废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【】,使用【】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为:目标公司+最近一年+出现频率排序,由高到低的去牛客TOP101去找,只有两个地方都出现过才做这道题(CodeTop本身汇聚了LeetCode的来源),确保刷的题都是高频要面试考的题。
名曲目标题后,附上题目链接,后期可以依据解题思路反复快速练习,题目按照题干的基本数据结构分类,且每个分类的第一篇必定是对基础数据结构的介绍。
最长公共子串【MID】
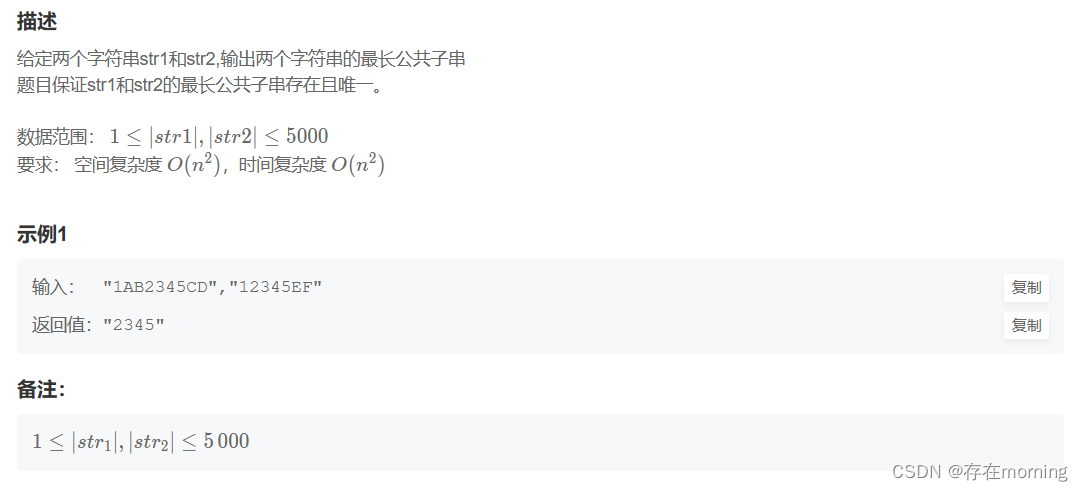
首先来一道最长公共子串,难度还没有升级,公共字符是连续的即可
题干
解题思路
求两个数组或者字符串的最长公共子序列问题,肯定是要用动态规划的。
- 首先,区分两个概念:子序列可以是不连续的;子数组(子字符串)需要是连续的;
- 另外,单个数组或者字符串要用动态规划时,可以把动态规划
dp[i]定义为nums[0:i]中想要求的结果;当两个数组或者字符串要用动态规划时,可以把动态规划定义成两维的dp[i][j],其含义是在A[0:i]与B[0:j]之间匹配得到的想要的结果。
1. 状态定义
对于本题而言,可以定义 dp[i][j] 表示 text1[0:i-1] 和 text2[0:j-1] 的最长公共子序列。 (注:text1[0:i-1] 表示的是 text1 的 第 0 个元素到第 i - 1 个元素,两端都包含) 之所以 dp[i][j] 的定义不是 text1[0:i] 和 text[0:j] ,是为了方便当 i = 0 或者 j = 0 的时候,dp[i][j]表示空字符串和另外一个字符串的匹配,这样 dp[i][j] 可以初始化为空字符串
2. 状态转移方程
知道状态定义之后,开始写状态转移方程。
- 当
text1[i - 1] == text2[j - 1]时,说明两个子字符串的最后一位相等,所以最长公共子串长度又增加了 1,所以dp[i][j] = dp[i - 1][j - 1] + text1[i]; - 当
text1[i - 1] != text2[j - 1]时,说明两个子字符串的最后一位不相等,所以不够成公共子串,不满足条件
综上状态转移方程为:
dp[i][j] = dp[i - 1][j - 1] + s1.charAt(i - 1), 当text1[i−1]==text2[j−1]
当然我们还需要当前最新下标来辅助记录子串最新的更新位置
3. 状态的初始化
初始化就是要看当 i = 0 与 j = 0 时, dp[i][j] 应该取值为多少。
- 当 i = 0 时,
dp[0][j]表示的是 text1中取空字符串 跟 text2的最长公共子序列,结果肯定为 空字符串. - 当 j = 0 时,
dp[i][0]表示的是 text2中取空字符串 跟 text1的最长公共子序列,结果肯定为 空字符串.
综上,当 i = 0 或者 j = 0 时,dp[i][j] 初始化为 空字符串.
4. 遍历方向与范围
由于 dp[i][j] 依赖于 dp[i - 1][j - 1] ,,所以 i和 j的遍历顺序肯定是从小到大(自底向上)的。 另外,由于当 i和 j 取值为 0 的时候,dp[i][j] = 0,而 dp 数组本身初始化就是为 空字符串,所以,直接让 i 和 j 从 1 开始遍历。遍历的结束应该是字符串的长度为 len(text1)和 len(text2)。
5. 最终返回结果
由于 dp[i][j] 的含义是 text1[0:i-1] 和 text2[0:j-1] 的最长公共子序列。我们最终希望求的是 text1 和 text2 的最长公共子序列。所以需要返回的结果是 i = len(text1) 并且 j = len(text2) 时的 dp[len(text1)][len(text2)]。
代码实现
给出代码实现基本档案
基本数据结构:字符串
辅助数据结构:无
算法:动态规划
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* longest common substring
* @param str1 string字符串 the string
* @param str2 string字符串 the string
* @return string字符串
*/
public String LCS (String str1, String str2) {
// 入参条件判断
if (str1 == null || str1.length() == 0 || str2 == null || str2.length() == 1) {
return null;
}
// 1 初始化状态
int ls1 = str1.length();
int ls2 = str2.length();
// dp表示范围为0-ls1的str1与0-ls2的str2的最长公共子串长度
int[][] dp = new int[ls1 + 1][ls2 + 1];
int max = 0;
int latestIndex = 0;
// 2 遍历(自底向上)
for (int i = 1; i <= ls1; i++) {
for (int j = 1; j <= ls2; j++) {
// 状态转移方程
if (str1.charAt(i - 1) == str2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
// 更新子串最大长度以及当前子串下标
if (dp[i][j] > max) {
max = dp[i][j];
// 公共子串不包含latestIndex位置
latestIndex = i;
}
}
}
}
// 上述循环i从1开始,这里subString右侧为开区间,刚好适用
return str1.substring(latestIndex - max, latestIndex);
}
}
复杂度分析
时间复杂度:O(n^2 ),构造辅助数组dp与b,两层循环,递归是有方向的递归,因此只是相当于遍历了二维数组
空间复杂度:O(n^2 ),辅助二维数组dp与递归栈的空间最大为O(n^2 )
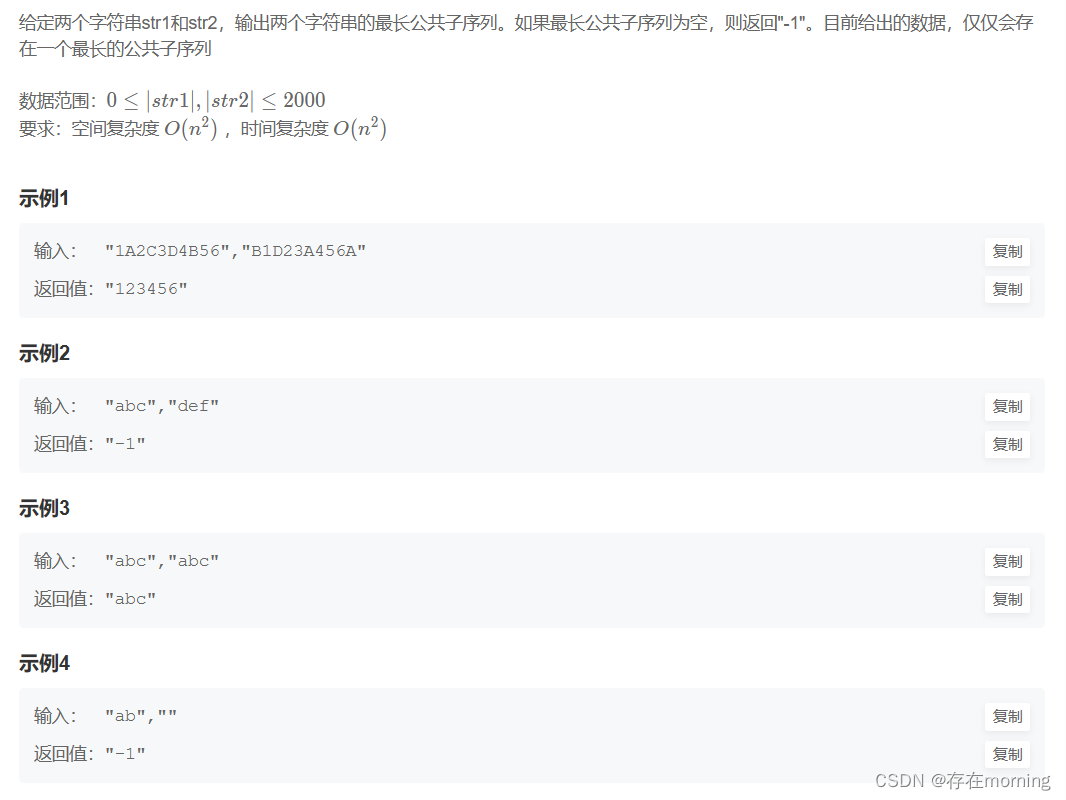
最长公共子序列【MID】
难度升级,明确下什么是公共子序列。一个字符串的子序列是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,ace是 abcde的子序列,但 aec不是 abcde 的子序列
题干
解题思路
求两个数组或者字符串的最长公共子序列问题,肯定是要用动态规划的。
- 首先,区分两个概念:子序列可以是不连续的;子数组(子字符串)需要是连续的;
- 另外,单个数组或者字符串要用动态规划时,可以把动态规划
dp[i]定义为nums[0:i]中想要求的结果;当两个数组或者字符串要用动态规划时,可以把动态规划定义成两维的dp[i][j],其含义是在A[0:i]与B[0:j]之间匹配得到的想要的结果。
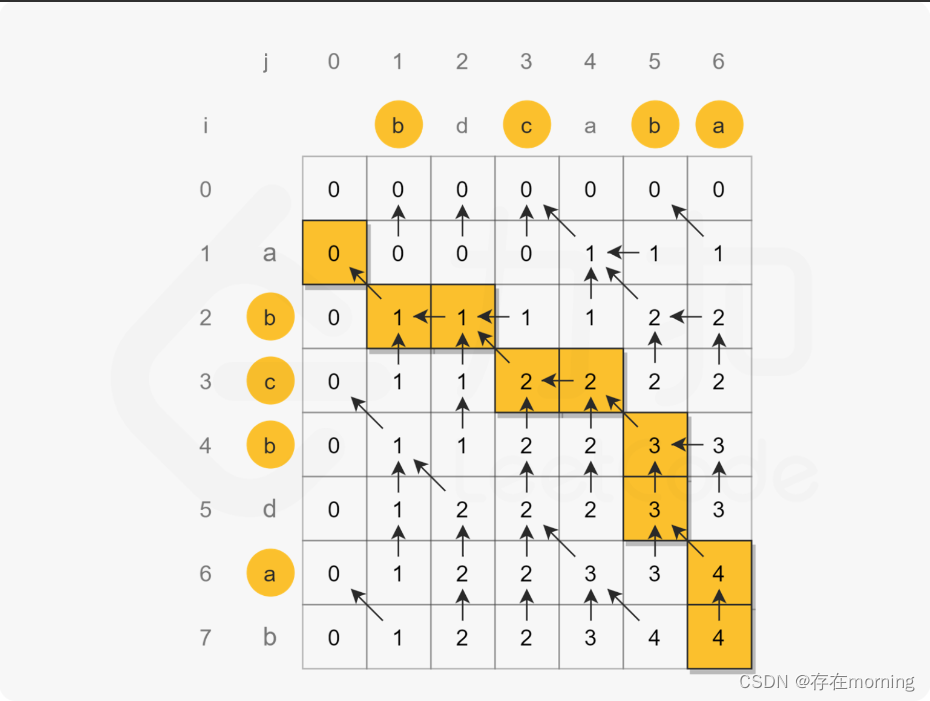
1. 状态定义
对于本题而言,可以定义 dp[i][j] 表示 text1[0:i-1] 和 text2[0:j-1] 的最长公共子序列。 (注:text1[0:i-1] 表示的是 text1 的 第 0 个元素到第 i - 1 个元素,两端都包含) 之所以 dp[i][j] 的定义不是 text1[0:i] 和 text[0:j] ,是为了方便当 i = 0 或者 j = 0 的时候,dp[i][j]表示空字符串和另外一个字符串的匹配,这样 dp[i][j] 可以初始化为空字符串
2. 状态转移方程
知道状态定义之后,开始写状态转移方程。
- 当
text1[i - 1] == text2[j - 1]时,说明两个子字符串的最后一位相等,所以最长公共子序列又增加了 1,所以dp[i][j] = dp[i - 1][j - 1] + text1[i];举个例子,比如对于 ac 和 bc 而言,他们的最长公共子序列的长度等于 a 和 b 的最长公共子序列长度 0 + text[1] = c。 - 当
text1[i - 1] != text2[j - 1]时,说明两个子字符串的最后一位不相等,那么此时的状态dp[i][j]应该是dp[i - 1][j]和dp[i][j - 1]的最大值。举个例子,比如对于 ace 和 bc 而言,他们的最长公共子序列等于 ① ace 和 b 的最长公共子序列:空字符串的长度0 与 ② ac 和 bc 的最长公共子序列c长度1 的最大值,即 1,所以选择长度大的
综上状态转移方程为:
dp[i][j] = dp[i - 1][j - 1] + s1.charAt(i - 1), 当text1[i−1]==text2[j−1]dp[i][j] = dp[i - 1][j].length() > dp[i][j - 1].length() ? dp[i - 1][j] : dp[i][j - 1];, 当text1[i−1]!=text2[j−1]
3. 状态的初始化
初始化就是要看当 i = 0 与 j = 0 时, dp[i][j] 应该取值为多少。
- 当 i = 0 时,
dp[0][j]表示的是 text1中取空字符串 跟 text2的最长公共子序列,结果肯定为 空字符串. - 当 j = 0 时,
dp[i][0]表示的是 text2中取空字符串 跟 text1的最长公共子序列,结果肯定为 空字符串.
综上,当 i = 0 或者 j = 0 时,dp[i][j] 初始化为 空字符串.
4. 遍历方向与范围
由于 dp[i][j] 依赖于 dp[i - 1][j - 1] ,,所以 i和 j的遍历顺序肯定是从小到大(自底向上)的。 另外,由于当 i和 j 取值为 0 的时候,dp[i][j] = 0,而 dp 数组本身初始化就是为 空字符串,所以,直接让 i 和 j 从 1 开始遍历。遍历的结束应该是字符串的长度为 len(text1)和 len(text2)。
5. 最终返回结果
由于 dp[i][j] 的含义是 text1[0:i-1] 和 text2[0:j-1] 的最长公共子序列。我们最终希望求的是 text1 和 text2 的最长公共子序列。所以需要返回的结果是 i = len(text1) 并且 j = len(text2) 时的 dp[len(text1)][len(text2)]。
代码实现
给出代码实现基本档案
基本数据结构:字符串
辅助数据结构:无
算法:动态规划
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* longest common subsequence
* @param s1 string字符串 the string
* @param s2 string字符串 the string
* @return string字符串
*/
public String LCS (String s1, String s2) {
// 0 入参校验
if (s1 == null || s1.length() == 0 || s2 == null ||
s2.length() == 0) return "-1";
// 1 状态定义及初始化
int ls1 = s1.length();
int ls2 = s2.length();
// 长度为ls1和长度为ls2的最长公共子序列是dp
String[][] dp = new String[ls1 + 1][ls2 + 1];
// 2 初始化状态值,当初始化状态时,公共子序列为空字符串
for (int i = 0; i <= ls1; i++) {
// j为0表示一个长度不为0的s1和一个长度永远为0的字符串公共子序列一定是空字符串
dp[i][0] = "";
}
for (int j = 0; j <= ls2; j++) {
// i为0表示一个长度不为0的s1和一个长度永远为0的字符串公共子序列一定是空字符串
dp[0][j] = "";
}
// 3 自底向上遍历
for (int i = 1; i <= ls1; i++) {
for (int j = 1; j <= ls2; j++) {
// 4 状态转移方程
if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
// 如果s1和s2的字符相等,dp[1][1]表示dp[0][0]+a=a(自底向上)
dp[i][j] = dp[i - 1][j - 1] + s1.charAt(i - 1);
} else {
// 如果s1和s2的字符不相等,取dp[i - 1][j]和dp[i][j - 1]较长的字符作为dp[i][j]
dp[i][j] = dp[i - 1][j].length() > dp[i][j - 1].length() ? dp[i - 1][j] :
dp[i][j - 1];
}
}
}
// 5 返回的是两个完整s1和s2的公共子序列
return dp[ls1][ls2] == "" ? "-1" : dp[ls1][ls2];
}
}
复杂度分析
时间复杂度:O(n^2 ),构造辅助数组dp与b,两层循环,递归是有方向的递归,因此只是相当于遍历了二维数组
空间复杂度:O(n^2 ),辅助二维数组dp与递归栈的空间最大为O(n^2 )
拓展知识:动态规划
动态规划基本概念
动态规划(Dynamic Programming,简称DP)算法是一种解决复杂问题的算法设计和优化技术,常用于解决具有重叠子问题性质和最优子结构性质的问题。它的核心思想是将一个大问题分解成一系列相互重叠的子问题,然后将子问题的解存储起来,以避免重复计算,从而节省时间。
动态规划算法通常包括以下关键步骤:
-
定义子问题:将原问题分解成若干个子问题,并明确定义每个子问题的输入和输出。
-
构建状态转移方程:确定每个子问题与其他子问题之间的关系,即如何通过已解决的子问题来解决当前子问题。这通常通过递归或迭代方式建立状态转移方程。
-
初始化:初始化基本情况,通常是问题规模较小或无法再分时的边界情况。
-
自底向上求解或使用备忘录法:根据状态转移方程,从最小的子问题开始解决,逐步构建出更大规模的问题的解。可以使用自底向上的迭代方法或备忘录法来避免重复计算。
-
返回结果:根据状态转移方程求解出原问题的解。
动态规划广泛应用于各种领域,包括算法设计、优化问题、路径规划、序列比对、字符串处理、游戏策略等。经典的动态规划问题包括斐波那契数列、背包问题、最长公共子序列、最短路径问题。
动态规划的优点是可以显著减少重复计算,提高效率,但其缺点是需要合理定义子问题和状态转移方程,有时需要额外的内存空间来存储中间结果。因此,在解决问题时,需要仔细分析问题的性质,确定是否适合使用动态规划算法。
动态规划、递归、分治的区别
下面是动态规划、递归和分治这三种算法的相同点和不同点的表格展示:
| 特点 | 动态规划 | 递归 | 分治 |
|---|---|---|---|
| 求解方式 | 自底向上 | 自顶向下 | 分而治之 |
| 重复计算处理 | 避免重复计算,通过存储子问题的解来提高效率 | 可能重复计算相同的子问题 | 分解问题并独立处理子问题 |
| 时间复杂度 | 通常具有较低的时间复杂度 | 可能具有较高的时间复杂度 | 通常具有中等的时间复杂度 |
| 适用性 | 适用于具有重叠子问题性质和最优子结构性质的问题 | 适用于结构天然呈递归性质的问题 | 适用于问题可以分解为独立的子问题 |
| 经典问题举例 | 背包问题、最短路径问题、斐波那契数列等 | 树形结构的问题、图遍历等 | 快速排序、归并排序等 |
| 记忆化/缓存 | 通过存储中间结果,具有记忆化的特点 | 可以使用记忆化技巧来减少重复计算 | 分治通常不涉及记忆化 |
| 稳定性 | 具有稳定性,不受输入数据顺序影响 | 可能受输入数据顺序影响 | 通常具有稳定性,不受输入数据顺序影响 |
这个表格概括了动态规划、递归和分治算法之间的一些主要相同点和不同点。需要注意的是,这些算法的选择取决于具体问题的性质和要求,有时候也可以根据问题的特点将它们结合使用,以获得更好的性能和效果。
高频算法题归类
适用于这些算法思想的题目
动态规划处理的高频算法题
动态规划是一个非常强大的算法技巧,适用于解决各种高频的算法问题。以下是一些使用动态规划解决的常见高频算法题目:
-
斐波那契数列问题:计算斐波那契数列的第n个数,可以使用动态规划来避免指数级的重复计算。
-
背包问题:如 0-1 背包问题、完全背包问题、多重背包问题等,动态规划可用于优化资源分配问题。
-
最长公共子序列问题:寻找两个字符串的最长公共子序列,动态规划可用于解决字符串匹配和相似性比较问题。
-
最长递增子序列问题:寻找一个数组中最长的递增子序列,常用于优化问题和排序问题。
-
最短路径问题:如 Dijkstra 算法、Floyd-Warshall 算法,用于在图中找到最短路径或最短距离。
6. 编辑距离问题:计算两个字符串之间的最小编辑操作数,如插入、删除和替换操作。
7. 股票买卖问题:寻找股票价格数组中的最佳买卖时机,以获得最大的利润。
-
子集和问题:确定给定集合中是否存在一个子集,其元素之和等于特定目标值。
-
矩阵链乘法问题:在给定一组矩阵的情况下,确定它们相乘的最佳顺序以最小化乘法运算的次数。
-
字符串匹配问题:如正则表达式匹配、通配符匹配等,用于模式匹配和文本搜索。
这些问题只是动态规划可以解决的众多示例之一。动态规划的思想可以应用于各种优化和最优化问题,它的关键是将问题分解成子问题并找到适当的状态转移规则。因此,当你面对一个复杂的问题时,考虑是否可以使用动态规划来提高问题求解的效率和准确性。
分治算法处理的高频算法题
分治算法是一种重要的算法技巧,适用于解决各种高频的算法问题,特别是分而治之的思想。以下是一些使用分治算法解决的常见高频算法题目:
-
归并排序:分治算法的经典示例之一,用于将一个大数组分割成较小的子数组,排序子数组,然后将它们合并以得到有序数组。
-
快速排序:另一种基于分治思想的排序算法,通过选择一个基准元素,将数组划分成两个子数组,然后递归地对子数组进行排序。
-
连续子数组的最大和:给定一个整数数组,查找具有最大和的连续子数组。分治算法可以用于高效解决这个问题。
-
求解最近点对问题:给定一个包含多个点的平面,找到最接近的一对点。该问题可以通过分治算法以较低的时间复杂度解决。
-
矩阵乘法:分治算法可以用于将矩阵分割成子矩阵,然后递归地进行矩阵乘法操作,以减少计算次数。
-
大整数乘法:用于计算两个大整数的乘积,分治算法可以用于将大整数分解为较小的整数,并递归地计算它们的乘积。
-
众数问题:查找数组中出现次数超过一半的元素,分治算法可以在线性时间内解决这个问题。
-
合并K个有序链表:将K个有序链表合并为一个有序链表,分治算法可以用于高效解决这个问题。
-
寻找第K大/小的元素:在一个未排序的数组中找到第K大或第K小的元素,分治算法可以用于解决这个问题。
-
求解凸多边形的最小包围矩形:给定一个凸多边形,找到包围它的最小矩形。分治算法可用于高效计算最小包围矩形。
这些问题只是分治算法可以解决的众多示例之一。分治算法的关键思想是将问题分解为相互独立的子问题,然后将子问题的解合并以得到原问题的解。当你面对一个需要分而治之的问题时,考虑是否可以使用分治算法来提高问题求解的效率和准确性。
递归算法处理的高频算法题
递归算法是一种常见且强大的算法技巧,适用于解决各种高频的算法问题。以下是一些使用递归算法解决的常见高频算法题目:
-
二叉树遍历:包括前序遍历、中序遍历、后序遍历等,用于访问和处理二叉树的节点。
-
分解问题:许多问题可以通过将它们分解为更小的相似子问题来解决,例如斐波那契数列、汉诺塔问题等。
-
递归的数据结构:如链表、树、图等数据结构的处理通常使用递归来实现。
-
组合和排列问题:生成所有可能的组合或排列,如子集生成、排列生成等。
-
回溯算法:解决一些组合优化问题,如八皇后问题、数独问题等。
-
图的遍历:深度优先搜索(DFS)和广度优先搜索(BFS)是递归的常见应用,用于解决图相关的问题。
-
递归的搜索和查找:二分查找、树的搜索、图的最短路径等问题可以使用递归算法解决。
-
分治算法:分治算法的核心思想就是递归,如归并排序、快速排序等。
-
递归背包问题:解决背包问题的变种,如动态规划中的背包问题。
-
字符串处理:字符串匹配、编辑距离、正则表达式匹配等问题通常可以使用递归来解决。
这些问题只是递归算法可以解决的众多示例之一。递归算法的关键思想是将问题分解为更小的相似问题,并通过递归调用自身来解决这些子问题。当你面对一个需要不断分解问题的情况时,考虑是否可以使用递归来解决,但需要小心避免无限递归,确保有适当的终止条件。