter;
Iter i;
ConstIter ci;
// ...
if (i == ci) ... // 比较一个iterator和const_iterator
真正比较的时候,应该需要把iterator隐式转换成const_iterator,但是如果在某些STL的实现中,const_iterator重载的operator==运算符被实现为成员函数的话,等于号左边必须为函数的调用方,但是这种情况下调用方在等于号右边,所以就会编译错误。如果operator==被重载为非成员函数的话就不会有这样的问题。
不仅仅是判等,在同一个表达式中混用iterator和const_iterator就会产生上面的问题,比如试图在两个迭代器之间相减时:
if (i - ci >= 3) ... // 如果i和ci之间至少有三个元素
这个表达式同样有可能产生编译错误,我们可以用下面的表达式来替代
if (ci + 3 <= i) ...
但是这样又产生了新的问题,迭代器ci + 3并不总是有效的,它可能超过了容器的范围。
所以显然在两种迭代器之间抉择的时候,选择iterator可以避免很多不必要的问题。
使用distance和advance将const_iterator转换成iterator
使用强制类型转换是行不通的,像下面的代码是无法通过编译的
因为从const_iterator到iterator并没有隐式类型转换的途径,那么如果该用下面这句话呢
Iter i(const_cast<Iter>(ci));
仍然会产生编译错误,因为针对deque来说,iterator和const_iterator是完全不同的类,进行强制类型转换是完全没有意义的。对于vector/string类来说,强制类型转换的方法可能会通过编译,因为对于这两个容器的大部分实现来说,iterator和const_iterator通过T*和const T*来实现,但是在这样的实现下,将const_reverse_iterator和reverse_iterator还是两个完全不同的类。
正确的思路如下
IntDeque d;
ConstIter ci;
// ci指向d的某个位置
Iter i(d.begin());
advance(i, distance(i, ci)); // 移动i指向ci的位置
但是上面的代码还是不能通过编译,distance的声明如下
template<typename InputIterator>
typename iterator_traits<InputIterator>::difference_type
distance(InputIterator first, InputIterator last);
可以发现first和last是两个相同的类型,这就导致了模版实例化的时候会产生二义性,为了消除二义性,我们手动指定模版参数即可
advance(i, distance<ConstIter>(i, ci));
这次就可以通过编译了。
但是对于非随机访问的迭代器来说,将const_iterator转换为iterator需要线性的时间,所以在一开始还是尽量使用iterator来代替const_iterator。
正确理解reverse_iterator的base()产生的iterator
从reverse_iterator的base()产生的iterator并不指向同一个元素,在下面的代码中
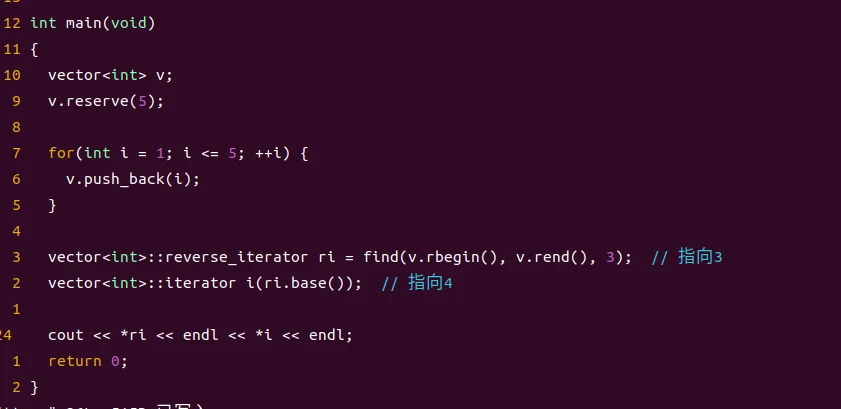
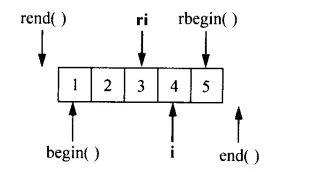
所以在使用base产生的iterator的时候就需要考虑偏移产生的影响。
-
当执行插入操作时,使用
base产生的i作为位置传入insert中,会在i的前面插入一个新的元素,新插入的元素在逆序遍历时正好处在期望的位置
放到上面的图示中,实际上就是在3,4之间插入了一个新元素 -
如果要删除
ri指向的元素时,直接使用ri.base()就不对了,应该的使用方法是v.erase(--ri.base());书中说这行代码编译不通过,但是我测试是可以的,在网上也没有找到答案,书中建议的做法如下
v.erase((++ri).base());
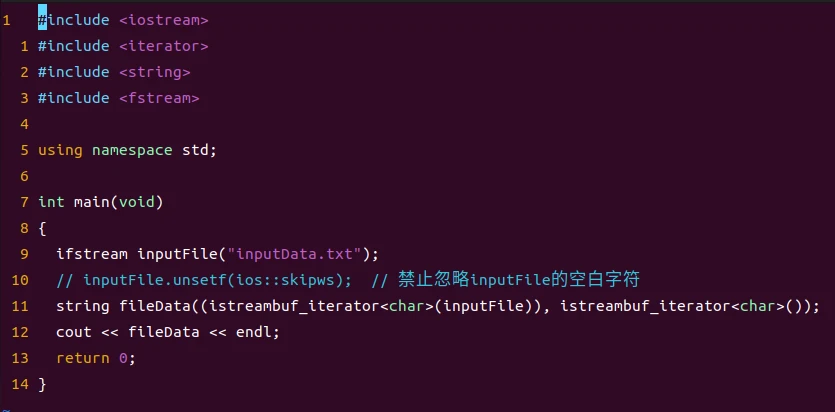
对逐个字符的输入考虑使用istreambuf_iterator
如果想要把一个文本文件内容拷贝到一个string对象中,下面是一种看上去比较合理的解决方法

但是这段代码并没有把文件中的空白字符读进去
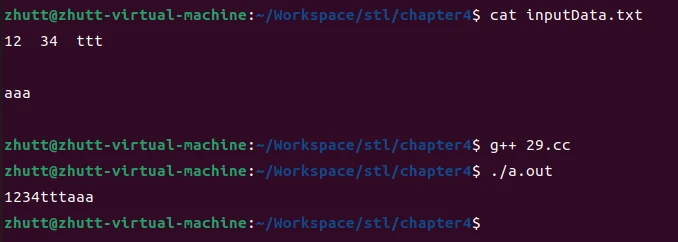
这是因为istream_iterator使用operator>>函数来完成实际的读操作,而默认情况下operator>>会跳过空白字符。
假如需要跳过空白字符,我们可以通过某些操作来改变默认行为
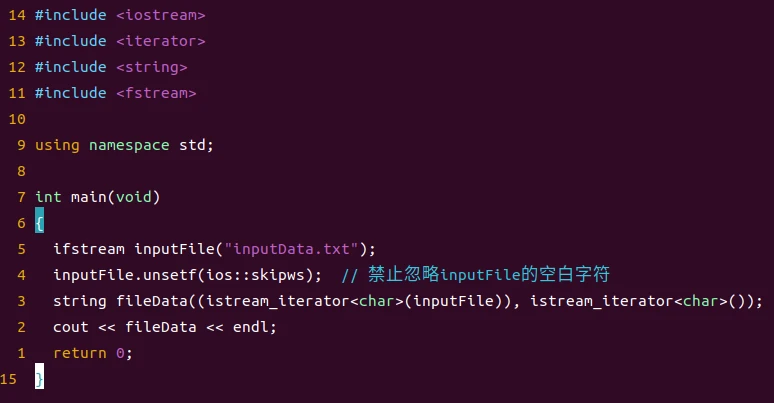
这样就可以正确读入空白字符了。
但是这样效率比较低,反复调用operator>>会有很大的开销,我们可以使用istreambuf_iterator来替代istream_iterator。istreambuf_iterator<char>直接从流的缓冲区读取一个字符,我们只需要把代码改成下面这样,就既可以读取空白字符,而且效率还更高