M3E&ChatGLM向量化构建本地知识库
- 整体步骤
- 向量数据库
- 向量数据库简介
- 主流数据库
- Milvus部署
- 文本向量化
- M3E介绍
- 模型对比
- M3E使用
- 向量数据存储
- 基于本地知识库的问答
- 问句向量化
- 向量搜索
- 请求ChatGLM
- 问答测试
整体步骤
- 向量化:首先,你需要将语言模型的数据转化为向量。这通常通过嵌入模型(embedding models)完成,比如word2vec,GloVe,或者BERT等,这些模型可以将文本数据转化为向量形式。
- 存储:向量化后的数据可以存储在向量数据库中。向量数据库提供了一种高效的方式来存储和索引大量的向量数据。
- 查询:存储在向量数据库中的向量可以通过向量空间中的搜索和比较操作来查询。例如,你可以通过查找与给定向量最相近的向量来找到与给定文本最相关的文本。
向量数据库
向量数据库简介
向量数据库是一种特殊类型的数据库,它用于存储和处理向量数据。向量数据库的主要特点是能够高效地执行向量空间中的搜索和比较操作,比如最近邻搜索(nearest neighbor search)。向量数据库在许多领域都有应用,包括机器学习、人工智能、计算机视觉和自然语言处理等。
主流数据库
- Faiss:Faiss是Facebook AI研究所开发的一种用于高效相似度搜索和聚类的库。它可以处理大量数据,并且支持在GPU上运行。
- Annoy (Approximate Nearest Neighbors Oh Yeah):Annoy是Spotify开发的一种用于大规模近似最近邻搜索的C++库。Annoy的优点是它支持动态添加向量,这对于需要不断更新数据的应用来说非常有用。
- Milvus:Milvus是一款开源的向量数据库,支持在线向量相似度搜索和向量聚类。它提供了丰富的API接口,可以方便地与其他系统进行集成。
- Pinecone:Pinecone是一款托管型向量搜索服务,提供全托管的向量搜索引擎,用于构建和部署大规模向量搜索应用。
这里我们选择Milvus。
Milvus部署
Milvus是基于Docker部署的,你的Docker需要符合以下条件:
- Docker 版本 > 19.03 部署docker
- Docker Compose 版本 > 1.25.1 安装Compose
1、下载保存docker-compose.standalone.yml并保存为docker-compose.yml:
wget https://github.com/milvus-io/milvus/releases/download/v2.2.12/milvus-standalone-docker-compose.yml -O docker-compose.yml
2、启动单节点
docker-compose up -d
3、通过命令确定单节点安装完成
[root@slave2 docker]# sudo docker-compose psName Command State Ports
--------------------------------------------------------------------------------------
milvus-etcd etcd -listen-peer-urls=htt ... Up (healthy) 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Exit 132
4、关闭Milvus
docker-compose down
5、启动Milvus
docker-compose up -d
文本向量化
M3E介绍
M3E Models :Moka(北京希瑞亚斯科技)开源的系列文本嵌入模型。
模型地址:
https://huggingface.co/moka-ai/m3e-base
M3E Models 是使用千万级 (2200w+) 的中文句对数据集进行训练的 Embedding 模型,在文本分类和文本检索的任务上都超越了 openai-ada-002 模型(ChatGPT 官方的模型)。
M3E 是 Moka Massive Mixed Embedding 的缩写
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
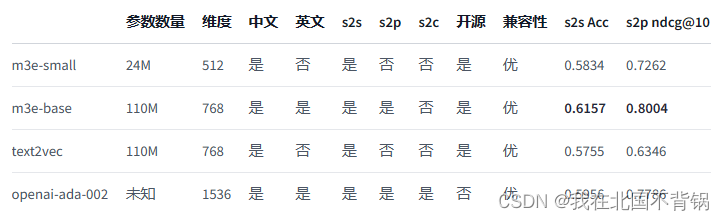
模型对比
M3E使用
1、首先需要先安装 sentence-transformers
pip install -U sentence-transformers
2、安装完成后,您可以使用以下代码来使用 M3E Models
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
3、这里,我使用flask框架,将M3E以API的对外提供接口服务
import flask
from flask import Flask
import logging
from sentence_transformers import SentenceTransformer
app = Flask(__name__)
# 配置日志级别和输出格式
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
@app.route('/embeddings',methods=['post'])
def embeddings():
sentences = flask.request.form['text']
model = SentenceTransformer('moka-ai_m3e-base')
embeddings = model.encode(sentences)
#print(embeddings)
return embeddings.tolist()
if __name__ == '__main__':
app.debug = False
handler = logging.FileHandler('flask.log')
app.logger.addHandler(handler)
app.run(port=5000, debug=False, host='0.0.0.0')
4、使用POST请求访问http://xxx.xxx.xxx.xxx:5000/embeddings即可将文本转换为向量集合。
向量数据存储
1、创建Java springboot项目,添加maven依赖:
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.2.1</version>
</dependency>
2、在向量数据库中创建库pdf_data
@Test
void prepare() {
dropCollection(milvusClient);
createCollection(milvusClient);
buildIndex(milvusClient);
}
void buildIndex(MilvusServiceClient client){
final String INDEX_PARAM = "{\"nlist\":1024}";
client.createIndex(
CreateIndexParam.newBuilder()
.withCollectionName("pdf_data")
.withFieldName("content_vector")
.withIndexType(IndexType.IVF_FLAT)
.withMetricType(MetricType.L2)
.withExtraParam(INDEX_PARAM)
.withSyncMode(Boolean.FALSE)
.build()
);
}
void dropCollection(MilvusServiceClient client){
client.dropCollection(
DropCollectionParam.newBuilder()
.withCollectionName("pdf_data")
.build()
);
}
void createCollection(MilvusServiceClient client){
FieldType fieldType1 = FieldType.newBuilder()
.withName("id")
.withDataType(DataType.Int64)
.withPrimaryKey(true)
.withAutoID(true)
.build();
FieldType fieldType2 = FieldType.newBuilder()
.withName("content_word_count")
.withDataType(DataType.Int32)
.build();
FieldType fieldType3 = FieldType.newBuilder()
.withName("content")
.withDataType(DataType.VarChar)
.withMaxLength(1024)
.build();
FieldType fieldType4 = FieldType.newBuilder()
.withName("content_vector")
.withDataType(DataType.FloatVector)
.withDimension(768)
//.withDimension(1536)
.build();
CreateCollectionParam createCollectionReq = CreateCollectionParam.newBuilder()
.withCollectionName("pdf_data")
.withShardsNum(4)
.addFieldType(fieldType1)
.addFieldType(fieldType2)
.addFieldType(fieldType3)
.addFieldType(fieldType4)
.build();
client.createCollection(createCollectionReq);
}
3、根据不同的文档类型,解析得到文档知识字符串。
/**
* 文件上传,支持PDF、Word、Xmind
* @param file
* @throws Exception
*/
@PostMapping("/upload")
public void upload(MultipartFile file) throws Exception {
List<String> sentenceList = new ArrayList<>();
String fileSuffix = file.getOriginalFilename().substring(file.getOriginalFilename().lastIndexOf("."));
if (Constants.PDF.equalsIgnoreCase(fileSuffix)){
sentenceList = PdfParseUtil.parse(file.getInputStream());
}
if (Constants.DOCX.equalsIgnoreCase(fileSuffix)){
sentenceList = WordParseUtil.getContentDocx(file.getInputStream());
}
if (Constants.DOC.equalsIgnoreCase(fileSuffix)){
sentenceList = WordParseUtil.getContentDoc(file.getInputStream());
}
if (Constants.XMIND.equalsIgnoreCase(fileSuffix)){
sentenceList = XmindUtil.xmindToList(file.getInputStream());
}
chatService.save(sentenceList);
}
然后将文本知识转换为向量数据。
public void save(List<String> sentenceList){
List<Integer> contentWordCount = new ArrayList<>();
List<List<Float>> contentVector = new ArrayList<>();
for(String str : sentenceList){
contentWordCount.add(str.length());
}
contentVector = embeddingModel.doEmbedding(sentenceList);
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field("content", sentenceList));
fields.add(new InsertParam.Field("content_word_count", contentWordCount));
fields.add(new InsertParam.Field("content_vector", contentVector));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName("pdf_data")
.withFields(fields)
.build();
//插入数据
milvusClient.insert(insertParam);
}
基于本地知识库的问答
问句向量化
调用python的M3E接口服务,返回问句的向量化数据
/**
* 通过python服务请求获取Embeddings,请求出错返回null
* @param msg
* @return
*/
public List<Float> doEmbedding(String msg){
List<Float> floats = new ArrayList<>();;
try {
//表单数据参数填入
RequestBody body = new FormBody.Builder().add("text", msg).build();
Request request = new Request.Builder()
//这里必须手动设置为json内容类型
.addHeader("content-type", "multipart/form-data")
//参数放到链接后面
.url(embeddingUrl)
.post(body)
.build();
Response response = openAiHttpClient.newCall(request).execute();
if(response.code() == 200){
String string = response.body().string().replace("[","").replace("]","");
Arrays.stream(string.split(",")).forEach(num->floats.add(Float.parseFloat(num)));
}
}catch (Exception e){
e.printStackTrace();
}
return floats;
}
向量搜索
传入问句向量数据,在向量数据库中进行搜索,得到存储到向量数据库中与之最为匹配的文本知识。
/**
* 从向量数据库中搜索
* @param search_vectors
* @return
*/
private List<PDFData> search(List<List<Float>> search_vectors){
milvusClient.loadCollection(
LoadCollectionParam.newBuilder()
.withCollectionName("pdf_data")
.build()
);
final Integer SEARCH_K = 4;
final String SEARCH_PARAM = "{\"nprobe\":10}";
List<String> ids = Arrays.asList("id");
List<String> contents = Arrays.asList("content");
List<String> contentWordCounts = Arrays.asList("content_word_count");
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName("pdf_data")
.withConsistencyLevel(ConsistencyLevelEnum.STRONG)
.withOutFields(ids)
.withOutFields(contents)
.withOutFields(contentWordCounts)
.withTopK(SEARCH_K)
.withVectors(search_vectors)
.withVectorFieldName("content_vector")
.withParams(SEARCH_PARAM)
.build();
R<SearchResults> respSearch = milvusClient.search(searchParam);
List<PDFData> pdfDataList = new ArrayList<>();
if(respSearch.getStatus() == R.Status.Success.getCode()){
//respSearch.getData().getStatus() == R.Status.Success
SearchResults resp = respSearch.getData();
//判断是否查到结果
if(!resp.hasResults()){
return new ArrayList<>();
}
for (int i = 0; i < search_vectors.size(); ++i) {
SearchResultsWrapper wrapperSearch = new SearchResultsWrapper(resp.getResults());
List<Long> id = (List<Long>) wrapperSearch.getFieldData("id", 0);
List<String> content = (List<String>) wrapperSearch.getFieldData("content", 0);
List<Integer> contentWordCount = (List<Integer>) wrapperSearch.getFieldData("content_word_count", 0);
PDFData pdfData = new PDFData(id.get(0),content.get(0),contentWordCount.get(0));
pdfDataList.add(pdfData);
}
}
milvusClient.releaseCollection(
ReleaseCollectionParam.newBuilder()
.withCollectionName("pdf_data")
.build());
return pdfDataList;
}
请求ChatGLM
将得到的杂乱的文本知识,采用OpenAI方式访问ChatGLM,使用ChatGLM的语言组织能力,重新组织语言,返回给我们。
ChatGLM部署及访问参考:ChatGLM本地化部署
JSONObject params = new JSONObject();
params.put("model", "chatglm2-6b");
params.put("max_tokens", maxTokens);
params.put("stream", true);
params.put("temperature", temperature);
params.put("top_p", topP);
params.put("user", user);
JSONObject message = new JSONObject();
message.put("role", "user");
message.put("content", finalPrompt);
params.put("messages", Collections.singleton(message));
log.info("ChatGLM请求参数:"+message.toJSONString());
return webClient.post()
.uri(chatGlmUrl)
.header(HttpHeaders.AUTHORIZATION, "Bearer none")
.bodyValue(params.toJSONString())
.retrieve()
.bodyToFlux(String.class)
.onErrorResume(WebClientResponseException.class, ex -> {
HttpStatus status = ex.getStatusCode();
String res = ex.getResponseBodyAsString();
log.error("ChatGLM error: {} {}", status, res);
return Mono.error(new RuntimeException(res));
});
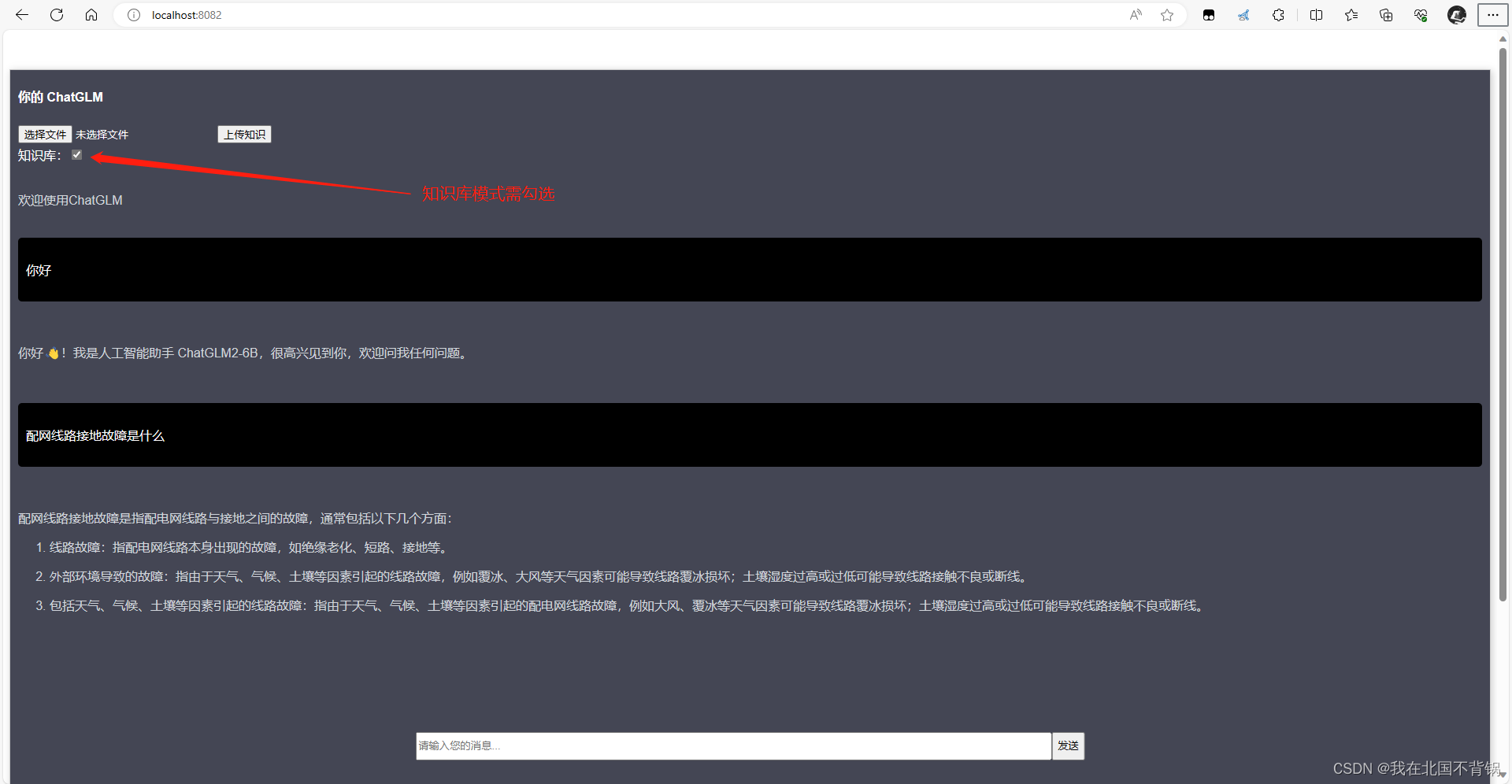
问答测试

![[刷题记录]牛客面试笔刷TOP101](https://img-blog.csdnimg.cn/cb21798a927c4ed2a3b29b1d8b7951ba.png)



![[Vue3 博物馆管理系统] 使用Vue3、Element-plus的Layout 布局构建组图文章](https://img-blog.csdnimg.cn/6c620ff6412a47a3aa7f84afffff885e.png)