论文:https://arxiv.org/abs/2303.14651
代码:https://github.com/hujiecpp/YOSO
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Method
- 3.1. Task Formulation
- 3.2. Feature Pyramid Aggregator
- 3.3. Separable Dynamic Decoder
- 4. Experiments
- 4.1. Datasets and Evaluation Metrics
- 4.2. Implementation Details
- 4.3. Main Results
- 4.4. Ablation Study
- 5. Conclusion
Abstract
在这篇论文中,我们提出了YOSO,一个实时的全景分割框架。YOSO通过全景核与图像特征图之间的动态卷积来预测掩码,您只需要一次分割就可以同时完成实例分割和语义分割任务。为了降低计算开销,我们设计了一个特征金字塔聚合器来提取特征图,以及一个用于全景核生成的可分离动态解码器。
聚合器以卷积为主的方式重新参数化了插值优先模块,这显著加速了管道的速度,而没有额外的成本。解码器通过可分离动态卷积执行多头交叉注意力,以提高效率和准确性。据我们所知,YOSO是第一个实时全景分割框架,与最先进的模型相比,它能够提供竞争性的性能。具体来说,YOSO在COCO上实现了46.4的PQ,45.6的FPS;在Cityscapes上实现了52.5的PQ,22.6的FPS;在ADE20K上实现了38.0的PQ,35.4的FPS;在Mapillary Vistas上实现了34.1的PQ,7.1的FPS。代码可在 https://github.com/hujiecpp/YOSO上找到。
1. Introduction
全景分割是一项任务,涉及将语义标签和实例身份分配给输入图像的每个像素。语义标签通常分为两种类型,即表示无定形和不可计数概念的"stuff"(如天空和道路),以及表示可计数类别的"things"(如人和汽车)。这种标签类型的划分自然将全景分割分为两个子任务:对"stuff"进行语义分割和对"things"进行实例分割。因此,实现实时全景分割的主要挑战之一是需要分别执行语义分割和实例分割的独立且计算密集的分支。通常情况下,实例分割使用框或点来区分不同的"things",而语义分割则为"stuff"预测语义类别的分布图。正如图1所示,已经进行了大量的努力来统一全景分割管道,以提高速度和准确性。
朝着实时全景分割迈进。
(a) 语义分割和实例分割使用共享的FPN进行,但分别在不同的任务分支中执行(例如,在PanopticFPN [28] 和UPSNet [55] 中)。
(b) 语义分割生成所有类别的掩码,实例识别通过使用框或点进行目标检测来实现(例如,在RealTimePan [25] 和PanopticDeepLab [10] 中)。
© 通过重型模块(例如,在PanopticFCN [32]、K-Net [59] 和MaskFormer [11,12] 中),生成"stuff"和"things"的核以对图像特征图进行卷积。
(d) YOSO使用高效的特征金字塔聚合器和轻量级的可分离动态解码器来生成图像特征图和全景核。这些图示中未包括输入图像和骨干网络,以简洁为主。
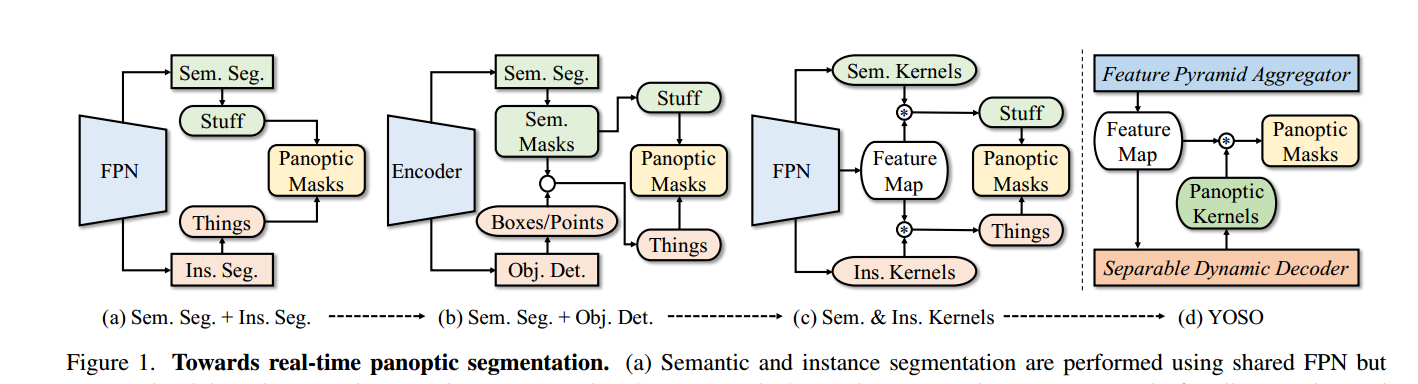
然而,实现实时全景分割仍然是一个未解决的问题。一方面,为了确保准确性,需要使用重型模块,例如[28, 55]中使用的多尺度特征金字塔网络(FPN)和[11, 59]中使用的Transformer解码器,这使得实时处理不可行。另一方面,减小模型尺寸[17, 24, 25]会导致模型泛化能力下降。因此,开发一个既能实现实时处理又能提供竞争性准确性的实时全景分割框架具有挑战性但非常可取。
在本文中,我们介绍了YOSO,一个实时的全景分割框架。YOSO预测全景核以卷积图像特征图,您只需一次分割就可以获得背景"stuff"和前景"things"的掩码。为了使过程轻量级,我们设计了一个用于提取图像特征图的特征金字塔聚合器,以及一个用于生成全景核的可分离动态解码器。在聚合器中,我们提出了卷积优先聚合(CFA)来重新参数化插值优先聚合(IFA),从而在不影响性能的情况下,将GPU延迟减小了约2.6倍。具体来说,我们证明了应用双线性插值和1×1卷积(无偏置)的顺序,即插值优先或卷积优先,不会影响结果,但卷积优先的方式会显著加速管道。在解码器中,我们提出了可分离动态卷积注意力(SDCA)以以权重共享的方式执行多头交叉注意力。SDCA实现了更好的准确性(+1.0 PQ)和更高的效率(GPU延迟约快1.2倍),优于传统的多头交叉注意力。
总的来说,YOSO具有三个显著的优点。首先,CFA减轻了计算负担,无需重新训练模型或牺牲性能。CFA可以适应任何使用双线性插值和1×1卷积操作组合的任务。其次,SDCA执行多头交叉注意力,具有更好的准确性和效率。第三,与最先进的全景分割模型相比,YOSO运行速度更快,准确性竞争力强,并且在四个流行数据集上进行了验证:COCO(46.4 PQ,45.6 FPS)、Cityscapes(52.5 PQ,22.6 FPS)、ADE20K(38.0 PQ,35.4 FPS)和Mapillary Vistas(34.1 PQ,7.1 FPS)。
2. Related Work
实时全景分割。全景分割旨在同时执行语义分割和实例分割,其中输入图像中的每个像素都分配了语义标签和唯一的实例标识。已经进行了许多研究以实现快速的全景分割[9, 10, 17, 19, 24, 25, 32, 38, 42, 43, 46, 55, 56]。例如,UPSNet [55] 利用基于可变形卷积的语义分割头和Mask R-CNN [22] 风格的实例分割头。FPSNet [17] 提出了一种用于全景分割的快速架构,避免了实例掩码预测,并通过软注意力掩码合并输出。最近,PanopticDeepLab [10]、LPSNet [24] 和RealTimePan [25] 首先为所有类别生成语义掩码,然后通过框或点定位实例的掩码,从而实现了高效的目标分割。与此同时,PanopticFCN [32]、K-Net [59] 和MaskFormer [11, 12] 尝试通过动态卷积同时预测"things"和"stuff"的掩码。尽管在这个领域取得了重大进展,但实现实时全景分割仍然是一个未解决的问题。在本文中,YOSO通过使用提出的特征金字塔聚合器和可分离动态解码器,实现了具有竞争力准确性的实时全景分割。
实时实例分割。实例分割旨在预测图像中每个实例的掩码和类别。为了实现实时实例分割,在最近的文献中提出了各种方法。
YOLACT [2, 3] 提出了将预测的掩码系数与原型掩码相乘,而SipMask [5] 利用空间掩码系数进行更精确的分割。CenterMask [31] 使用了高效的无锚点框架,而DeepSnake [41] 探索了使用对象轮廓进行快速实例分割。OrienMask [20] 设计了具有辨别性方向图的方法,可以在不需要额外前景分割的情况下恢复掩码,而SOLO [50, 51] 通过位置对对象进行分割,还使用了解耦分支来加速框架。最近,SparseInst [13] 引入了一组稀疏的实例激活图,用于突出显示图像中每个对象的信息区域,构建了一个实时实例分割框架。由于需要复杂的操作来区分不同的"things",因此高效解决实例分割是实现实时全景分割的关键。在本文中,YOSO预测统一的全景核,用于"things"和"stuff"。通过实施二分图匹配损失[6] 来快速区分不同的"things",YOSO避免了耗时的对象定位操作,例如RoIAlign [22],以及后处理操作,例如非最大值抑制。输出的掩码自然地代表了"things"类别的独立实例。此外,我们在附加材料中的实验结果表明,YOSO在实时实例分割上也可以实现竞争性性能。
实时语义分割。语义分割旨在为输入图像预测像素级别的类别。近年来,已经开发了许多方法来实现实时语义分割。例如,E-Net [40] 提出了一种轻量级架构,用于高速分割,而SegNet [1] 结合了小型网络架构和跳跃连接以实现快速分割。ICNet [60] 使用图像级联算法来加速流程,而ESPNet [36, 37] 引入了高效的空间金字塔空洞卷积。此外,BiSeNet [57, 57] 将空间细节和分类语义分离,以实现语义分割的高精度和高效率。最近,SegFormer [54] 利用轻量级的多层感知器解码器,采用Transformer进行快速语义分割。与传统方法不同,传统方法预测了语义掩码的类别分布图,而YOSO为分割预测了带有相应类别的核。这使得可以有效地共同解决全景分割的语义和实例分割。
3. Method
3.1. Task Formulation
统一全景分割。全景分割将图像中的每个像素映射到一个语义类别和一个实例标识。我们提出了一种统一方法,将前景和背景类别集合视为一个单一实体。为了实现这一点,我们旨在为输入图像预测n个二进制掩码M ∈ B n×h×w 和类别概率L ∈ R n×l,其中(h,w)表示掩码分辨率,l是总类别数。在训练过程中,使用集合预测损失[6, 11]将预测结果与相应的真实标签进行匹配。在测试时,根据前景(即"things")和背景(即"stuff")类别合并分割结果。具体来说,与相同背景类别对应的掩码通过并集操作合并;具有前景类别的掩码被视为独立实例;如果一个像素属于多个类别,则将具有最高概率的类别分配给该像素。
YOSO框架。如图1所示,YOSO是一个紧凑的框架,专为实时全景分割而设计,由一个特征金字塔聚合器和一个可分离动态解码器组成。骨干网络,例如ResNet [23],从输入图像中提取多级特征图。特征金字塔聚合器将多级特征图压缩并聚合成单级特征图。然后,可分离动态解码器使用单级特征图生成全景核,用于掩码预测和分类。
3.2. Feature Pyramid Aggregator
可变形特征金字塔。给定由骨干网络提取的多级特征图C2、C3、C4和C5,我们利用可变形特征金字塔网络[16, 34]来增强不同尺度的特征图。如图2所示,我们首先对多级特征图的通道应用1×1卷积层来压缩通道数。
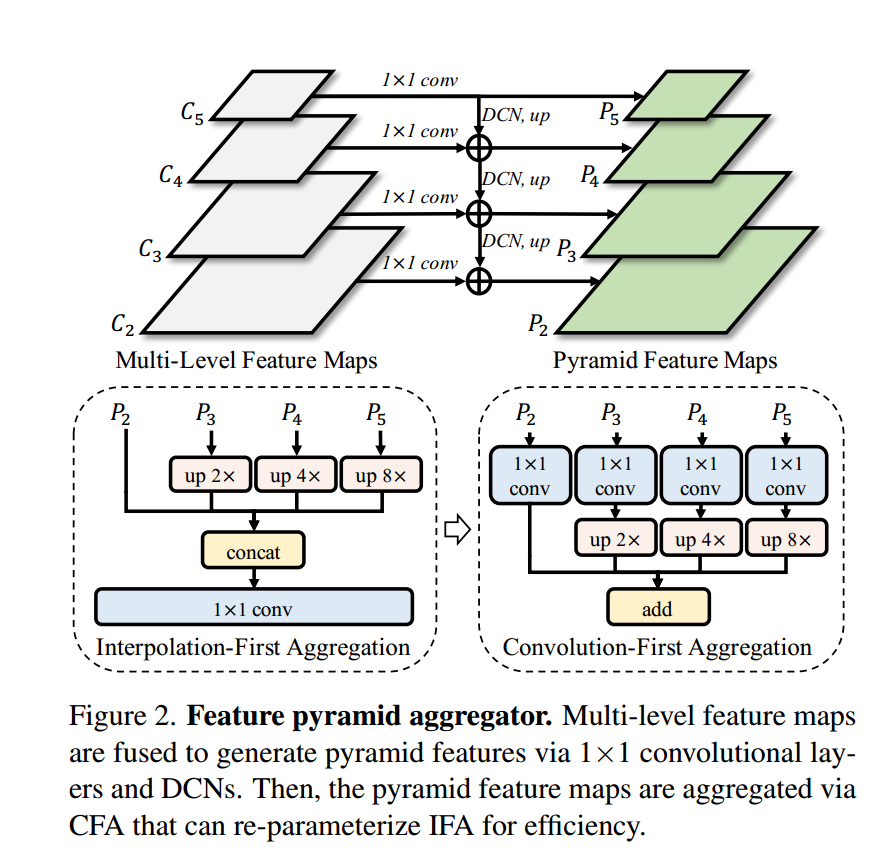
然后,从C3到C5的特征图被送入可变形卷积网络(DCNs)并逐级上采样,得到金字塔特征图P2 ∈ R c2×h×w,P3 ∈ R c3×h/2×w/2,P4 ∈ R c4×h/4×w/4,和P5 ∈ R c5×h/8×w/8,其中c2、c3、c4、c5表示通道维度,h、w表示输入图像的1/4尺度。在获得金字塔特征图后,我们探讨了两种融合方法,即插值优先融合(IFA)和卷积优先融合(CFA),以合并多级特征图。
插值/卷积优先融合。在IFA中,金字塔特征图首先通过双线性插值上采样到h×w的尺度。然后,使用1×1卷积层将特征图连接并融合在一起。在CFA中,金字塔特征图首先被送入不同的1×1卷积层。然后,特征图通过双线性插值上采样到h×w的尺度并相加。
观察1:在使用1×1卷积且不带偏置的情况下,IFA的输出与CFA的输出完全相等。

其中,w_i 可以被解释为一个在特征图中卷积原始位置值的1×1卷积核。
公式1暗示了在双线性插值之前或之后应用1×1卷积(不带偏置)不会影响最终结果。因此,可以推断,在聚合器中使用1×1卷积(不带偏置)时,IFA和CFA会产生相同的输出。
观察2:CFA需要的浮点运算数(FLOPs)明显少于IFA。
IFA和CFA之间的FLOP减少比例为:

在公式2的分子部分(即IFA的FLOP),第一项表示双线性插值中使用的FLOP数量,第二项表示1×1卷积中使用的FLOP数量。在公式2的分母部分(即CFA的FLOP),各项分别表示1×1卷积、双线性插值和累积所需的FLOP数量。
考虑到以上两个观察,我们在提出的特征金字塔聚合器中采用了CFA。值得注意的是,IFA中1×1卷积层的学习权重可以轻松地通过将权重分为四个1×1卷积层来重新参数化为CFA,这可以加速管道而不产生任何额外的成本。
3.3. Separable Dynamic Decoder
为了生成准确的分割核,以前的方法通常依赖于密集的预测器[32]或沉重的Transformer解码器[59]。相比之下,我们提出了一个轻量级的核生成器,称为可分离动态解码器,它可以加速核的生成同时保持高精度。可分离动态解码器如图3所示,由三个模块组成:预注意力模块、可分离动态卷积模块和后注意力模块。具体来说,可分离动态卷积高效地执行多头交叉注意力,并实现更高的准确性。我们在下面详细描述每个模块。
预注意力。受[59]启发,预注意力模块从聚合的特征图中有选择地提取关键信息,以使提议的核多样化。具体而言,聚合的特征图S ∈ R d×h×w经过可学习的提议核Q ∈ R n×d进行卷积,产生注意力图A ∈ R n×h×w。然后,将硬Sigmoid函数σ(·)应用于注意力图,以激活输入值,并使用阈值0.5将值离散为0或1。然后,利用注意力图,可以得到掩码特征V ∈ R n×d,计算如下:

虽然增加模型容量可以提高性能,但也会导致高计算负担。直观地说,多头交叉注意力涉及三个基本操作:多头投影、跨令牌交互和跨维度交互。在公式4中,通过Wo 表示的跨维度交互学习重新加权每个隐藏维度的重要性。在公式5中,通过V Wv i 表示的多头投影将隐藏维度d映射到大小为d/t的t个不同空间中,通过 Ki Vi 表示的跨令牌交互使用相关矩阵在令牌之间进行交互。这些操作启发了我们使用1D卷积执行多头交叉注意力,使过程变得轻量化,定义如下:
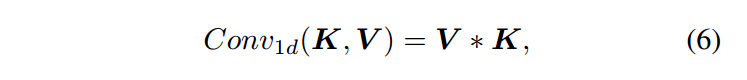

相应地,多头交叉注意力的基本操作也以权重共享的方式在1D卷积中执行。对于多头投影,1D卷积中的滑动窗口将隐藏维度密集地分割成大小为t的d组,每个组中的t个连续隐藏维度通过共享的卷积核进行投影。
对于跨令牌交互,在公式7中的第一个累积项通过n个不同的卷积核与n个令牌进行交互。对于跨维度交互,在公式7中的第二个累积项局部合并了来自t个连续隐藏维度的信息,而不是在多头交叉注意力中全局使用所有隐藏维度。此外,受到[14,27,30,49,52,58]的启发,我们采用了一种动态方法来生成基于Q条件的核K,这将交叉注意力机制引入到1D卷积中,并定义了动态卷积注意力如下:

在公式10的分子部分(即MHCA的FLOP),第一项表示多头投影中使用的FLOP数量,而第二项表示交叉注意力中使用的FLOP数量。在公式10的分母部分(即SDCA的FLOP),各项分别对应于1D卷积操作和线性投影所需的FLOP数量。
后注意力。在后注意力模块中,我们使用多头自注意力层和前馈网络来生成全景核。随后,我们通过2D卷积生成掩码,并使用额外的前馈网络预测相关的类别。受到[4,8]的启发,我们使用全景核来迭代更新提议核,以提高准确性。
4. Experiments
4.1. Datasets and Evaluation Metrics
数据集。我们在四个广泛使用的全景分割数据集上评估了YOSO的有效性和效率:COCO数据集[35]、Cityscapes数据集[15]、ADE20K数据集[61]和Mapillary Vistas数据集[39]。COCO数据集收集了复杂的日常场景图像,包含118k张用于训练和5k张用于验证的图像,包含80个物体类别和53个材质类别。Cityscapes数据集包含城市街景场景的图像,包括2.9k张用于训练和0.5k张用于验证的图像,其中包含8个物体类别和11个材质类别。ADE20K数据集以开放词汇的方式进行注释,包括50个物体类别和100个材质类别,包含20k张用于训练和2k张用于验证的图像。Mapillary Vistas数据集是一个大规模的城市街景数据集,包含18k张用于训练和2k张用于验证的图像,其中包含37个物体类别和28个材质类别。
评估指标。我们使用全景质量(PQ)度量[29]来评估全景分割结果,PQ可以进一步分解为分割质量(SQ)和识别质量(RQ)。材质和物体的评估结果分别由上标s和t表示。YOSO模型的帧率,即每秒帧数(FPS),在单个V100 GPU上进行主要结果的评估,在单个3090 GPU上进行消融研究的评估。
4.2. Implementation Details
对于COCO数据集,我们使用批量大小为16,并将学习率设置为0.0001。模型经过370k次迭代进行了训练,采用了大规模的抖动增强[21]。
对于Cityscapes和Mapillary数据集,我们使用批量大小为16,学习率设置为0.0001,训练计划设置为180k次迭代。对于ADE20K数据集,我们将批量大小设置为16,学习率设置为0.0001,并进行了30k次迭代的训练。对于所有四个数据集,我们使用了在ImageNet [18]数据集上预训练的ResNet50 [23](表示为R50)作为骨干网络,并通过实验将隐藏维度d设置为256。由于COCO数据集包含来自各种场景的图像,从室内到室外不等,我们在该数据集上进行了消融研究。在消融研究中,模型经过270k次迭代的训练。
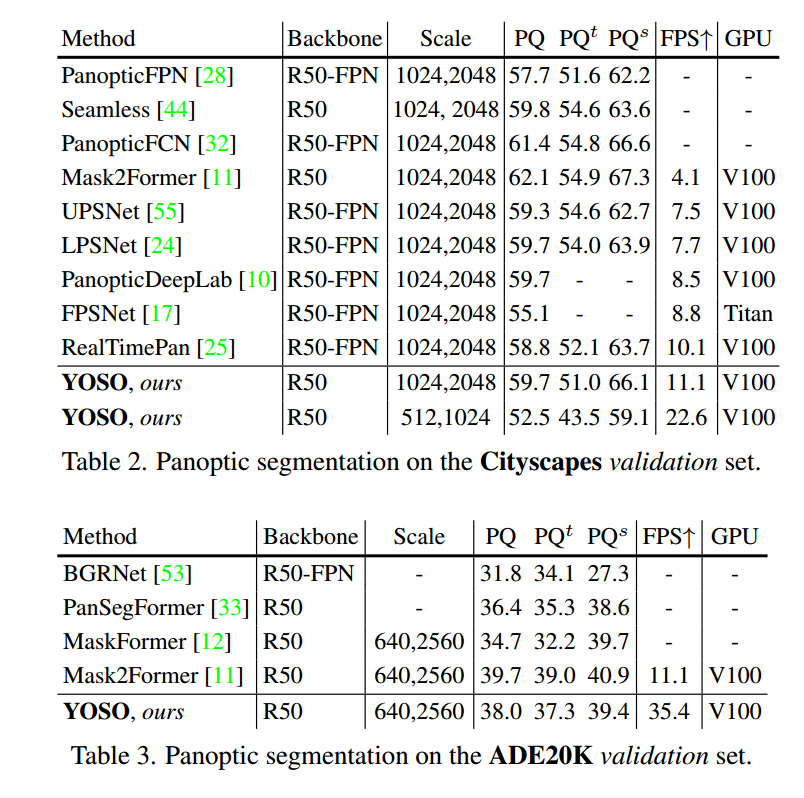

4.3. Main Results
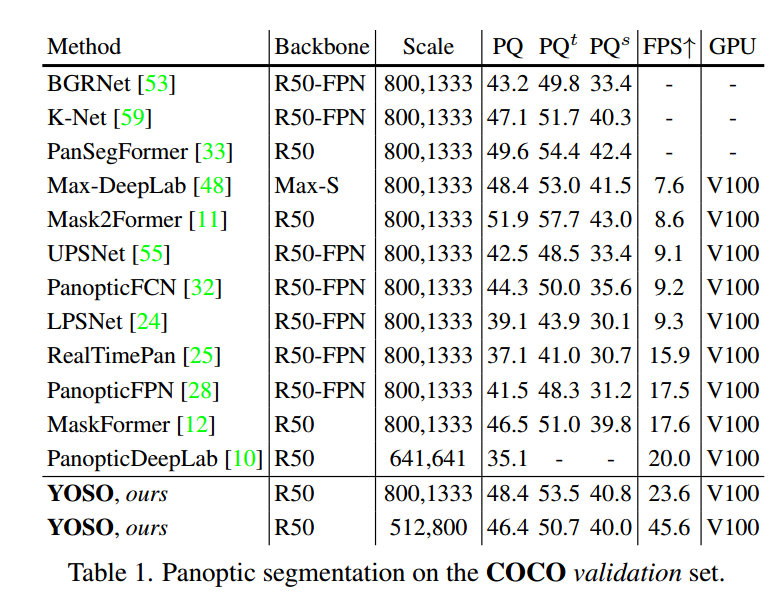
在COCO数据集上的全景分割结果如表1所示。我们有以下发现。首先,YOSO比主流的高效全景分割模型如PanopticFPN [28]和RealTimePan [25]明显更快。具体来说,YOSO在输入图像尺度为(800, 1333)时实现了48.4的PQ和23.6的FPS。这个PQ比RealTimePan高了11.3,速度大约快1.5倍。此外,当将输入图像缩放到(512, 800)时,YOSO比之前最快的模型PanopticDeepLab快约2.3倍,同时实现了约11.0点更高的PQ。其次,YOSO在准确性上与MaskFormer [12]、Mask2Former [11]、Max-DeepLab [48]和K-Net [59]等最先进的模型相媲美。例如,YOSO的PQ比MaskFormer和K-Net分别高出1.9和1.3,与Max-DeepLab相比具有相同的PQ性能。虽然YOSO的PQ比Mask2Former低3.5点,但YOSO比Mask2Former快2.7倍。
在Cityscapes数据集上的全景分割结果如表2所示。YOSO是最快的模型之一,在准确性方面具有竞争力。例如,YOSO在输入图像尺寸为(1024, 2048)时实现了59.7的PQ和11.1的FPS,比FPSNet高出4.7点。此外,当将输入图像尺度降低到(512, 1024)时,YOSO实现了52.5的PQ,帧率为22.6。
在表3和表4中,我们展示了在ADE20K和Mapillary Vistas数据集上的全景分割结果,以评估YOSO的模型泛化能力。
在ADE20K数据集上,YOSO在速度和准确性方面均优于大多数先前的方法,如PanSegFormer [33]和MaskFormer [12]。在Mapillary Vistas数据集上,尽管YOSO在PQs方面表现良好,但PQt的性能落后于最先进的模型。
这表明YOSO在Mapillary Vistas数据集上仍有改进的潜力。
此外,我们在图4中绘制了COCO和Cityscapes数据集上PQ与FPS的结果,显示YOSO在速度和准确性方面均表现出色,与最先进的模型具有竞争力。总之,四个数据集上的主要结果验证了YOSO的良好泛化性能和速度-准确性平衡。
4.4. Ablation Study
为了研究YOSO不同组件对速度和准确性的影响,我们进行了几项关于特征金字塔聚合器和可分离动态解码器的消融研究。具体来说,我们评估了聚合模块和注意力模块的有效性,得出了一些有趣的发现。此外,我们分析了注意力块的数量、核大小、迭代阶段和提议核的变化如何影响性能。我们将详细讨论我们的研究结果。
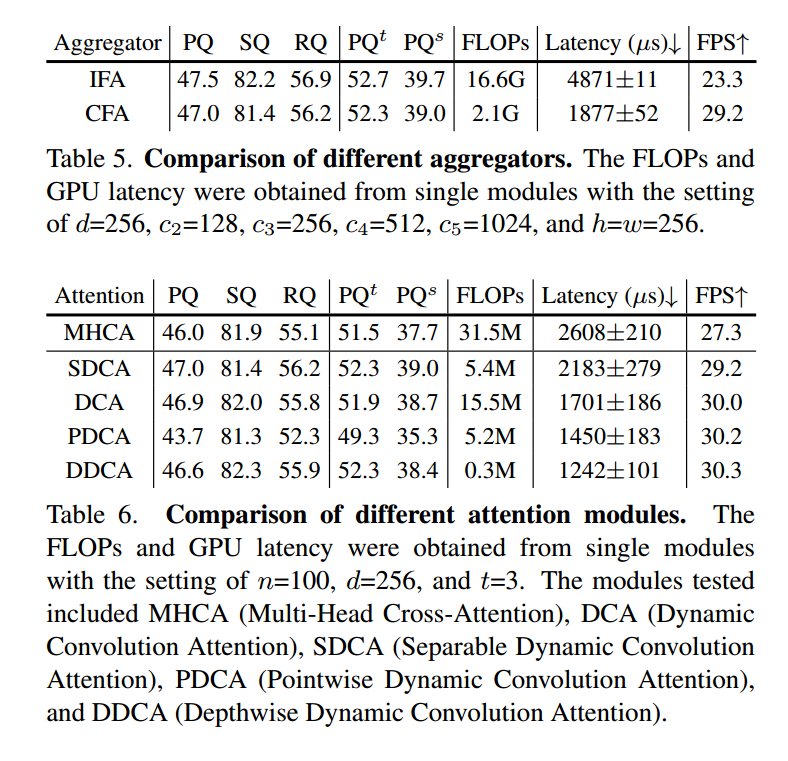
不同聚合器的比较。不同聚合器的结果如表5所示。具体来说,我们分别使用IFA和CFA训练了YOSO。
PQ的结果表明,IFA的准确性高于CFA,分别为47.5和47.0。然而,IFA的FLOPs比CFA要大得多,分别为16.6G和2.1G,并且GPU延迟更高,分别为4871µs和1877µs。考虑到IFA的学习参数可以直接重新参数化为CFA,我们可以使用IFA训练YOSO,并使用重新参数化的CFA进行推断,以获得更好的速度和准确性。
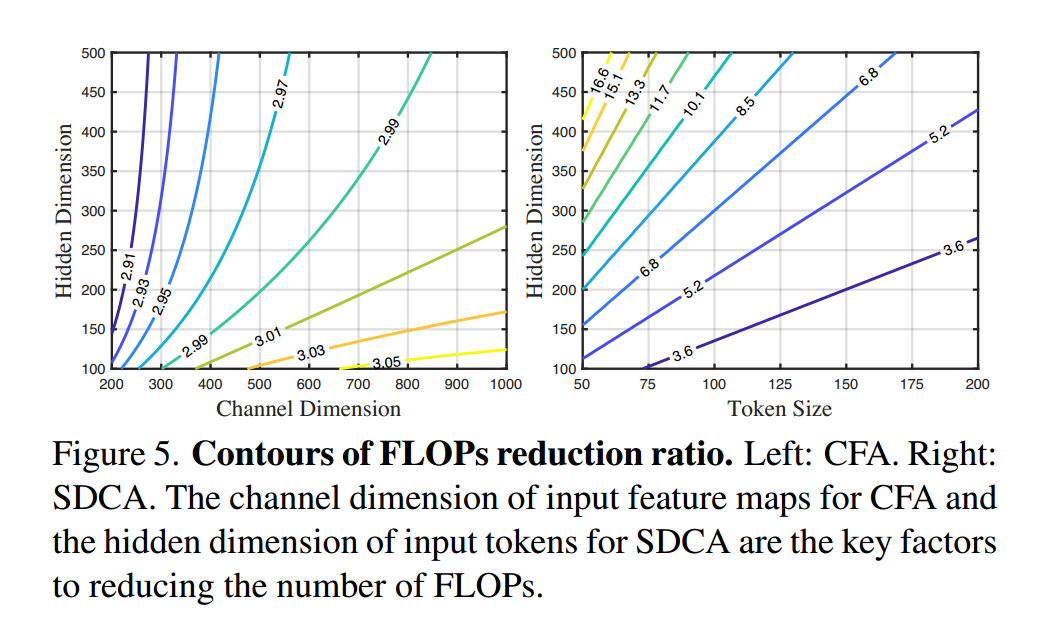
在图5(左)中,我们研究了CFA和IFA之间的FLOPs减小比率。具体来说,我们将输入特征图的通道维度c5、c4、c3和c2设置为c,并分析输入通道维度c和输出隐藏维度d对Eq. 2中的FLOPs减小比率的影响。我们的结果表明,增加输入通道维度和减小输出隐藏维度会导致减小比率增加。这意味着当输入通道的维度很大时,CFA将更加高效。
不同注意力模块的比较。我们在表6中比较了不同注意力模块的有效性。就PQ性能而言,我们发现了两个有趣的发现。首先,令人惊讶的是,MHCA模块的性能并不比DCA和SDCA更好。这可能是因为这两种类型的注意力模块中的基本操作之间的差异:DCA将隐藏维度密集地分成了d个组,而MHCA将其稀疏地分成了t个组。其次,PDCA的性能较差,PQ为43.7,可能是因为PDCA是唯一不应用跨维度交互的模块,这意味着隐藏维度之间的交互对于注意力模块非常重要。这一观察结果得到了DDCA的性能支持,它只执行跨令牌交互,并获得了46.7的PQ。这两个结果表明,跨维度交互在全景核生成中可能比跨令牌交互更重要,因为全景核应该是独立的,以表示不同的物体或物体。
就FLOPs而言,我们观察到基于动态卷积的注意力模块需要更少的FLOPs。
具体来说,DDCA的计算成本最低,仅需要0.3M FLOPs。就GPU延迟而言,我们观察到两个有趣的现象。首先,尽管MHCA、DCA、SDCA和PDCA的时间复杂度都是O(n 2d),但在GPU延迟上的加速效果明显。
其次,我们发现SDCA的运行速度比DCA慢,与FLOPs分析的结果相反。我们推测,SDCA中附加的卷积层和全连接层是串行执行而不是并行执行的,这可能导致实际执行时间更长。
图5(右)展示了根据Eq. 10
给出的FLOPs减小比率的分析。我们将核大小t固定为3,并研究了令牌大小n和隐藏维度d对减小比率的影响。结果表明,随着令牌大小减小和隐藏维度增加,减小比率增加。具体来说,当令牌大小小于隐藏维度时,DCA在令牌大小较小的情况下表现更好,这表明它适用于令牌大小小于隐藏维度的视觉任务。
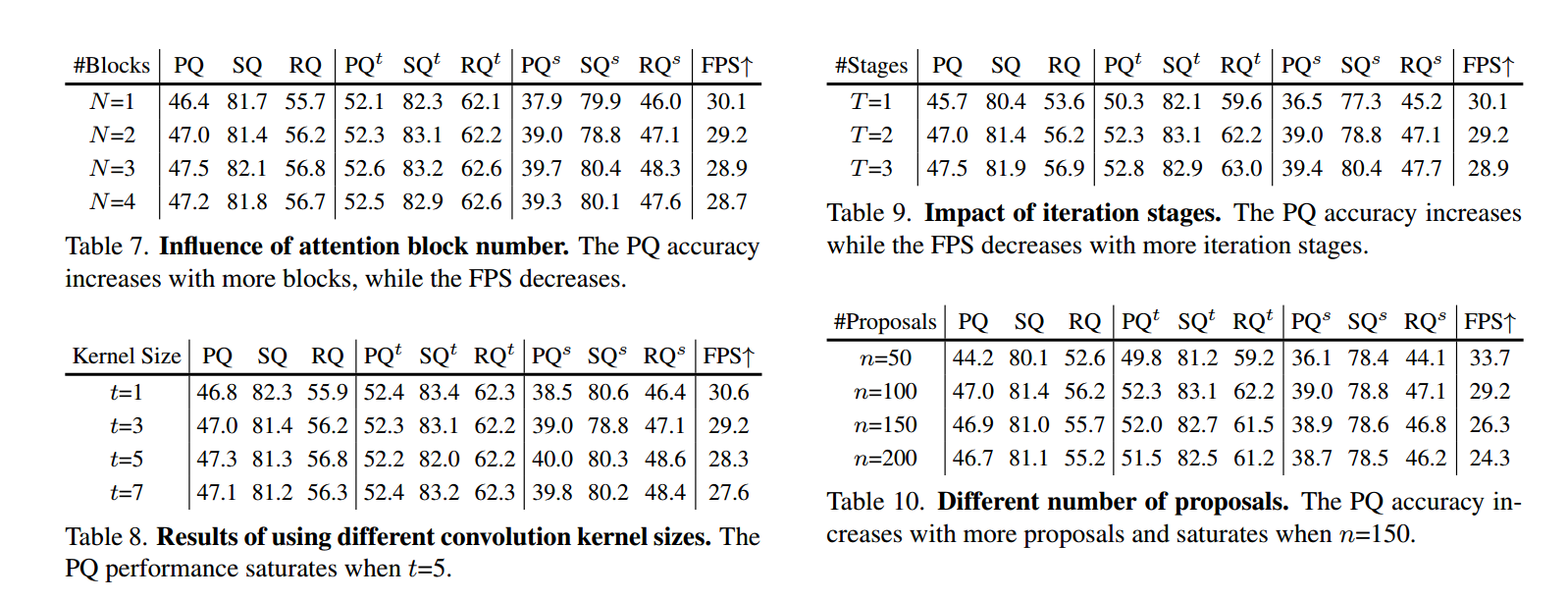
注意块的数量。为了评估可分离动态卷积在可分离动态解码器中的有效性,我们改变了块的数量,并分析了速度和准确性之间的权衡,如表7所示。结果显示,随着额外块的增加,PQ准确性得到提高,但以牺牲FPS为代价。因此,我们选择N = 2作为YOSO速度和准确性之间的妥协。
动态卷积的核大小。表8展示了可分离动态卷积注意模块不同核大小的有效性。PQ性能确认了我们在表6中的观察结果,表明跨维度交互在注意力模块中起到了重要作用。具体来说,将核大小从5减小到1会导致PQ性能从47.3下降到46.8。此外,当核大小从5增加到7时,性能达到饱和。
迭代阶段。为了评估阶段数量的影响,我们进行了具有不同阶段数的实验,并在表9中报告了结果。我们的结果表明,增加阶段数可以提高PQ性能,但以降低FPS性能为代价。我们观察到,在使用T = 2个阶段时,在速度和准确性之间的权衡最佳。
因此,我们选择了这种配置用于YOSO。
提案核的数量。我们研究了提案核数量的影响,如表10所示。结果表明,将提案核的数量从50增加到100会提高PQ性能,并在150时达到饱和。与此同时,随着提案核数量的增加,速度下降。设置n=100在YOSO的准确性和速度之间取得了良好的平衡。
5. Conclusion
在本文中,我们提出了一个实时的全景分割框架,称为YOSO。使用YOSO,您只需要一次分割前景物体和背景材料的蒙版。YOSO包括一个特征金字塔聚合器和一个可分离动态解码器,以加速管道。特征金字塔聚合器中的CFA模块重新参数化了IFA模块,减少了FLOP,而不需要额外的成本。可分离动态解码器中的SDC模块执行共享权重的多头交叉注意力,增强了速度和准确性。我们的广泛实验证明,YOSO在保持竞争性PQ性能的同时,明显快于其他重要的全景分割方法。鉴于其有效性和简单性,我们希望YOSO可以作为强大的基准,为未来实时全景分割研究带来新的见解。

![[刷题记录]牛客面试笔刷TOP101](https://img-blog.csdnimg.cn/cb21798a927c4ed2a3b29b1d8b7951ba.png)



![[Vue3 博物馆管理系统] 使用Vue3、Element-plus的Layout 布局构建组图文章](https://img-blog.csdnimg.cn/6c620ff6412a47a3aa7f84afffff885e.png)