大家好,我是Leo! 今天给大家带来的是关于PageHelper原理的解析,最近遇到一个SQL优化的问题,顺便研究了一下PageHelper的原理,毕竟也是比较常用,源码也比较好看的懂,如果感兴趣的小伙伴可以跟着过程去DEBUG源码,相信会有一定收获,源码也采用了策略、工厂等设计模式
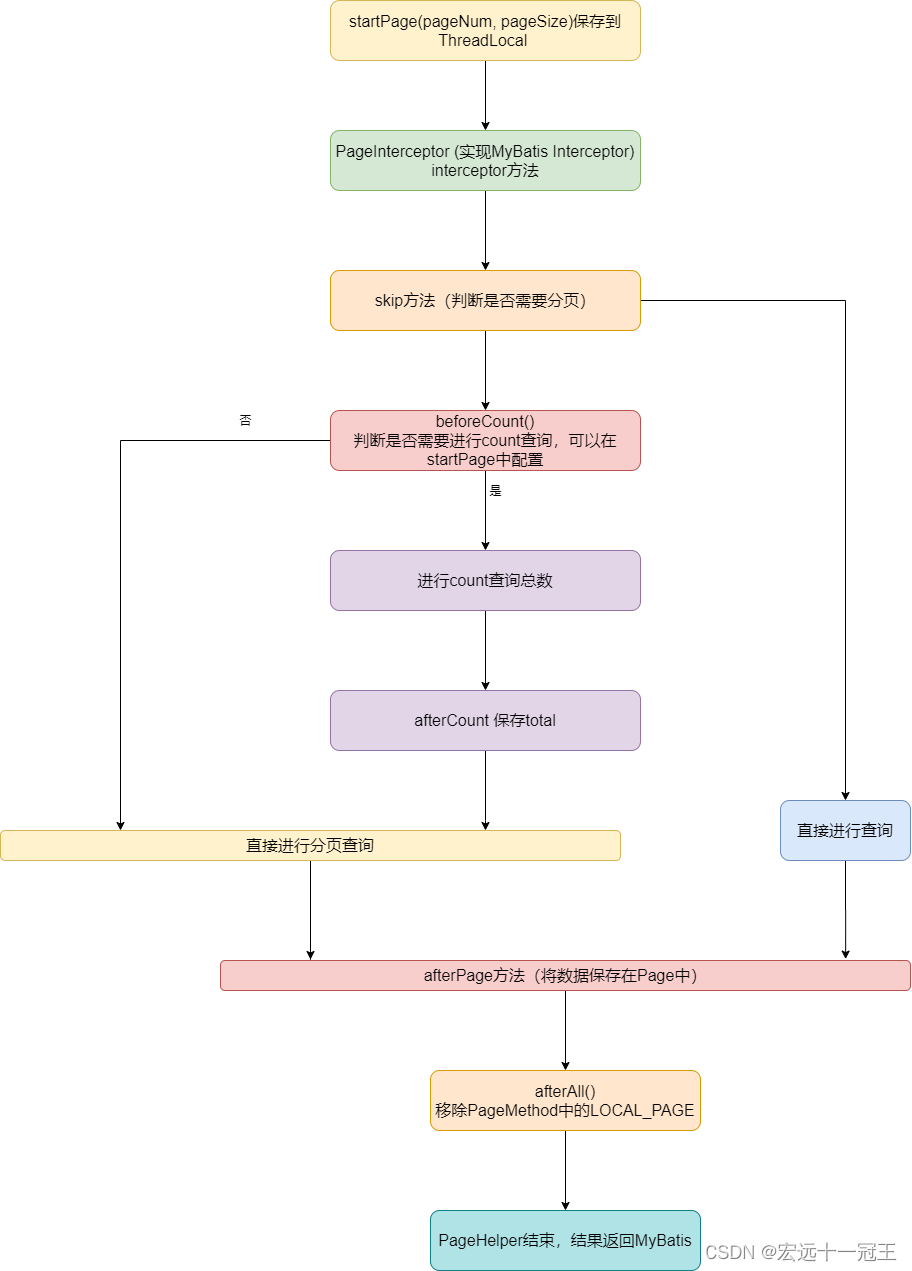
总体流程
在调用startPage时,将分页对象Page参数保存下来,留意setLocalPage方法,该方法是保存分页参数的关键,采用ThreadLocal来保存分页参数。
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
setLocalPage(page);
return page;
}
// 保存分页参数
// protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();那么PageHelper是如何判断是否需要分页的呢,这里就需要涉及到MyBatis的Interceptor接口,PageHelper中有一个PageInterceptor实现了该接口,并在intercept方法中写了分页的核心逻辑,boundSql可以看到需要执行的sql,再往下看进入skip方法可以看到是否需要进行分页,主要是判断系统是否有使用多个分页插件。
继续往下可以看到beforeCounnt方法,会判断是否需要进行count查询,跟进该方法,你会发现在AbstractHelperDialect类中有getLocalPage方法,获取的是我们开始调用startPage方法中保存的page对象(ThreadLocal)。
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
// boundSql就是我们需要执行
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
dialect.afterAll();
}
}然后接着跟进count方法,然后你可以看到countMsId就是这条SQL的的路径再拼上_COUNT,
然后ExecutorUtil.getExistMapperdStatment方法中是通过MyBatis的Configuration来获取是否存在这样的一个查询,如果我们有重写COUNT方法,它就会执行我们写的count语句,如果没有写,它会帮我们拼装一条count语句。
private Long count(Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
String countMsId = ms.getId() + countSuffix;
Long count;
//先判断是否存在手写的 count 查询
MappedStatement countMs = ExecutorUtil.getExistedMappedStatement(ms.getConfiguration(), countMsId);
if (countMs != null) {
count = ExecutorUtil.executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
countMs = msCountMap.get(countMsId);
//自动创建
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
msCountMap.put(countMsId, countMs);
}
count = ExecutorUtil.executeAutoCount(dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);
}
return count;
}接着进入afterCount语句,执行完后需要保存total总数,后续分页需要使用。
@Override
public boolean afterCount(long count, Object parameterObject, RowBounds rowBounds) {
Page page = getLocalPage();
page.setTotal(count);
if (rowBounds instanceof PageRowBounds) {
((PageRowBounds) rowBounds).setTotal(count);
}
//pageSize < 0 的时候,不执行分页查询
//pageSize = 0 的时候,还需要执行后续查询,但是不会分页
if (page.getPageSize() < 0) {
return false;
}
return count > 0;
}然后回到PageInterceptor中ExecutorUtil.pageQuery中执行分页查询,在dialect.getPageSql,然后跟进到AbstaractHelpDialect.getPageSql,这里也会拿出Page对象,然后再调用对应数据库的分页查询的拼接SQL,这里我的是MySQL,最终调用到MySqlDialect中的getPageSql方法,然后我们就可以看到LIMIT 关键字是如何拼接上去的了,然后再填充动态sql的参数
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql, CacheKey cacheKey) throws SQLException {
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
}@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
return sqlBuilder.toString();
}然后通过调用executer.query来查询sql.
总体流程图
总结
以上就是PageHelper源码和其执行流程,其实看了源码发现,它是帮我们去管理了分页逻辑,核心是通过MyBatis的拦截器来进行分页的。