论文题目(Title):Context-Tuning: Learning Contextualized Prompts for Natural Language Generation
研究问题(Question):自然语言生成,生成长文本。
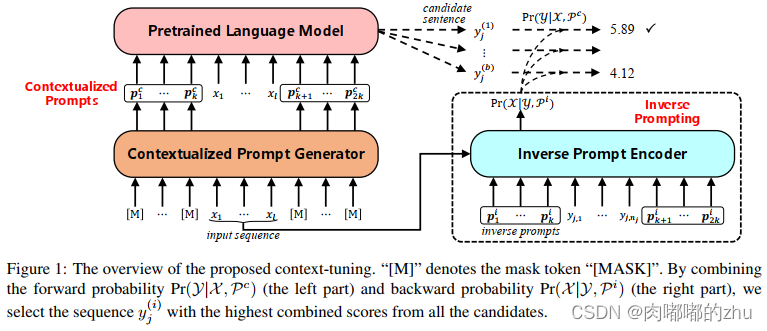
研究动机(Motivation):在现有的研究中,一般的提示方法通常独立于输入,缺乏对输入语义的充分考虑。该研究将输入进行掩码,从预训练模型中得到相关的知识,作为提示信息。
主要贡献(Contribution):
1. 作者指出他是第一个将输入相关信息编码为文本生成的连续提示的人。该上下文调优方法可以根据特定的输入文本引出相关知识,增强生成文本与输入文本之间的相关性。
2. 另外提出反提示,从输出到输入的逆方式增强相关性。
3. 将该方法与几个基线模型进行比较,以评估四种自然语言生成任务。大量的实验证明了上下文调优方法的有效性。逆提示基于连续提示,可以在微调过程中灵活优化。
研究思路(Idea):首先,根据输入文本派生提示,以从PLMs中提取有用的知识进行生成。其次,使用连续逆提示来改进自然语言生成的过程,通过建模一个从输出到输入的逆生成过程,使生成的文本与输入更相关。另外,使用轻量级上下文调优方法,在保持良好性能的同时只调优0.12%的参数。
研究方法(Method):
研究过程(Process):
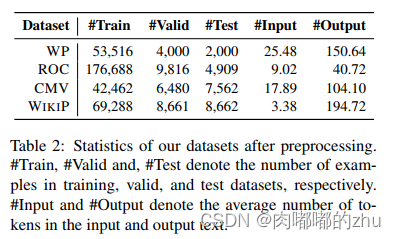
1.数据集(Dataset)
2.评估指标(Evaluation)BLEU、Distinct、Human Evaluation
3.实验结果(Result)
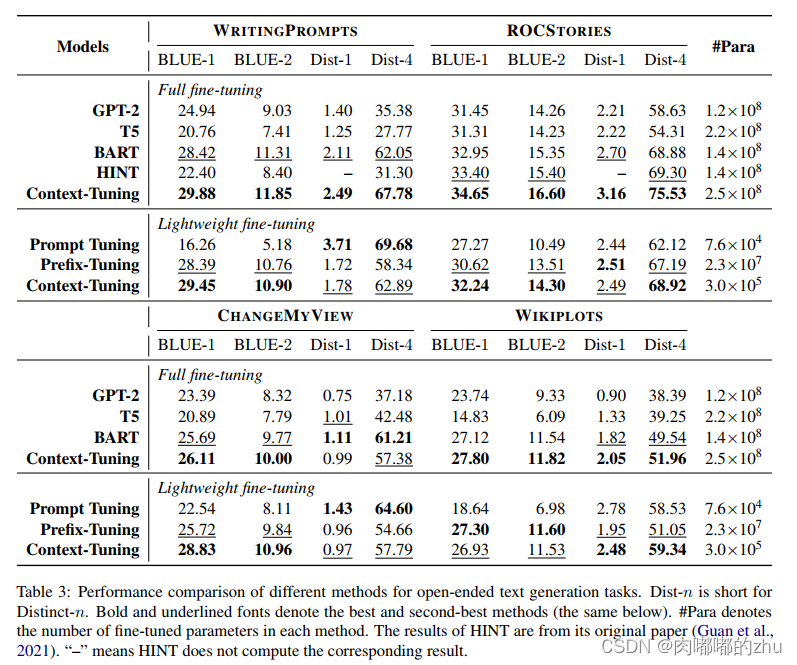
总结(Conclusion):发表于CCF B,利用输入mask,得到一些关于输入的相关知识作为提示信息,是具有一定的新颖性。现有的文本生成提示信息一般将情感信息考虑进行,作者也提到后续考虑。但就其mask输入来说,可能给输入带来一定的噪声,mask获得的信息可能是有误的,那也就导致提示的方向是错误,可设法在其中进行信息判断,有用的信息进行提示,无用信息则筛除。这可能也就是实验BLEU和多样性值低的原因。