AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- 1、问题
- 2、模型结构
1、问题
在视觉方面,注意力要么与卷积网络结合使用,要么用于替代卷积网络的某些组件,同时保持其整体结构不变。
我们证明了这种对CNNs的依赖是不必要的,一个纯Transformer直接应用于图像序列的补丁可以很好地完成图像分类任务。
2、模型结构
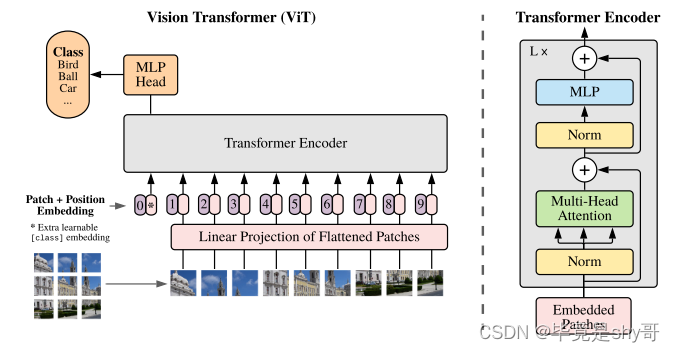
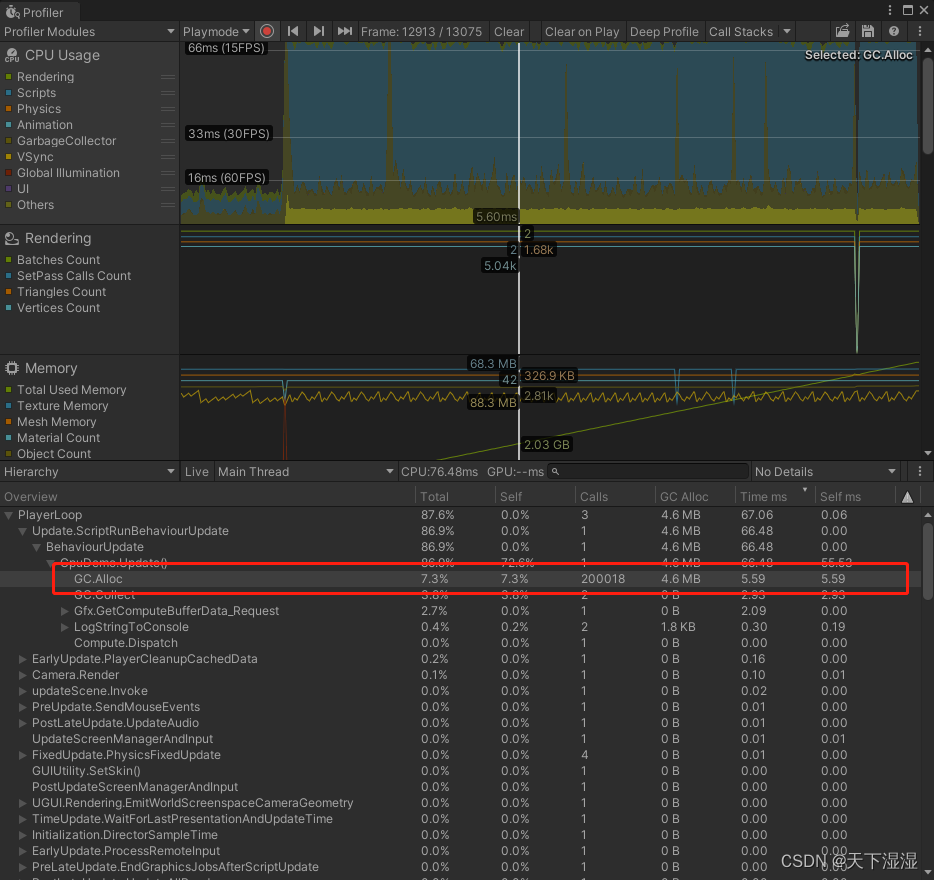
上图描述了模型的概述。NLP的Transformer接收到作为输入的一维token嵌入序列。
对于二维图像的处理,我们将图像(H×W×C)重塑为平面二维patch (P^2xC)的序列,其中(H,W)为原始图像的分辨率,C为通道数,(P, P)为每个图像patch的分辨率,N = H*W/ P的平方为最终得到的patch数,同时作为Transformer的有效输入序列长度。我们将得到的此投影的输出称为patch嵌入。
处理图像数据流程:
第一层将展平的patches映射到一个低维空间,接着在patch中加入一个可学习的位置嵌入,该模型学会了根据位置嵌入的相似性对图像中的距离进行编码,也就是说,距离较近的斑块往往有更多相似的位置嵌入,接着进入transformer模块,自注意力允许ViT整合整个图像的信息,即使是在最低层,最后送入mlp层进行分类输出
- 补丁序列还加入了位置编码和可学习的类别编码嵌入。
- 在ViT中,只有MLP层是局部的、平移上相等的,而自我关注层是全局。
- 通常,我们在大型数据集上对ViT进行预训练,并对(较小的)下游任务进行微调。为此,我们去除预训练的预测头,附加一个零初始化的D × K前馈层,其中K为下游类的数量。微调往往比预训练的分辨率更高,这是有益的。
- 视觉Transformer可以处理任意的序列长度(直到内存限制)