检索增强是一种常用且有效的方法,用于增强语言模型的事实知识,同时加快模型推理时间。尽管如此,这种方法带来了相当大的计算成本,这归因于存储预先计算的表示所需的大量存储需求。
为了解决这一相关问题,谷歌研究小组在他们的新论文中提出了一个突破性的解决方案,题为“MEMORY-VQ:压缩可处理的互联网规模内存”。这种创新方法 MEMORY-VQ 显著减少了与基于内存的技术相关的存储先决条件,同时保持了高性能水平,在 KILT 基准测试中实现了令人印象深刻的 16 倍压缩率。

值得注意的是,这一努力标志着压缩预编码令牌内存表示领域的开创性努力,因为之前没有研究探索过这一途径。MEMORY-VQ方法将产品量化与VQ-VAE方法无缝融合,以实现其主要目标:在不影响质量的情况下降低基于内存的方法的存储需求。
核心概念涉及采用矢量量化技术,用整数代码替换原始内存矢量以进行内存压缩。然后,这些代码可以根据需要有效地转换回向量。通过在LUMEN中实现这种方法,这是一种有效的基于内存的技术,可以预先计算检索到的段落的令牌表示以显着加快推理速度,研究人员开发了LUMEN-VQ模型。
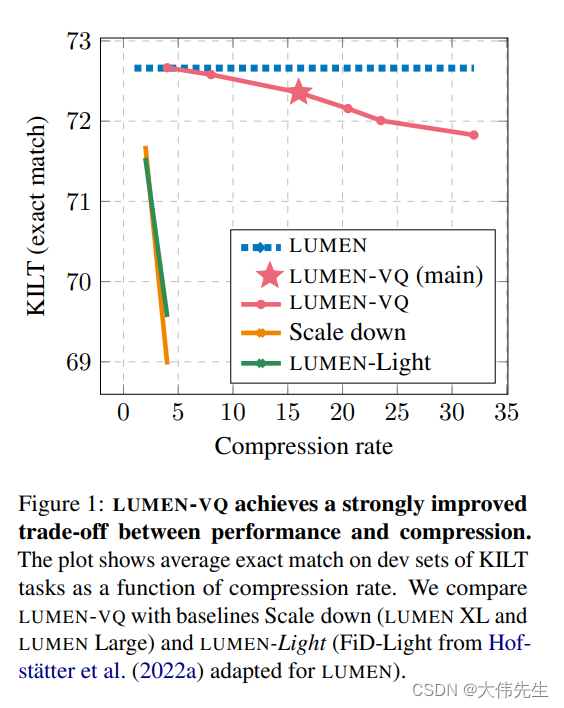
在他们的实证调查中,研究小组进行了比较分析,使用KILT基准中的知识密集型任务子集,将LUMEN-VQ与流明大和流明光等朴素基线进行了对比。令人印象深刻的是,LUMEN-VQ设法实现了惊人的16倍压缩率,而质量损失有限。
总之,这项研究强调了MEMORY-VQ作为一种记忆增强技术和实用解决方案的有效性,可以在处理广泛的检索语料库时大幅提高推理速度。
论文 MEMORY-VQ: Compression for Tractable Internet-Scale Memory on arXiv.